۱۲
دیدگاه
نظر

آموزش Scikit-Learn در پایتون
سرفصلهای مقاله
- نصب Scikit-Learn
- ویژگیهای Scikit-Learn
- فرایند مدل سازی در Scikit-Learn
- پیش پردازش داده Preprocessing the Data:
- پیاده سازی SVM در Scikit-Learn
- جمع بندی
Scikit Learn از کتابخانههای متن باز، مفید، پرکاربرد و قدرتمند در زبان برنامه نویسی پایتون است که برای اهداف یادگیری ماشین به کار میرود. این کتابخانه ابزارهای کاربردی زیادی به منظور یادگیری ماشین و مدل سازی آماری دادهها همچون طبقه بندی (classification)، رگرسیون، خوشه بندی و کاهش ابعاد فراهم میکند. این کتابخانه که به طور عمده توسط زبان پایتون ارائه شده، بر پایه ی کتابخانههای Numpy ،Scipy و Matplotlib طراحی شده است.
در این مقاله به آموزش کتابخانه ی Scikit-Learn میپردازیم. آموزش Scikit-Learn میتواند برای علاقه مندان به یادگیری علم داده بسیار مفید باشد. همچنین نحوه ی پیاده سازی SVM در Scikit-Learn را میبینیم. برای یادگیری آموزش Scikit-Learn، شما نیاز دارید تا با برنامه نویسی Python و کتابخانههای پرکاربرد علم داده بر مبنای این زبان همچون Numpy، Pandas، Scipy و Matplotlib آشنایی داشته باشید که هر کدام از این کتابخانهها پیش از این در مجموعه مقالات آموزشی علم داده، مورد بررسی قرار گرفته اند. شما با مطالعه ی این مقاله اطلاعات لازم را برای آشنایی و پیاده سازی الگوریتمهای یادگیری ماشین مورد نیاز خود به دست میآورید؛ با ما همراه باشید.
نصب Scikit-Learn
به منظور پیاده سازی الگوریتمها و کدها در Scikit-Learn نیاز است تا موارد زیر را بر روی کامپیوتر خود نصب داشته باشید:
- Python (>=3.5)
- NumPy (>= 1.11.0)
- Scipy (>= 0.17.0)
- Joblib (>= 0.11)
- Matplotlib : به منظور افزودن قابلیت رسم نمودار و اشکال.
- Pandas (>= 0.18.0) : جهت استفاده در مثالها و کدهایی که از ساختار داده ی پانداس بهره میبرند.
اگر Numpy و Scipy را نصب کرده اید، دو روش زیر آسانترین راه برای نصب Scikit-Learn هستند:
- استفاده از دستور Pip:
در محیط خط فرمان Command به شکل زیر، Scikit را نصب کنید:
pip install -U scikit-learn- استفاده از Conda:
به کمک دستور زیر میتوان Scikit-Learn را در Conda نصب کرد:
conda install scikit-learnالبته شما میتوانید توزیعهای پایتونی مثل آناکوندا را نصب کنید و از آنجایی که پکیج هایی همچون Numpy، Scipy و Scikit-Learn در این توزیع موجود هستند، کدهای خود را اجرا نمایید.
ویژگیهای Scikit-Learn
علاوه بر کاربرد این کتابخانه در مواردی مانند بارگذاری، تغییر و دستکاری داده ها، Scikit-Learn در مدل سازی داده، تمرکز ویژه ای دارد. برخی از مدل سازیهای مشهور در این کتابخانه عبارتند از:
- الگوریتمهای یادگیری نظارت شده (Superuised Learning)
تقریبا تمامی الگویتمهای یادگیری نظارت شده معروف رگرسیون خطی، ماشین بردار پشتیبان (SUM)، درخت تصمیم گیری و... در این کتابخانه موجود هستند.
- الگوریتمهای یادگیری نظارت نشده (Unsuperuised Learning)
تمامی الگوریتمهای نظارت نشده همچون روشهای خوشه بندی، تحلیل فاکتوری، PCA، شبکههای عصبی نظارت نشده و... بخشی از کتابخانه ی Superuised Learning میباشند.
- اعتبارسنجی یا Cross-Validation
به منظور کنترل دقت مدل نظارتی بر روی دادههای تست، مورد استفاده قرار میگیرد.
- کاهش ابعاد و داده ها
به منظور کاهش ویژگیهای دادهها جهت خلاصه سازی، مصورسازی و نیز انتخاب ویژگی مورد استفاده قرار میگیرد.
- کاهش ابعاد داده ها
به منظور کاهش ویژگیهای دادهها جهت خلاصه سازی، مصورسازی و نیز انتخاب ویژگی مورد استفاده قرار میگیرد.
- روشهای گروه بندی Ensemble Methods
همان طور که از نامش پیداست، این روش برای ترکیب مدلهای یادگیری نظارت شده، به منظور پیش بینی برچسب دادههای تست به کار میرود.
- استخراج ویژگی Feature extraction
به منظور تعریف ویژگیهای جدید از روی ویژگیهای اصلی جهت استخراج دادههای مفید به کار میرود.
- انتخاب ویژگی یا Feature selection
روشی جهت انتخاب ویژگی برای ایجاد مدل هایی با دقت بالاتر یا افزونگی کمتر است.

فرایند مدل سازی در Scikit-Learn
در این قسمت به شرح فرایند مدل سازی در Scikit-Learn میپردازیم. مدل سازی در Scikit-Learn شامل مراحل بارگذاری داده، تقسیم داده، آموزش داده و تست آن است. در ادامه با جزییات بیشتری به شرح هر کدام از این مراحل میپردازیم.
بارگذاری داده Dataset Loading
ویژگی متغیرهای مربوط به داده ها، feature یا ویژگی نامیده میشوند. گاه به ویژگی، پیش بینی کننده (predictor)، ورودی (input) یا صفت (attribute) نیز میگویند.
ماتریس ویژگی: مجموعه ای از ویژگیها تحت شرایطی است که بیش از یک ویژگی دارد.
نام ویژگی: لیستی از نام ویژگی هاست.
پاسخ یا ویژگی برچسب: متغیر خروجی که به متغیرهای ویژگی وابسته است. که به آن هدف (target)، برچسب (label) یا خروجی (output) میگویند.
بردار پاسخ (Response Vector): بیانگر ستون پاسخ است. به طور کلی ما یک ستون پاسخ داریم.
نامهای هدف: Target Name
بیانگر مقادیری است که ستون پاسخ میتواند داشته باشد.
Scikit-Learn مجموعه دادههای نمونه ی محدودی همچون Iris و digit برای طبقه بندی (Classification) و قیمت خانه در Boston برای رگرسیون دارد.
در زیر مثالی برای بارگذاری مجموعه داده ی iris داریم:
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
print("Feature names:", feature_names)
print("Target names:", target_names)
print("\nFirst 10 rows of X:\n", X[:10])که خروجی آن به شکل زیر است:
Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] Target names: ['setosa' 'versicolor' 'virginica'] First 10 rows of X: [ [5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] [5.4 3.9 1.7 0.4] [4.6 3.4 1.4 0.3] [5. 3.4 1.5 0.2] [4.4 2.9 1.4 0.2] [4.9 3.1 1.5 0.1] ]
تقسیم مجموعه داده (Splitting the data set)
برای کنترل دقت مدل استخراج شده، میتوان مجموعه داده را به دو قسمت تقسیم کرد: مجموعه ی آموزشی (training set) و مجموعه ی آزمایشی یا تست (testing set).
از داده ی آموزشی برای آموزش روش یادگیری ماشین و استخراج مدل آموزشی استفاده میشود. مدل استخراجی حاصل روی مجموعه ی تست اعمال میشود تا دقت مدل بررسی شود.
در کد زیر داده را به نسبت 70 به 30 تقسیم کرده ایم. یعنی 70 درصد داده ها، داده ی آموزشی در نظر گرفته شده اند و 30 درصد به دادههای تست اختصاص یافته اند.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 1
)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)که خروجی به شکل زیر است:
(105, 4) (45, 4) (105,) (45,)
همان طور که در کد بالا میبینید تابع ()train_test_split برای تقسیم مجموعه داده به کار گرفته میشود. آرگومانهای این تابع به شرح زیر هستند:
X ماتریس ویژگی و Y بردار پاسخ است.
Test_size بیانگر نسبت دادههای تست به کل مجموعه داده است. در مثال بالا، 0.3 از 150 سطر موجود برای X را به عنوان داده ی تست در نظر گرفتیم. پس 45 سطر X متعلق به داده ی تست و بقیه متعلق به دادههای آموزشی است.
Random_state: اگر مقدار این پارامتر را برابر هر عددی صحیحی در نظر بگیریم (فرقی نمیکند 1، 4، 42....) در آن صورت در هر مرحله ای که الگوریتم برای تولید مدل تکرار میشود، دادهها به نسبت مساوی با مرحله ی قبل به دادههای آموزشی و تست تقسیم میشوند. به طور مثال در هرمرحله به طور تصادفی 0.7 دادهها به داده ی آموزشی و 0.3 آن به داده ی تست اختصاص مییابد.
آموزش مدل
بعد از تقسیم داده ها، میتوانیم دادهها را برای یادگیری مدلهای پیش بینی به کار بگیریم.
همان طور که گفته شد، Scikit-Learn الگوریتمهای یادگیری ماشین گسترده ای دارد که رابط یا اینترفیس ثابتی برای مدل کردن، پیش بینی دقت و فراخوانی برای تمام الگوریتمها ارائه میدهد.
مثال زیر نحوه ی آموزش طبقه بندی KNN (نزدیکترین همسایه k) را توسط Scikit نمایش میدهد. (جزییات الگوریتم KNN در بخشهای بعدی شرح داده شده است)
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.4, random_state=1
)
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors = 3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Finding accuracy by comparing actual response values(y_test)with predicted response value(y_pred)
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)خروجی کد به شکل زیر است:
Accuracy: 0.9833333333333333 Predictions: ['versicolor', 'virginica']
پایداری مدل: Model Persistence
وقتی با اعمال الگوریتمی بر روی مجموعه دادههای آموزشی مدلی را استخراج میکنیم، انتظار داریم این مدل برای استفادههای آتی نیز پایدار بماند. از این رو مدل را چندین مرتبه بازآموزی (retrain) میکنیم. این کار را میتوان به کمک ویژگیهای dump و load از پکیج joblib انجام داد. مثال زیر را در نظر بگیرید که در آن مدل یادگرفته شده از مثال قبل (classifier_knn) را برای استفادههای آتی ذخیره میکنیم:
from sklearn.externals import joblib
joblib.dump(classifier_knn, 'iris_classifier_knn.joblib')قطعه کد بالا، مدل را در فایلی تحت عنوان iris_classifier_knn.joblib ذخیره میکند.
حال میتوان آبجکت ایجاد شده را با کمک دستور زیر دوباره بارگذاری کرد.
joblib.load('iris_classifier_knn.joblib')پیش پردازش داده Preprocessing the Data:
از آنجایی که در فرم خام دادهها با مقادیر زیادی داده سر و کار داریم، باید قبل از به کارگیری داده به عنوان ورودی الگوریتم یادگیری ماشین، آنها را آماده سازی کنیم و به داده هایی مناسب و معنی دار تبدیل کنیم. این فرایند، پیش پردازش دادهها نامیده میشود.
Scikit-Learn از پکیج preprocessing برای این منظور استفاده میکند. پکیج sklearn.preprocessing چندین تابع و کلاس تبدیل کننده ی رایج برای تبدیل بردار ویژگی و داده ی خام به دادههای قابل استفاده توسط تخمین گرها را فراهم میکند. به طور کلی، الگوریتمهای یادگیری با استفاده از استانداردسازی داده ها، میتوانند عملکرد بهتری داشته باشند. اگر برخی دادههای پرت در مجموعه داده وجود داشته باشد، مقیاس دهی دادهها (scaling) و استفاده از توابع تبدیل کننده ی قویتر مناسب است.
برای الگوریتمهای تخمین گر تعریف شده در مجموعه ی scikit-learn استانداردسازی مجموعه داده ، عمل رایج و مورد نیاز محسوب میشود. اگر مقادیر ویژگیهای ورودی الگوریتم تخمین گر شباهت زیادی به توزیع نرمال استاندارد داده (منظور از توزیع نرمال: داده هایی با توزیع گوسی با میانگین صفر و واریانس واحد) نداشته باشد، باعث میشود که تخمین گر رفتار خوب و خروجی مناسبی روی دادهها نداشته باشد.
در عمل، اکثراً شکل و نحوه ی توزیع دادهها را در نظر نمیگیریم و ابتدا مقدار میانگین دادهها را از آنها کم میکنیم و سپس حاصل را بر انحراف معیار تقسیم کرده و به این صورت دادهها را، متمرکز یا centralized میکنیم. به عنوان مثال بسیاری از عناصر مورد استفاده در تابع هدف الگوریتم یادگیری ماشین (مانند RBF Kernel در SVM) فرض میکنند که مرکز تمام ویژگیها حول صفر است و دارای پراکندگی و واریانس یکسان اند. اگر ویژگی دارای واریانس بزرگتر از سایرین باشد، ممکن است بر عملکرد تابع هدف مسلط شود و سبب شود تا تخمین گر به درستی از مقادیر سایر ویژگیها برای یادگیری خود استفاده نکند.
این پکیج تکنیکهای زیر را شامل میشود:
1. باینری کردن
این تکنیک پیش پردازش زمانی به کار میرود که میخواهیم مقادیر عددی را به مقادیر بولین (منطقی) تبدیل کنیم.
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
data_binarized = preprocessing.Binarizer(threshold=0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)پارامتر threshhold_value=0.5 برای این است که داده هایی با مقدار بزرگتر از 0.5 به 1 و مقدار کوچکتر یا مساوی 0.5 به صفر تبدیل شوند.
Binarized data: [ [ 1. 0. 1.] [ 0. 1. 1.] [ 0. 0. 1.] [ 1. 1. 0.] ]
2. حذف میانگین یا Mean Removal
این روش برای حذف میانگین دادهها از بردار ویژگی است که منجر به نرمال سازی ویژگیها با محدودیت صفر میشود.
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
#displaying the mean and the standard deviation of the input data
print("Mean =", input_data.mean(axis=0))
print("Stddeviation = ", input_data.std(axis=0))
#Removing the mean and the standard deviation of the input data
data_scaled = preprocessing.scale(input_data)
print("Mean_removed =", data_scaled.mean(axis=0))
print("Stddeviation_removed =", data_scaled.std(axis=0))خروجی کد بالا به شکل زیر است:
Mean = [ 1.75 -1.275 2.2 ] Stddeviation = [ 2.71431391 4.20022321 4.69414529] Mean_removed = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00] Stddeviation_removed = [ 1. 1. 1.]
3. مقیاس دهی یا scaling
تابع scale روشی سریع و راحت برای انجام عمل مقیاس دهی به کار میبرد. به کد زیر توجه کنید:
from sklearn import preprocessing
import numpy as np
X_train = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
X_scaled = preprocessing.scale(X_train)
X_scaledخروجی کد به شکل زیر است:
array([[ 0. ..., -1.22..., 1.33...], [ 1.22..., 0. ..., -0.26...], [-1.22..., 1.22..., -1.06...]])
داده ی مقیاس بندی شده ی حاصل، میانگین صفر و واریانس واحد دارد:
>>> X_scaled.mean(axis=0)
array([0., 0., 0.])
>>> X_scaled.std(axis=0)
array([1., 1., 1.])ماژول preprocessing کلاسی تحت عنوان stanardscaler دارد که حذف میانگین و تقسیم واریانس را بر روی دادههای آموزشی اجرا میکند و توسط transformer API خود امکان اعمال حذف همین مقدار میانگین و تقسیم همان واریانس محاسبه شده ی حاصل از دادههای آموزشی را بر روی دادههای تست فراهم میکند.
>>> scaler = preprocessing.StandardScaler().fit(X_train)
>>> scaler
StandardScaler()
>>> scaler.mean_
array([1. ..., 0. ..., 0.33...])
>>> scaler.scale_
array([0.81..., 0.81..., 1.24...])
>>> scaler.transform(X_train)
array([[ 0. ..., -1.22..., 1.33...],
[ 1.22..., 0. ..., -0.26...],
[-1.22..., 1.22..., -1.06...]])در زیر همین تبدیل را روی دادههای تست اعمال میکنیم:
>>> X_test = [[-1., 1., 0.]]
>>> scaler.transform(X_test)
array([[-2.44..., 1.22..., -0.26...]])اگر به هر دلیلی بخواهیم در کلاس standardscaler امکان حذف میانگین و یا تقسیم شدن داده به انحراف معیار را حذف کنیم، به ترتیب میتوانیم تنظیمات را به صورت with_mean=False و with_std=False اعمال کنیم.
یک روش استاندارد جایگزین مقیاس دهی به ویژگی ها، مقداردهی به آنها در بازه ی حداقلی و حداکثری (معمولاً بین 0 و 1) است. روش دیگر، تعیین حداکثر مقدار مطلق یک ویژگی به اندازه ی واحد است.
4. نرمال سازی
نرمال سازی بردار ویژگی برای این که ویژگیها در مقیاس یکسانی قرار گیرند به کار میآید. دو روش نرمال سازی داریم:
- نرمال سازی L1
این روش که به آن حداقل انحراف مطلق نیز میگویند، مقادیر ویژگیها را به گونه ای تغییر میدهد که مجموع مقادیر مطلق در هر سطر حداکثر 1 باقی بماند.
در مثال زیر اجرای نرمال سازی L1 را روی دادههای ورودی میبینیم:
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l1 = preprocessing.normalize(input_data, norm='l1')
print("\nL1 normalized data:\n", data_normalized_l1)خروجی حاصل به شکل زیر است:
L1 normalized data: [ [ 0.22105263 -0.2 0.57894737] [-0.2027027 0.32432432 0.47297297] [ 0.03571429 -0.56428571 0.4 ] [ 0.42142857 0.16428571 -0.41428571] ]
- نرمال سازی L2
این روش که حداقل مربعات نیز نامیده میشود، مقادیر را به گونه ای تغییر میدهد که مجموع مربعات در هر سطر حداکثر یک باقی بماند. به مثال زیر توجه کنید:
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l2 = preprocessing.normalize(input_data, norm='l2')
print("\nL1 normalized data:\n", data_normalized_l2)خروجی حاصل به شکل زیر است:
L2 normalized data: [ [ 0.33946114 -0.30713151 0.88906489] [-0.33325106 0.53320169 0.7775858 ] [ 0.05156558 -0.81473612 0.57753446] [ 0.68706914 0.26784051 -0.6754239 ] ]
پیاده سازی SVM در Scikit-Learn
ماشین بردار پشتیبان (Support Vector Machine (SVM از جمله متدهای قدرتمند طبقه بندی نظارت شده است. SVM در ابعاد بالا انعطاف پذیر است و در مسائل طبقه بندی به طور گسترده استفاده میشود. SVM از نظر مصرف حافظه کاراست؛ زیرا زیرمجموعه ای از نقاط آموزشی را برای توابع تصمیم گیری به کار میگیرد. مهمترین هدف SVM تقسیم مجموعه داده به تعدادی از کلاسها به منظور به دست آوردن ابرصفحه با بیشترین حاشیه (Maximum Marginal Hyperplane: MMH) است که در دو مرحله صورت میگیرد.
- ماشین بردار پشتیبان در ابتدا ابرصفحاتی را تولید میکند که نقاط را به شکل صحیح تقسیم میکند.
- سپس میان ابرصفحات آن ابرصفحه ای را برمی گزیند که نقاط را به بهترین شکل ممکن جدا میکند.
برخی ویژگیهای مهم در خصوص SVM به شرح زیر است:
- بردارهای پشتیبان (Support Vector): نقاطی هستند که به ابرصفحه نزدیک ترند. بردارهای پشتیبان در شناسایی خطوط جداساز کمک کننده هستند.
- ابرصفحه (Hyper Plane): صفحه ای که نقاط را به کلاس های مختلف تقسیم میکند.
- حاشیه (Margin): فاصله ی خالی میان نقاط مرزی دو کلاس یا همان بردارهای پشتیبان، را حاشیه یا لبه یا همان Margin گویند.
با توجه به شکل زیر درک بهتری از مفاهیم و تعاریف ارائه شده در بالا را به دست میآورید:
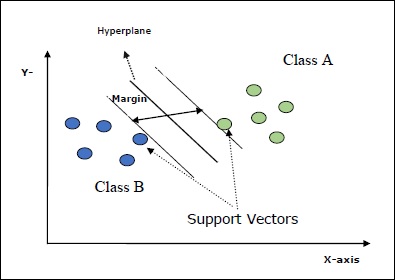
SVM در Scikit-Learn از هر دو نوع ورودی نقاط به صورت متراکم و پراکنده پشتیبانی میکند.
طبقه بندی با SVM
Scikit-learn سه کلاس با نامهای SVC، NuSVC و LinearSVC دارد که میتوانند طبقه بندی چند کلاسه (multivlass_class) را انجام دهند. برای نمونه طبقه بندی از طریق SVC را بررسی میکنیم.
SVC طبقه بندی چند کلاسه را از طریق مقایسه و طبقه بندی به صورت یک به یک (یک برچسب در مقایسه با سایر نمونه ها) انجام میدهد.
به مثال زیر توجه کنید:
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf.fit(X, y)همانند سایر طبقه بندی ها، SVC با دو آرایه مدل میشود:
- یک آرایه ی X که نگهدارنده ی نمونههای آموزشی است و در اندازه ی [n_samples, n_features] است.
- یک آرایه ی Y که مقادیر هدف یا target را نگهداری میکند. کلاس برچسب برای نمونههای آزمایشی است و در اندازه ی [n_samples] است.
توضیح پارامترهای به کار رفته در این کد به شکل زیر است:
- svc از کلاس svm است.
- Kernel از جنس string است، مقداری اختیاری است و پیش فرض آن ‘rbf’ است. این پارامتر تعیین کننده ی نوع kernel به کار گرفته شده در الگوریتم است. میتواند یکی از مقادیر ‘linear’، ‘poly’، ‘rbf’، ‘sigmoid’ و ‘precomputed’ را بگیرد که مقدار پیش فرض ‘rbf’ است.
- Gamma ضریب کرنل برای کرنلهای ‘rbf’، ‘poly’ و ‘sigmoid’ است و مقادیر {‘scale’,’auto’} یا اعشاری میگیرد.
- Shrinking مقداری Boolean است که اختیاری است و به طور پیش فرض True است.
در نهایت تخمین گر را بر روی ورودی X و ستون خروجی Yمدل میکنیم (با اعمال تابع fit)، و خروجی به شکل زیر است:
SVC(C = 1.0, cache_size = 200, class_weight = None, coef0 = 0.0, decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear', max_iter = -1, probability = False, random_state = None, shrinking = False, tol = 0.001, verbose = False)
حال میتوانیم به کمک صفت coef_ از این کلاس، وزن اختصاصی هر ویژگی دادههای ورودی را به دست آوریم که این ویژگی مختص کرنل خطی است:
SVCClf.coef_که خروجی به صورت زیر است:
array([[0.5, 0.5]])
می توانیم به کمک کد زیر مقدار برچسب برای ورودی دلخواه را به دست آوریم:
SVCClf.predict([[-0.5,-0.8]])خروجی کد به شکل زیر است:
array([1])
بردارهای پشتیبان را نیز میتوان به شکل زیر به دست آورد:
SVCClf.support_vectors_خروجی بردارهای پشتیبان به شکل زیر است:
array( [ [-1., -1.], [ 1., 1.] ] )
جمع بندی
در این مقاله به معرفی و آموزش کتابخانه ی Scikit-Learn و مفاهیم به کار رفته در آن پرداختیم. برای کار کردن با این کتابخانه لازم است تا با کتابخانههای Numpy، Pandas و matplotlib آشنایی داشته باشید و بتوانید با ساختار دادههای آنها کار کنید. این کتابخانه مدلهای زیادی را با تخمین گرهای خود فیت (fit) میکند و با استفاده از API امکان تست آن را روی دادههای تست فراهم میکند.
امیدوار هستیم که این مقاله برای شما مفید بوده باشد. خوشحال میشویم نظرات و تجربیات خود را با ما به اشتراک بگذارید.
اگر دوست داری به یک متخصص داده کاوی اطلاعات با زبان پایتون تبدیل شوی و با استفاده از آن در بزرگترین شرکتها مشغول به کار شوی، شرکت در دوره جامع آموزش علم داده با پایتون را پیشنهاد میکنیم.


۱۲ دیدگاه
۰۷ خرداد ۱۴۰۲، ۱۲:۲۳
نازنین کریمی مقدم
۲۸ خرداد ۱۴۰۲، ۰۶:۲۴
۰۹ مرداد ۱۴۰۱، ۱۲:۳۸
۰۱ دی ۱۴۰۰، ۲۱:۵۸
نازنین کریمی مقدم
۰۴ دی ۱۴۰۰، ۰۶:۴۱
hassan
۲۶ آبان ۱۴۰۰، ۱۳:۳۷
Nazanin KarimiMoghaddam
۲۹ آبان ۱۴۰۰، ۰۷:۱۶
shervin
۲۳ شهریور ۱۴۰۰، ۲۰:۲۰
نازنین کریمی مقدم
۲۳ شهریور ۱۴۰۰، ۲۲:۱۱
۲۷ دی ۱۴۰۱، ۱۹:۴۷
سارا
۲۵ مرداد ۱۴۰۰، ۱۸:۴۹
نازنین کریمی مقدم
۲۷ مرداد ۱۴۰۰، ۱۷:۲۱

دوره الفبای برنامه نویسی با هدف انتخاب زبان برنامه نویسی مناسب برای شما و پاسخگویی به سوالات متداول در شروع یادگیری موقتا رایگان شد: