۱۱
دیدگاه
نظر

آموزش TENSORFLOW
سرفصلهای مقاله
- TensorFlow چیست؟
- تنسور
- گراف محاسباتی
- تبادل داده میان گرهها و کارگرها:
- لزوم فشرده سازی داده ها:
- انواع TENSORدر فریم ورک TENSORFLOW
- ایجاد یک تنسور N بُعدی
- متغیرها در TENSORFLOW(Variables)
- Placeholder در TENSORFLOW
- مفهوم Session در TENSORFLOW
- اجرا روی پردازنده یا کارت گرافیکی
- آموزش مدل رگرسیون خطی
- نحوه ی کارکرد الگوریتم رگرسیون خطی
- چگونه یک رگرسیون خطی را با Tensorflow آموزش میدهیم
- رگرسیون خطی به کمک Pandas
- راه حل مبتنی بر Tensorflow
- نتیجه گیری
یادگیری ماشین، علم برنامه نویسی برای کامپیوتر است که کامپیوترها از طریق آن بتوانند با انواع مختلف داده سروکار داشته باشند و قادر به یادگیری از طریق این دادهها باشند. در گذشته برنامه نویسان تمامی الگوریتمها و فرمولهای ریاضی و آماری یادگیری ماشین را به صورت دستی مینوشتند. این طرز کدنویسی آن را به فرآیندی زمان بر، خسته کننده و ناکارآمد تبدیل میکند. اما امروزه توسط کتابخانههای مبتنی بر پایتون، فریم ورکها و ماژولهای بسیار قدرتمندی برای یادگیری ماشین ایجاد شده است، که کدنویسی را آسانتر و کارآمدتر از گذشته کرده است. در این مقاله به آموزش TensorFlow میپردازیم. سعی بر آن شده که با بیانی روان مسایل به طور صریح برای دانشجو تعریف شود و با مثال هایی ساده دانشجو قادر به درک نحوه ی کار با این فریم ورک و شروع انجام پروژههای خود گردد.
کتابخانههای پایتون در زمینه ی هوش مصنوعی عبارتند از:
Numpy
Scipy
Scikit-learn
Theano
TensorFlow
Keras
PyTorch
Pandas
Matplotlib
لزوم یادگیری مفاهیم پایه ای به منظور درک بهتر نحوه ی عملکرد و پیاده سازی الگوریتمهای یادگیری ماشین توسط این کتابخانهها بر کسی پوشیده نیست. با توجه به استقبال متخصصان در حوزه ی علم داده و یادگیری ماشین به کتابخانههای پایتون، ما در تیم تولید محتوای سون لرن قصد داریم تا شما را با همه ی این کتابخانهها آشنا کنیم.
TensorFlow چیست؟
TensorFlow یکی از کتابخانههای متن باز بسیار محبوب برای محاسبات عددی با کارایی بالاست که توسط تیم Google Brain در شرکت گوکل ساخته شده است و توسط تیمهای تحقیقاتی گوگل در محصولات مختلفی همچون شناسایی گفتار، جی میل، تصاویر گوگل، جستجو و ... استفاده میشود.TensorFlow از کتابخانههای مشهور یادگیری ماشین در GitHub میباشد. میتوان گفت گوگل تقریبا در همه ی برنامههای کاربردی اش از TensorFlow برای اجرای الگوریتمهای یادگیری ماشین استفاده میکند. به عنوان مثال، اگر از تصاویر گوگل یا جستجوی صوتی گوگل استفاده میکنید، به طور غیرمستقیم از مدل هایTensorFlow بهره میبرید، آنها روی خوشههای بزرگ سخت افزار گوگل کار میکنند و در کارهای ادراکی قدرتمنداند.
همان طور که از نام این محصول پیداست، TensorFlow فریم ورکی است که دادههای آن به صورت تنسور تعریف و اجرا میشوند. همین دلیل سبب میشود تا TensorFlow به یک فریم ورک محبوب برای آموزش و اجرای شبکههای عصبی عمیق در برنامههای کاربردی مبتنی بر هوش مصنوعی تبدیل شود و به صورت گسترده در تحقیقات مرتبط با یادگیری عمیق به کار گرفته شود. هدف اصلی مقاله ی آموزش TensorFlow معرفی مفاهیم تنسورفلو با بیانی ساده به در کنار ارائه ی مثال هایی کاربردی برای درک بهتر موضوع است و فرض بر این است که شما تا حدودی با پایتون آشنا هستید.
مولفه ی اصلی TensorFlow گراف محاسباتی شامل گرهها و یال هایی است که از این گرهها عبور میکنند و تنسورهایی است که ورودی و خروجی این گرهها هستند. یادگیری این مفاهیم به منظور درک بهتر نحوه ی کارکرد این کتابخانه ضروری است. در ادامه ی مقاله ی آموزش TensorFlow به معرفی هر کدام از این مفاهیم میپردازیم.
تنسور
در ادامه ی مقاله ی آموزش TensorFlow به تعریف مفهوم تنسور و گراف محاسباتی میپردازیم.
تنسور یک مفهوم هندسی است که در ریاضیات و فیزیک به منظور گسترش مفاهیم اسکالر (کمیت نرده ای که با عدد نمایش داده میشود)، بردارها و ماتریسها به ابعاد بالا تعریف میشود. آنچه که میبایست در یادگیری ماشین از تنسور بدانیم این است که تنسور در اینجا مفهومی هم چون ساختار داده برای تعریف دادهها و نحوه ی کار با آن هاست (مشابه نقشی که ساختار داده ی ماتریس در زبان برنامه نویسی متلب دارد.). تنسور این قابلیت را دارد که حجم بالایی از دادههای عددی را ذخیره کند و همین ویژگی این ساختار داده را برای الگوریتمهای یادگیری عمیق مناسب میسازد. برای درک بهتر تنسور را همچون آرایه ای از اعداد که در یک جدول چیده شده اند، در نظر بگیرید (شکل شماره ی 1).
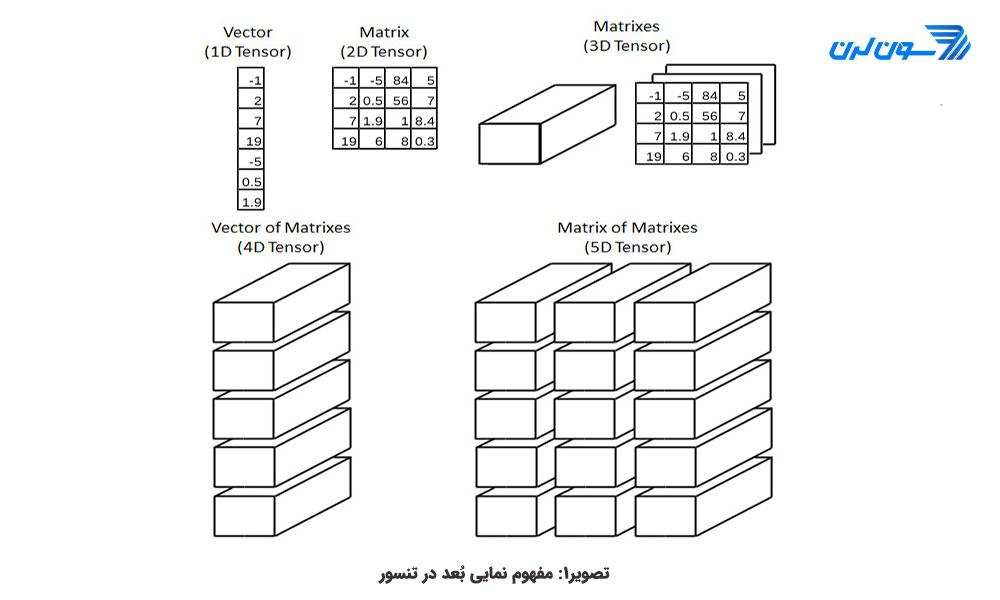
اعداد اسکالر یک تنسور با بُعد صفر، بردار تنسوری با بُعد یک، ماتریسها بُعد دو و ... . برای مثال در تنسور سه بُعدی با آدرس m*n*p میتوان به ماتریس mاُم و سطر n، ستون pاُم مراجعه کرد. برای درک بهتر، بیایید یک تمرین عملی داشته باشیم: (این تمرین توسط کتابخانه ی numpy و صرفاً برای توضیح مفهوم تنسور آورده بیان شده است.) فرض کنید که میخواهیم میانگین نمرات یک دانش آموز را در یک درس ذخیره کنیم. برای این کار از یک تنسور صفر بُعدی برای ذخیره ی این مقدار اسکالر استفاده میکنیم. (در کدهای زیر تابع ndim تعداد ابعاد را بر میگرداند):
import numpy as np
tensor_0D = np.array(5)
print("Average grade: \n{}".format(tensor_0D))
print("Tensor dimensions: \n{}".format(tensor_0D.ndim))Average grade: 5 Tensor dimensions: 0
حال فرض کنید میخواهیم نمرات سه درس یک دانشجو را ذخیره کنیم. از ساختار آرایه ای استفاده میکنیم که یک تنسور یک بُعدی است:
tensor_1D = np.array([4,6,8])
print("Subject grades: \n{}".format(tensor_1D))
print("Tensor dimensions: \n{}".format(tensor_0D.ndim))Subject grades: [4 6 8] Tensor dimensions: 1
اگر بخواهیم نمرات سه درس یک دانشجو را که در هر درس سه مرتبه امتحان داده ذخیره کنیم، چه ساختار داده ای داریم؟ یک ماتریس یا تنسور سه بُعدی.
# 2D Tensor (matrix)
tensor_2D = np.array([[0, 1, 1], # Subject 1
[2, 3, 3], # Subject 2
[1, 3, 2]]) # Subject 3
print("Exam grades are:\n{}".format(tensor_2D))
print("Subject 1:\n{}".format(tensor_2D[0]))
print("Subject 2:\n{}".format(tensor_2D[1]))
print("Subject 3:\n{}".format(tensor_2D[2]))
print("Tensor dimensions: \n{}".format(tensor_2D.ndim))Exam grades are: [[0 1 1] [2 3 3] [1 3 2]] Subject 1: [0 1 1] Subject 2: [2 3 3] Subject 3: [1 3 2] Tensor dimensions: 2
و سرانجام حالتی را در نظر بگیرید که نمرات سه امتحان از سه درس یک دانشجو را برای ترم یک و ترم دو بخواهیم داشته باشیم. همان طور که میبینید ابعاد دادهها در حال افزایش است:
tensor_3D = np.array([[[0, 1, 1], # First quarter
[2, 3, 3],
[1, 3, 2]],
[[1, 3, 2], # Second quarter
[2, 4, 2],
[0, 1, 1]]])
print("Exam grades per quarter are:\n{}".format(tensor_3D))
print("First quarter:\n{}".format(tensor_3D[0]))
print("Second quarter:\n{}".format(tensor_3D[1]))
print("Tensor dimensions: \n{}".format(tensor_3D.ndim)Exam grades per quarter are: [[[0 1 1] [2 3 3] [1 3 2]] [[1 3 2] [2 4 2] [0 1 1]]] First quarter: [[0 1 1] [2 3 3] [1 3 2]] Second quarter: [[1 3 2] [2 4 2] [0 1 1]] Tensor dimensions: 3
اگر دادههای مسأله ی قبل را برای سه دانش آموز متفاوت بخواهیم بخواهیم داشته باشیم:
tensor_4D = np.array([[[[0, 1, 1], # Jacob
[2, 3, 3],
[1, 3, 2]],
[[1, 3, 2],
[2, 4, 2],
[0, 1, 1]]],
[[[0, 3, 1], # Christian
[2, 4, 1],
[1, 3, 2]],
[[1, 1, 1],
[2, 3, 4],
[1, 3, 2]]],
[[[2, 2, 4], # Sofia
[2, 1, 3],
[0, 4, 2]],
[[2, 4, 1],
[2, 3, 0],
[1, 3, 3]]]])
print("The grades of each student are:\n{}".format(tensor_4D))
print("Jacob's grades:\n{}".format(tensor_4D[0]))
print("Christian's grades:\n{}".format(tensor_4D[1]))
print("Sofia's grades:\n{}".format(tensor_4D[2]))
print("Tensor dimensions: \n{}".format(tensor_4D.ndim))The grades of each student are: [[[[0 1 1] [2 3 3] [1 3 2]] [[1 3 2] [2 4 2] [0 1 1]]] [[[0 3 1] [2 4 1] [1 3 2]] [[1 1 1] [2 3 4] [1 3 2]]] [[[2 2 4] [2 1 3] [0 4 2]] [[2 4 1] [2 3 0] [1 3 3]]]] Jacob's grades: [[[0 1 1] [2 3 3] [1 3 2]] [[1 3 2] [2 4 2] [0 1 1]]] Christian's grades: [[[0 3 1] [2 4 1] [1 3 2]] [[1 1 1] [2 3 4] [1 3 2]]] Sofia's grades: [[[2 2 4] [2 1 3] [0 4 2]] [[2 4 1] [2 3 0] [1 3 3]]] Tensor dimensions: 4
همان طور که در کدها دیدید ابعاد دادهها میتواند تا مقادیر دلخواه افزایش یابد. میتوان گفت که در دنیای یادگیری عمیق که از ساختار داده ی تنسور استفاده میشود، معمولاً ابعاد تنسورها به شکل زیر است:
سریهای زمانی: تنسور سه بعدی
عکس: تنسور چهار بعدی
ویدیو: تنسور پنج بعدی
برای درک بهتر، فرض کنید 64 عکس رنگی دارید که هر عکس 224*224 پیکسل است. چون عکس، رنگی است هر پیکسل سه مقدار داده (RGB) دارد و در کل 64*3*224*224 داده داریم و یک تنسور چهار بُعدی.

گراف محاسباتی
گراف محاسباتی یک گراف بدون دور است. هر گره در گراف نشان دهنده ی یک عملیات مانند جمع، ضرب و ... است و هر عملیات منجر به تشکیل یک تنسور جدید میشود. شکل 2 یک گراف محاسباتی ساده را نشان میدهد.
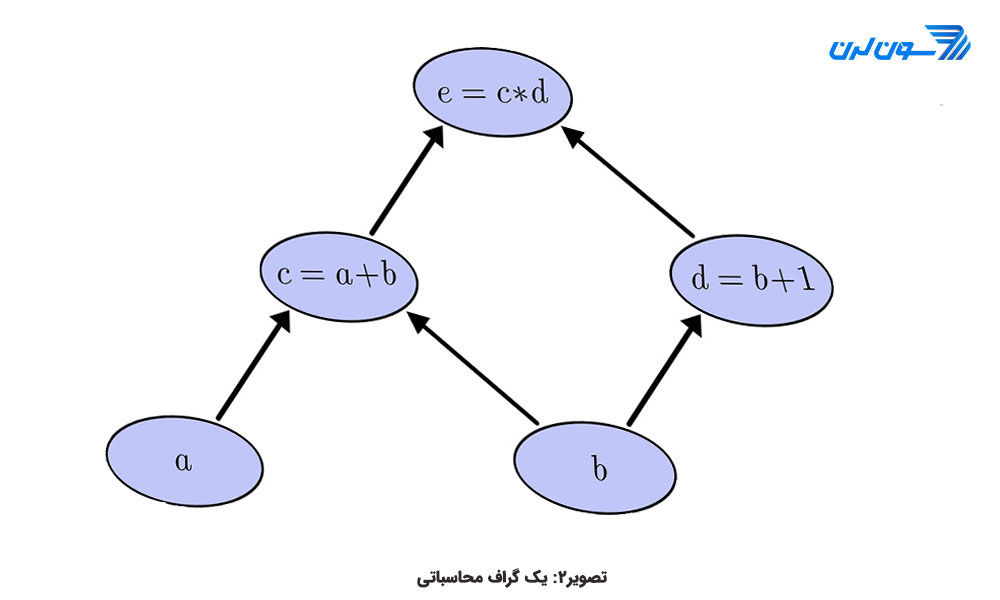
یک گراف محاسباتی دارای ویژگیهای زیر است:
رئوس برگ ( گره هایی که هیچ فرزندی ندارند، به عبارتی یال ورودی ندارند) همیشه تنسور هستند. بدین معنی که یک عملیات هرگز نمیتواند در ابتدای نمودار گراف رخ دهد، در نتیجه هر عملیاتی در گراف باید تنسور یا تنسورهایی را به عنوان ورودی بپذیرد و تنسور(هایی) را به عنوان خروجی تولید کند.
گراف محاسباتی میتواند یک عملیات پیچیده را در یک ترتیب سلسله مراتبی نشان دهد. عبارت e=c*d را میتوان با جای گذاری c=a+b و d=b+1 به فرم زیر نوشت:
(e=(a+b) * (b+1
پیمایش نمودار به ترتیب معکوس منجر به شکل گیری زیرعباراتی است که برای ساخت عبارت نهایی با هم ترکیب شده اند.
در پیمایش نمودار رو به جلو، هر گره وابسته به نتیجه ی گرههای ماقبل خود است. یعنی e وابسته به c و d وابسته به b، c وابسته به a و b است.
عملیات در گرههای هم سطح، مستقل از یکدیگر است. این یکی از ویژگیهای مهم گراف محاسباتی است. وقتی یک گراف به فرم شکل دو میسازیم، طبیعی است که گرهها در همان سطح به عنوان مثال گرههای c و d از یکدیگر مستقل باشند. این به این معنی است که بیش از ارزیابی d ، نیازی به دانستن مقدار گره c باشد. بنابراین میتوان عملیات این گرههای مستقل را به صورت موازی انجام داد و اجرا کرد.
اجرای موازی در گرافهای محاسباتی:
همان طور که در پاراگراف قبل اشاره شد، قابلیت اجرای موازی در گرههای موجود در یک سطح این امکان را فراهم میآورد تا عملیاتی بدون نیاز به نتایج همدیگر به صورت همزمان اجرا شوند. الگوریتمهای موجود در کتابخانه ی TensorFlow، از این ویژگی بسیار بهره برده اند.
اجرای توزیع شده یا غیرمتمرکز
TensorFlow این امکان را به کاربران خود میدهد تا از ابزار محاسبات موازی برای اجرای سریع عملیات استفاده کنند. گرهها یا عملیات محاسباتی به طور خودکار برای اجرای محاسبات موازی تنظیم میشوند. همه ی این کارها به طور داخلی اتفاق میافتد، به طور مثال در گراف بالا عملیات c میتواند بر روی CPU انجام شود و عملیات d بر روی GPU. شکل سه دو چشم انداز اجرای توزیع شده را نشان میدهد:
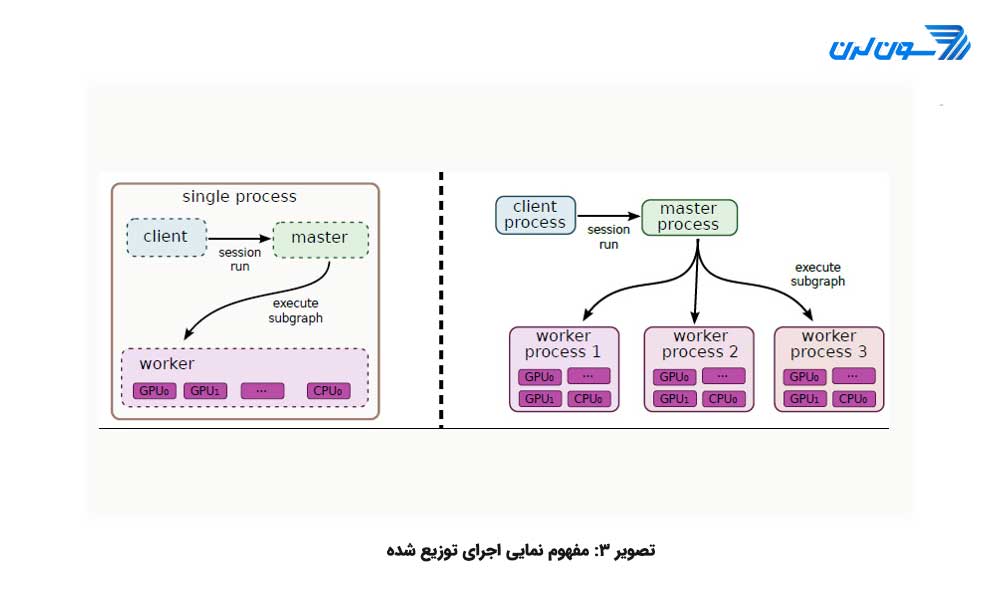
قسمت چپ در تصویر، یک اجرا از سیستم توزیع شده ی منفرد است که در آن تنها یک نشست منفرد (session) (session یا نشست مفهومی در TensorFlow است که در خلال آن به متغیرهای یک گراف محاسباتی فضای حافظه اختصاص داده شده و متغیرها در طول آن نشست، شناخته شده اند.) یک کارگر (worker) منفرد ایجاد میکند و کارگر مسئول زمان بندی وظایف (Task Scheduling) بر روی دستگاههای مختلف است.
در مورد قسمت سمت راست تصویر چندین کارگر وجود دارد که این کارگرها میتوانند ماشینهای یکسان یا متفاوتی باشند. هر کارگر متناسب با محیط خود کار میکند یعنی، کارگر پروسس 1، روی ماشین مجزایی کار میکند و عملیات را روی تمامی منابع تحت اختیار خود زمان بندی و تقسیم میکند.
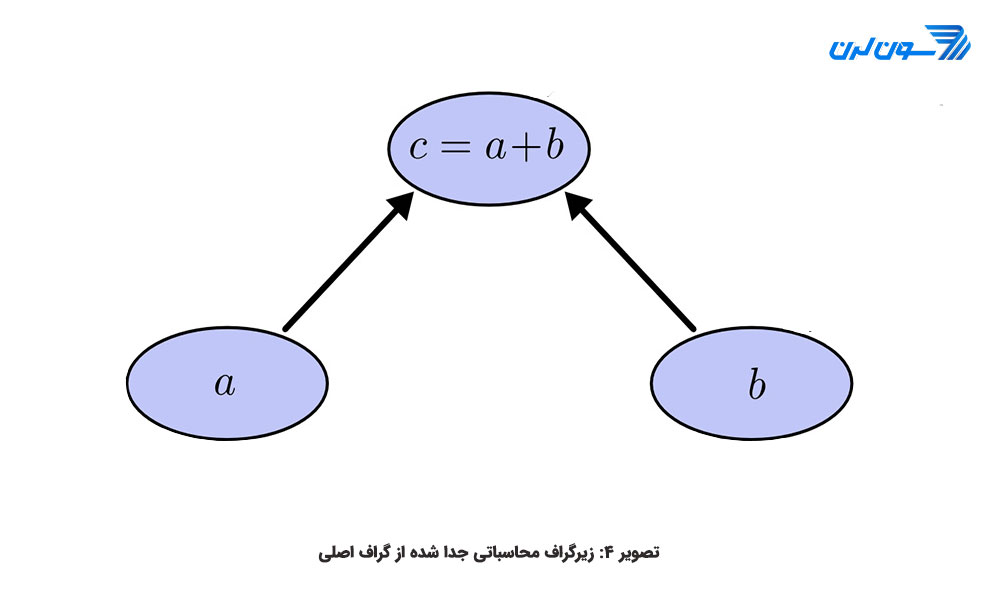
زیرگرافهای محاسباتی:
زیرگراف در اصل یک گراف محاسباتی است که خود بخشی از یک گراف اصلی است. به طور مثال در شکل چهار یک زیرگراف محاسباتی میبینید که بخشی از گراف اصلی است. میتوان گفت یک زیرگراف بیانگر یک زیرعبارت است، یعنی c یک زیرعبارت از e است. همچنین مطابق ویژگی آخر بیان شده برای گرافهای محاسباتی، زیر گرافهای موجود در سطح یکسان از یکدیگر مستقل اند و میتوانند به صورت موازی اجرا شوند و این منجر به افزایش بهره وری و سرعت اجرا خواهدبود.
تبادل داده میان گرهها و کارگرها:
TensorFlow عملیات خود را در دستگاههای مختلفی که توسط کارگران اداره میشود، توزیع میکند. دادهها میان دستگاهها به فرم تنسور رد و بدل میشوند. به طور مثال در گراف بالا که e=c*d است، c پس از محاسبه به فرم تنسور درآمده و به گره در سطح بالاتر منتقل میشود. البته در حین انتقال دادهها تأخیر رخ میدهد که این تأخیر به اندازه ی تنسور وابسته است.
لزوم فشرده سازی داده ها:
تا اینجا فهمیدیم که ساختار داده ی میان گرههای گراف محاسباتی به صورت تنسور است. تنسورها میان گرهها با تأخیر جابجا میشوند و مقدار این تأخیر میتواند به ابعاد و اندازه ی تنسور و همچنین ویژگیهای دستگاههای اجرایی گرهها وابسته باشد. یکی از ایدههای اصلی جهت فشرده سازی کاهش اندازه ی تنسور روش Lossy است. فشرده سازی Lossy اندازه و ابعاد داده را کاهش میدهد و به مقدار ابعاد توجه نمیکند. به این معنی که ممکن است درخلال فشرده سازی مقدار آن نادرست و یا غیر دقیق شود. البته در یک عدد اعشار 32 بیتی میدانیم که بیتهای کم ارزش تأثیر چندانی ندارند. پس تغییر و یا حذف آنها باعث تغییر چندانی در نتیجه ی نهایی نمیشود؛ اما این حذف باعث کاهش حجم دادهها به صورت مؤثر میشود.
تا اینجا به تعریف مفاهیم TensorFlow و آن دسته از ویژگی هایی پرداختیم که این کتابخانه را به زبان محبوب برای متخصصان هوش مصنوعی تبدیل کرده است:
TensorFlow از ساختار داده ی تنسور برای انجام عملیات استفاده میکند.
در TensorFlow، ابتدا عملیاتی که میبایست انجام شود، تعریف (ایجاد گراف محاسباتی) و سپس اجرا میشود. این عمل باعث میشود که فرآیند به صورت بهینه اجرا شود و زمان محاسبات به طور قابل ملاحظه ای کاهش یابد.
TensorFlow کدها را قادر میسازد تا به صورت موازی روی یک یا تعداد بیشتری CPU یا GPU اجرا شود.
موارد بیان شده را میتوان به شکل زیر نیز تعریف کرد:
TF.Graph: بیانگر مجموعه ای از عملیات انجام یافته تحت عنوان Tf.Operation است. هر گره ای از گراف نشان دهنده ی اجرای عملیاتی بر روی TENSORها است.
TF.Operation: مجموعه ی عملیات اصلی که برای اجرای الگوریتم تعریف کرده ایم.
TF.Tensor: ساختار داده ای که به عنوان ورودی تعریف میشود و یا نتایج در آن ذخیره میشوند.
در ادامه ی مقاله ی آموزش TensorFlow با محیط TensorFlow به صورت عملی آشنا خواهیم شد و با بررسی مثالهای بیشتر به یادگیری بهتر این فریم ورک کمک خواهیم کرد.
TENSORFLOW قابلیت پشتیبانی اجرا بر روی چندین CPU و GPU را به طور موازی دارد. همین اجرای غیرمتمرکز بر روی دستگاهها منجر به افزایش سرعت اجرای الگوریتمهای یادگیری مانند یادگیری عمیق خواهد شد و دیگر نیاز نیست زمان طولانی بر روی آن صرف شود. برای کاربران ویندوز، TENSORFLOW دو نسخه ی مختلف تدارک دیده است:
TENSORFLOW با قابلیت پشتیبانی از فقط CPU: اگر کامپیوتر شما روی پردازندههای گرافیکی NVIDIA اجرا نمیشود، تنها میتوانید از این گزینه برای نصب استفاده کنید.
TENSORFLOW با قابلیت پشتیبانی از GPU: برای محاسبات سریعتر میتوانید از این نسخه ی TENSORFLOW استفاده کنید. این نسخه در صورت نیاز به ظرفیت محاسباتی قوی کاربرد دارد.
فریم ورک TENSORFLOW روی سیستم عاملهای مختلف قابلیتهای متفاوت دارد. بهتر است برای درک بهتر این موضوع و نصب متناسب با سیستم خود به سایت TENSORFLOW مراجعه کرده و نسخه ی متناسب با دستگاه خود را نصب و اجرا کنید.
انواع TENSORدر فریم ورک TENSORFLOW
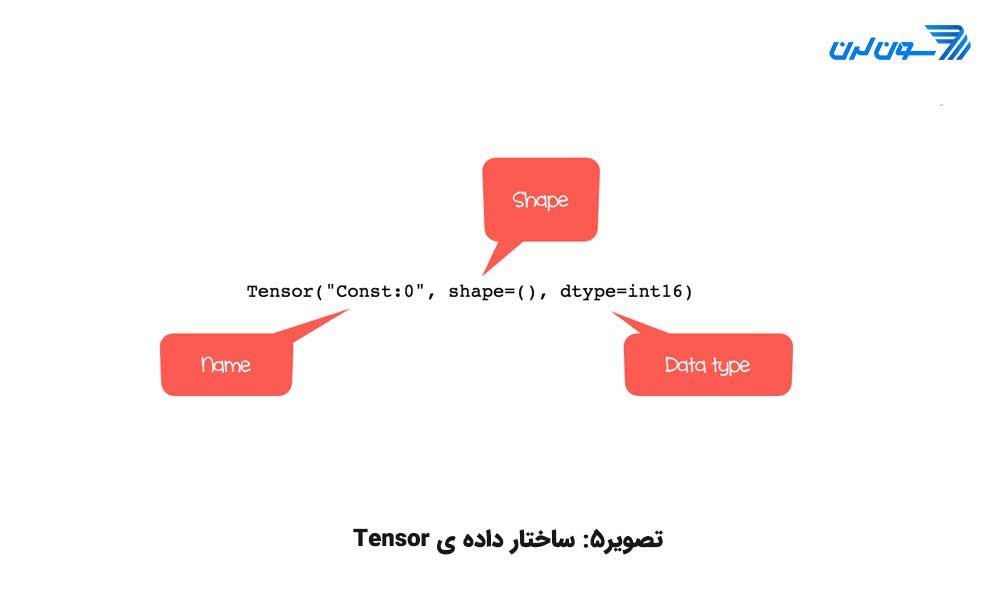
تمام محاسبات در TENSORFLOW روی یک یا چند TENSOR انجام میشود. هر TENSOR یک شی با سه ویژگی است:
برچسب منحصر بفرد (name)
بُعد (shape)
نوع داده (dtype)
چهار نوع TENSOR که میتوان ایجاد کرد که ما سه مورد اول را در مقاله ی آموزش TensorFlow شرح داده ایم:
Variable
Constant
Placeholder
Sparsetensor
ایجاد یک تنسور N بُعدی
یک روش برای ساخت یک TENSOR استفاده از ()tf.constant است. نحوه ی تعریف و توضیحات را در زیر ببینید:
tf.constant(value, dtype, name = "")
arguments:
"value": Value of n dimension to define the tensor. Optional
"dtype": Define the type of data:
- `tf.string`: String variable
- `tf.float32`: Float variable
- `tf.int16`: Integer variable
"name": Name of the tensor. Optional. By default: `Const_1:0`
برای ساخت یک TENSOR صفر بُعدی (نرده ای، اسکالر) به شکل زیر عمل میکنیم. البته لازم به یادآوری است که برای استفاده از کتابخانه ی TENSORFLOW دستور import tensorflow as tf را پیش از نوشتن قطعه کدها در این محیط مینویسیم.:
import tensorflow as tf
## rank 0
# Default name
r1 = tf.constant(1, tf.int16)
print(r1)Tensor("Const:0", shape=(), dtype=int16)
TENSOR یک بُعدی به شکل زیر تعریف میشود:
## Rank1
r1_vector = tf.constant([1,3,5], tf.int16)
print(r1_vector)
r2_boolean = tf.constant([True, True, False], tf.bool)
print(r2_boolean)Tensor("Const_3:0", shape=(3,), dtype=int16) Tensor("Const_4:0", shape=(3,), dtype=bool)
در TENSORیک بُعدی shape شامل یک مقدار است. برای TENSOR دو بُعدی بایستی بعد هر سطر از داده را در یک براکت قرار داد و یک براکت باز و بسته، بیش از حالت تک بُعدی به داده افزود. مثال زیر را ببینید:
## Rank 2
r2_matrix = tf.constant([ [1, 2],
[3, 4] ],tf.int16)
print(r2_matrix)Tensor("Const_5:0", shape=(2, 2), dtype=int16)
خروجی ماتریس شامل دو سطر و دو ستون است که با مقادیر 1، 2، 3، 4 پر شده است.
برای نمایش سه بُعد باید یک سطح دیگر از براکت را افزود. مثال زیر را ببینید:
## Rank 3
r3_matrix = tf.constant([ [[1, 2],
[3, 4],
[5, 6]] ], tf.int16)
print(r3_matrix)Tensor("Const_6:0", shape=(1, 3, 2), dtype=int16)
این ماتریس سه سطر و دو ستون دارد. میتوان یک TENSOR یک بُعدی (1D) با 10 عنصر ایجاد کردکه با صفر پر شده باشد (تابع ()tf.zeros).
# Create a vector of 0
print(tf.zeros(10))Tensor("zeros:0", shape=(10,), dtype=float32)
دستور بعدی ماتریسی با ابعاد 10*10 که با 1 پر شده را ایجاد میکند (تابع ()tf.ones).
# Create a vector of 1
print(tf.ones([10, 10]))Tensor("ones:0", shape=(10, 10), dtype=float32)
ماتریس m_shape را با سه سطر و دو ستون که با اعداد 10 تا 15 پر شده را، به شکل زیر تعریف میکنیم و با دستور shape. ابعاد را استخراج میکنیم:
# Shape of tensor
m_shape = tf.constant([ [10, 11],
[12, 13],
[14, 15] ]
)
m_shape.shape TensorShape([Dimension(3), Dimension(2)])
حال با دستورات زیر به ترتیب به تعداد سطر، ستون و کل اندازه ی ماتریس m_shape، تنسوری که با یک پر شده باشد، ایجاد میکنیم:
# Create a vector of ones with the same number of rows as m_shape
print(tf.ones(m_shape.shape[0]))
# Create a vector of ones with the same number of column as m_shape
print(tf.ones(m_shape.shape[1]))
# Create a vector of ones with the same number of m_shape.shape
print(tf.ones(m_shape.shape))
هر TENSOR تنها میتواند شامل دادههای هم نوع باشد. با دستور زیر نوع داده را میتوان برگرداند:
print(m_shape.dtype)<dtype: 'int32'>
همچنین نوع داده ی TENSORFLOW را با متد ()tf.cast میتوان تغییر داد. در قطعه کد زیر نوع داده ی اعشاری به صحیح تبدیل میشود.
# Change type of data
type_float = tf.constant(3.123456789, tf.float32)
type_int = tf.cast(type_float, dtype=tf.int32)
print(type_float.dtype)
print(type_int.dtype)
<dtype: 'float32'> <dtype: 'int32'>
اگر آرگومان مربوط به نوع داده حین ایجاد TENSOR، تعیین نشود، TENSORFLOW به طور خودکار نوع آن را تعریف میکند. به طور مثال اگر داده ی متن داشته باشید، نوع آن را string درنظر میگیرد.
متغیرها در TENSORFLOW(Variables)
نحوه ی تعریف مقادیر ثابت در TENSORFLOW را با ()tf.constant دیدید. در الگوریتمها دادهها معمولاً در مقادیر متغیر اند و برای تعریف آنها در TENSORFLOW از کلاس Variable استفاده میکنیم. این کلاس در گراف محاسباتی گره ای را مشخص میکند که مقادیر آن تغییر میکنند. برای ایجاد یک متغیر از متد ()tf.get_variable استفاده میکنیم. در ادامه ی مقاله ی آموزش TensorFlow نحوه ی بکارگیری و تعریف پارامترهای این متد را میبینید.
tf.get_variable(name = "", values, dtype, initializer)
argument:
"name = "" ": Name of the variable
"values": Dimension of the tensor
"dtype": Type of data. Optional
"initializer": How to initialize the tensor. Optional
If initializer is specified, there is no need to include the `values` as the shape of `initializer` is used.
به عنوان مثال، کد زیر متغیر دو بُعدی با دو مقدار تصادفی ایجاد میکند. به طور پیش فرض، TENSORFLOW یک مقدار تصادفی را برمی گرداند. نام متغیر را var گذاشتیم:
# Create a Variable
## Create 2 Randomized values
var = tf.get_variable("var", [1, 2])
print(var.shape)(1, 2)
در مثال بعدی متغیری با یک سطر و دو ستون ایجاد میکنیم. مقادیر ابتدایی این TENSORصفر است. برای مثال، زمانی که مدلی را آموزش میدهید باید مقادیر را برای محاسبه ی وزن ویژگیها مقداردهی اولیه کنید.
var_init_1 = tf.get_variable("var_init_1", [1, 2], dtype=tf.int32, initializer=tf.zeros_initializer)
print(var_init_1.shape) (1, 2)
می توانید مقادیر یک TENSOR ثابت را به یک متغیر اختصاص دهید. یک TENSOR با مقادیر ثابت با متد ()tf.constant ایجاد و به عنوان مقداردهی اولیه ی TENSOR متغیر از آن استفاده میکنیم. مقادیر اولیه ی متغیر 10، 20، 30 و 40 است و TENSOR متغیر یک ماتریس 2*2 است:
# Create a 2x2 matrixtensor_const = tf.constant([[10, 20],
[30, 40]])
# Initialize the first value of the tensor equals to tensor_const
var_init_2 = tf.get_variable("var_init_2", dtype=tf.int32, initializer=tensor_const)
print(var_init_2.shape)(2, 2)
Placeholder در TENSORFLOW
می دانیم که TENSORFLOW برای انجام محاسبات الگوریتمهای یادگیری ماشین طراحی شده است. ورودی الگوریتمهای یادگیری ماشین به طور کلی شامل سه نوع است: یکی آن ورودی هایی است که توسط کاربر الگوریتم در میزان مشخصی تعریف میشوند: مثل نرخ یادگیری، تعداد تکرار مراحل و ... . دسته ی بعدی متغیرهایی است که الگوریتم یادگیری ماشین آنها را برای بهینه سازی جواب نهایی میتواند تغییر دهد و در TENSORFLOW آنها را با عبارت tf.variable تعیین میکنند. در TENSORFLOW داده هایی که به الگوریتم به عنوان ورودی عملیاتی داده میشوند با tf.placeholder تعریف میشوند. برای درک بهتر موضوع placeholder را مانند عمل رزرو میز در یک رستوران در نظر بگیرید. فرض کنید که میزی را برای پنج نفر رزرو کرده اید (تخصیص فضا)، ولی درخصوص اینکه چه کسانی را همراه خود به رستوران ببرید، موضوعی اختیاری است (متغیری است که شما به ان مقدار اختصاص خواهید داد.). قاعده ی کلی تعریف این نوع به شکل زیر است:
tf.placeholder(dtype,shape=None,name=None )
arguments:
"dtype": Type of data
"shape": dimension of the placeholder. Optional. By default, shape of the data
"name": Name of the placeholder. Optional
data_placeholder_a = tf.placeholder(tf.float32, name = "data_placeholder_a")
print(data_placeholder_a)Tensor("data_placeholder_a:0", dtype=float32)
مفهوم Session در TENSORFLOW
هر Session (جلسه یا نشست) عملیات گراف را اجرا خواهد کرد. برای مقداردهی گراف با TENSORهای متغیر، باید یک نشست باز کنید و در داخل آن عملیاتی برای تولید خروجی اجرا کنید. بیایید برای درک بهتر این مفهوم را با تشریح مثال ساده ی ضرب دو عدد شروع کنیم.
import tensorflow as tf
# Variables definition
x = tf.constant(6)
y = tf.constant(8)
# Operations definition
result = tf.multiply(x, y)
print(result)Tensor("Mul=0", shape=(), dtype=int32)
همان طور که میبینید نتیجه عددی برنمی گرداند و فقط شبکه ای از TENSOR ایجاد شده است. برای درک بهتر مسأله مثال رانندگی با اتومبیل را در نظر بگیرید. مثل این است که تا اینجای کار فقط قطعات اتومبیل مونتاژ شده اند و برای رسیدن به هدف طراحی این اتومبیل یعنی حرکت کردن، باید آن را روشن کرد. همین کار در TENSORFLOW معادل استفاده از مفهومی تحت عنوان Session یا نشست یا جلسه است.
sess = tf.Session()
output = sess.run(result)
print(output)48
پس از اجرای عملیات session ایجاد شده را با دستور ()sess.close خاتمه میدهیم تا منابع اختصاص یافته به این نشست آزاد شوند. همان طور که مشاهده نمودید مراحل شامل ایجاد TENSOR برای ورودی، تعریف عملیات ضرب روی آن ها، ایجاد سشن و چاپ خروجی است. همان طور که اشاره کردیم، در TENSORFLOW عملیات در قالب یک گراف محاسباتی انجام میپذیرد. گراف محاسباتی مجموعه ای از یک سری عملیات ریاضی است که در یک ترتیب خاصی محاسبه میشوند. برای مثال محاسبه ی عبارت e=c*d که در آن c= a+b و d=b-1 به فرم گراف زیر است:
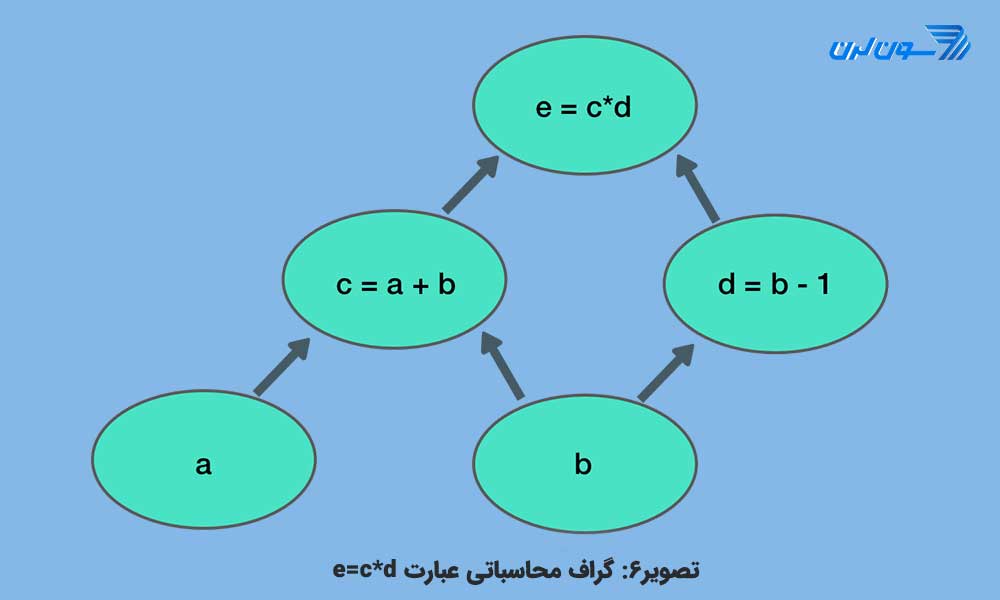
این گراف دو ورودی a و b را میگیرد و خروجی e را میدهد. هر گره در این گراف ورودی(ها) یی را میگیرد و محاسباتی را انجام میدهد و خروجی (ها) را به گره بعدی میدهد. میتوان این گراف محاسباتی را در TENSORFLOW به شکل زیر ایجاد کرد.
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
c = tf.add(a, b)
d = tf.sub(b, 1)
e = tf.mul(c, d)در کد بالا شما placeholder ای تحت عنوان a ایجاد کرده اید و فضایی به اندازه ی اعشار 32 بیتی به آن اختصاص داده اید. حال مقدار این a (که ساختار داده ی TENSOR دارد) برابر مقداری است که شما به عنوان داده ی ورودی گراف محاسباتی (یا همان داده ی آموزشی یک الگوریتم یادگیری ماشین) به آن اختصاص میدهید و خروجی الگوریتم یادگیری ماشین را براساس آن ارزیابی میکنید. اینکه حین تعریف placeholderها آن را 64 بیتی یا 32 یا 16 بیتی در نظر بگیرید بسته به این دارد که فضای مصرفی و زمان اجرای برنامه اولویت است یا دقت خروجی، که اگر 32 بیت در نظر بگیرید به توازنی میان این دو معیار دست یافته ایم.
with tf.Session() as session:
a_data, b_data = 3.0, 6.0
#feed_dict={data_placeholder_a: data}: Feed the placeholder with data
feed_dict = {a: a_data, b:b_data}
output = session.run([e], feed_dict=feed_dict)
print(output)
پس از ایجاد یک session برای این گراف محاسباتی، مقداری که برای یک placeholder در ورودی گرفته میشود از طریق آرگومان feed_dict به گراف محاسباتی ارسال میشود و پس از اجرا خروجی مورد نظر یعنی 45 چاپ میشود.
اجرا روی پردازنده یا کارت گرافیکی
ما میتوانیم برای اینکه به TENSORFLOW نشان دهیم که چه دستگاه هایی را روی کامپیوتر ما برای اجرا میتواند انتخاب کند از دستور زیر استفاده کنیم تا لیست CPU و GPUهای موجود را داشته باشیم:
from tensorflow.python.client import device_libdef get_available_devices():
local_device_protos = device_lib.list_local_devices()
return [x.name for x in local_device_protos]print(get_available_devices())['/device:CPU:0', '/device:XLA_CPU:0', '/device:XLA_GPU:0', '/device:GPU:0']
اگر خروجی بالا را داشتیم، به طور مثال GPU0 را انتخاب میکنیم و ضرب [3,3] در [2,2] را که حاصل 3*2+3*2=12 است را به شکل قطعه کد زیر محاسبه میکنیم:
with tf.Session() as sess:
with tf.device("/GPU:0"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
output = sess.run(product)
print(output)
با دستور with tf.Session() as sess میتوان به پایتون این امکان را داد که منابع Session را به طور خودکار آزاد کند.
دستور زیر یک TENSOR تک بُعدی (1D) با 64 مقدار را مابین 5- و 5+ را ایجاد میکند:
n_values = 64
x = tf.linspace(-5.0, 5.0, n_values)
sess = tf.Session()
result = sess.run(x)
print(result)
علاوه بر دستور ()sess.run میتوان از (x.eval(session=sess برای ارزیابی TENSOR هم استفاده کرد و فراموش نکنیم که در پایان ()sess.close را بنویسیم. همچنین میتوان از یک نشست تعاملی (Interactive Session) به جای ()run. استفاده نمود.
تا این قسمت از مقاله ی آموزش TensorFlow مثالهای ساده ای جهت آشنایی شما و درک بهتر خط کدهای TENSORFLOW را بررسی کردیم. کدهای ما حالت ایستا داشت و الگوریتم به یادگیری نمیپرداخت. در ادامه ی مقاله ی آموزش TensorFlow به بررسی یک مثال عملی در رابطه با یادگیری ماشین خواهیم پرداخت.
Tensorflow ابزار بسیار گسترده ای را برای کنترل کامل محاسبات فراهم میکند. این کار با API سطح پایین (Low level API) انجام میشود. علاوه بر این Tensorflow به مجموعه ی گسترده ای از APIهای سطح بالا برای انجام بسیاری از الگوریتمهای یادگیری ماشین مجهز شده است. Tensorflow این APIهای سطح بالا را تحت عنوان تخمین گر (Estimator) فراخوانی میکند.
API سطح پایین: معماری را میسازد و مدل را بهینه سازی میکند. کار با این سطح برای یک مبتدی پیچیده است.
API سطح بالا: الگوریتم را به راحتی تعریف میکند و کار با آن راحت است. Tensorflow جعبه ابزاری (ToolBox) تحت عنوان Estimator را برای ساخت، آموزش، ارزیابی و ایجاد یک مدل برای پیش بینی را در اختیار کاربران خود قرار داده است.
در مقاله ی آموزش TensorFlow فقط از تخمین گر برای آموزش مدل پیش بینی توسط رگرسیون خطی (Linear Regression) استفاده خواهد شد. با کمک این ToolBox محاسبات سریعتر و آسانتر اجرا میشوند. بخش اول آموزش چگونگی به کارگیری بهینه ساز گرادیان کاهشی (ِGradient Descent Optimizer) را برای آموزش رگرسیون خطی توصیف میکند. همچنین در قالب یک مثال عملی مجموعه داده ی Boston برای پیش بینی قیمت یک خانه به کمک تخمین گر Tensorflow به کار گرفته خواهد شد.
آموزش مدل رگرسیون خطی
در ادامه ی مقاله ی آموزش TensorFlow به آموزش مدل رگرسیون خطی در تنسورفلو میپردازیم.
قبل از آموزش مدل، بیایید با رگرسیون خطی آشنا شویم. تصور کنید که دو متغیر فرضی x و y دارید و کار شما پیش بینی مقدار مجهول y براساس مقدار متغیر x است که مقدار آن مشخص است. اگر دادهها را در نمودار ترسیم کنید میتوانید رابطه ی مستقیم بین متغیر مستقل x و متغیر وابسته ی y را ببینید که به شکل زیر است.
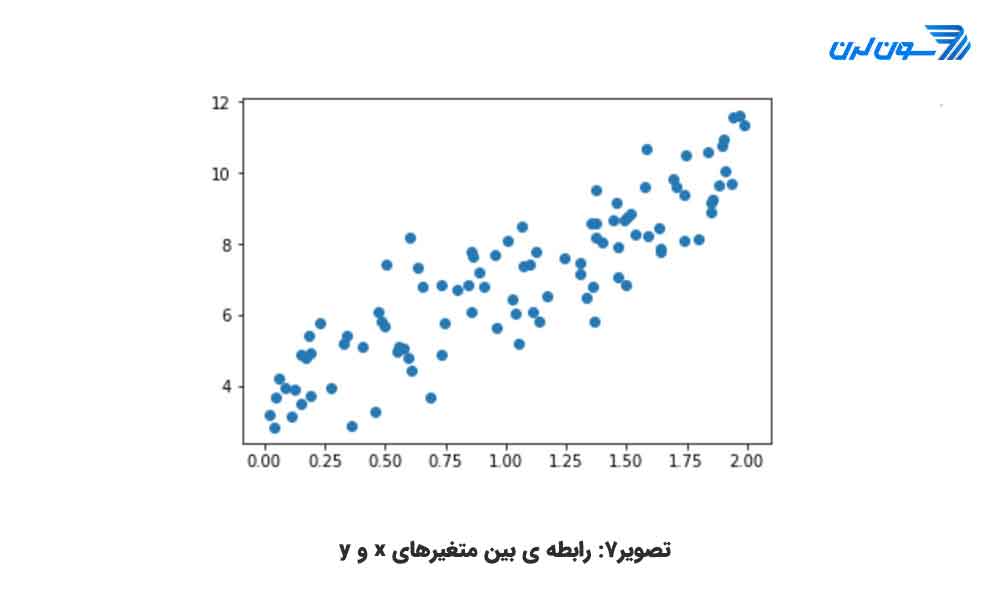
همان طور که میبینید اگر x=1 باشد y تقریبا برابر 6 است و اگر x=2 باشد y حدودا 8.5 خواهد بود. این یک روش دقیق برای پیش بینی y نیست و مستعد خطاست، به خصوص با مجموعه داده ای که صدها هزار نقطه میتواند داشته باشد. رگرسیون خطی با یک معادله ارزیابی میشود. متغیر y توسط یک یا تعداد بیشتری از متغیرها میتواند محاسبه شود. در مثال قبلی فقط یک متغیر مستقل وجود دارد(x). اگر بخواهیم معادله ی مربوط به آن را بنویسیم به شکل زیر خواهد بود:
![]()
که در آن پارامترها به شرح زیر هستند:

منظور از خطای مدل تفاوت مقدار پیش بینی شده با مقدار واقعی است. تصور کنید که مدل را تنظیم کرده و راه حل زیر را برای آن یافته اید. (منظور از تنظیم یا fit کردن یعنی مقادیر پارامترها به گونه ای محاسبه شوند که معادله ی خط حاصل به ازای x نزدیکترین مقدار به y را تولید کند.)
![]()
اگر این اعداد را در معادله جایگزین کنیم تبدیل به فرم زیر میشود:
y=3.8+2.78 x
شما اکنون میتوانید مقادیر بهتری برای y از طریق جای گذاری x در معادله ی بالا بیابید. شکل زیر نمودار حاصل از جای گذاری x را در معادله ی فوق نشان میدهد.
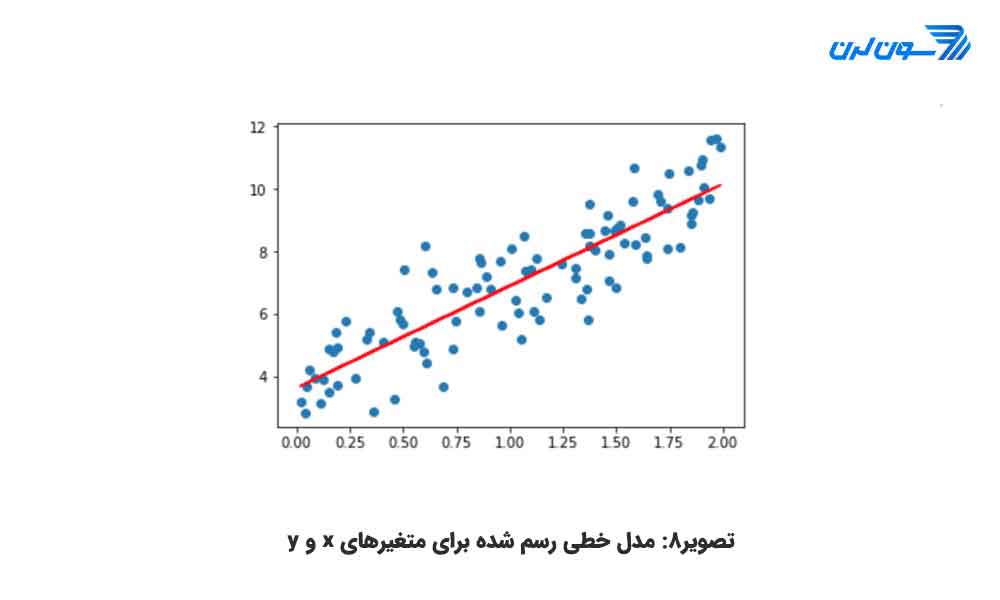
خط قرمز حاصل از به هم پیوستن مقادیر پیش بینی شده برای y بر اساس متغیر x در معادله ی فوق است. بر اساس این خط میتوان مقادیر y را برای xهای بزرگتر از 2 نیز پیش بینی کرد. اگر بخواهید رگرسیون خطی را برای همبستگیهای بیشتر گسترش دهید میتوانید متغیرهای بیشتری را به مدل اضافه کنید. تفاوت میان تحلیلهای سنتی و رگرسیون خطی این است که رگرسیون خطی تعیین میکند که y به مجموعه ای از متغیرهای مستقل چگونه همزمان واکنش نشان میدهد. در حالی که در روش تحلیل همبستگی چگونگی وابسته بودن y را به هر متغیر مستقل، به صورت دو به دو و جداگانه بررسی میکند. بیایید مثالی را بررسی کنیم. فرض کنید میخواهید فروش مغازه ی بستنی فروشی را پیش بینی کنید. مجموعه داده شامل اطلاعات مختلفی مثل وضعیت آب و هوا (بارانی، آفتابی و ابری) و اطلاعات مشتریان (همچون حقوق، جنسیت و وضعیت تأهل) است. تحلیل سنتی سعی در پیش بینی فروش از طریق محاسبه ی میانگین برای هر متغیر به صورت جداگانه میکند و برای سناریوهای مختلف مقدار فروش را تخمین میزند. این امر منجر به پیش بینیهای ضعیف و غیردقیق میشود و تحلیل را به انتخاب سناریوهای خاص محدود میکند. اما اگر شما از رگرسیون خطی استفاده کنید میتوانید معادله ی زیر را برای فروش بنویسید:
![]()
الگوریتم رگرسیون خطی بهترین جواب را برای وزنها (ضرایب متغیرها) و مقدار بایاس پیدا میکند. این به این معنی است که الگوریتم سعی در مینیمم سازی هزینه دارد و برای این کار رابطه ی sales را با کلیه ی متغیرهای مستقل به صورت یکجا بررسی میکند. (منظور از هزینه تفاوت میان مقدار معادله ی خط یافته شده و مقدار متغیر وابسته ی نقاط مجموعه داده است).
نحوه ی کارکرد الگوریتم رگرسیون خطی
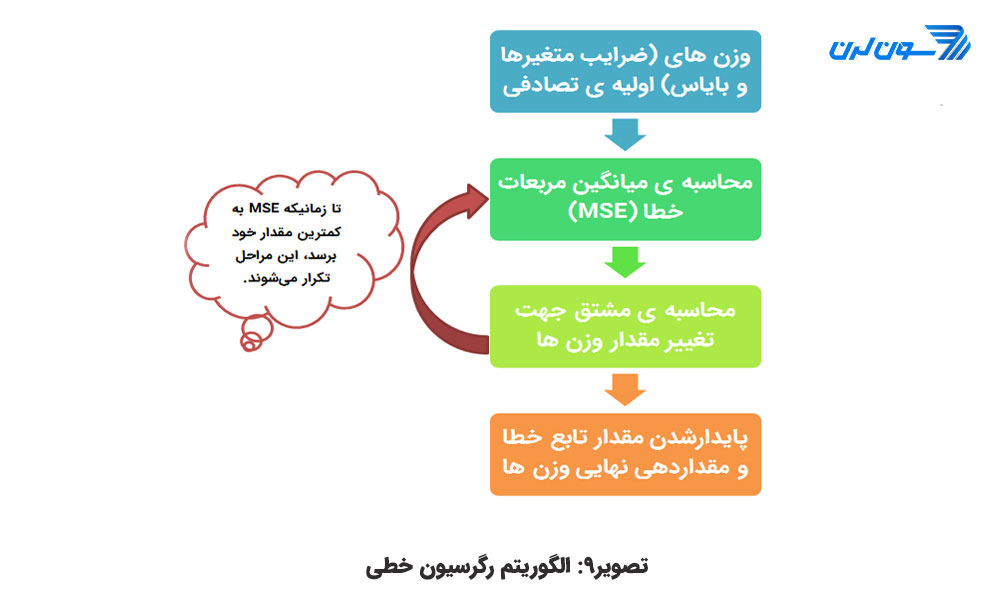
الگوریتم یک عدد تصادفی به ازای هر آلفا و بتا انتخاب میکند و مقدار متغیر x را برای محاسبه ی y جای گذاری میکند. اگر مجموعه داده شامل 100 نمونه باشد الگوریتم 100 مقدار برای y پیش بینی میکند. میتوانیم مقدار خطا را محاسبه کنیم که تحت عنوان اپسیلن (€) در مدل آورده شده و برابر تفاوت میان مقدار پیش بینی شده توسط مدل و مقدار واقعی است. مقدار خطای مثبت بدین معنی است که الگوریتم مدل y پیش بینی شده را کمتر از مقدار واقعی و مقدار خطای منفی یعنی اینکه مدل، y را بیش از مقدار واقعی تخمین زده است.
![]()
هدف این است که مربع خطا را مینیمم کنیم. الگوریتم میانگین مربع خطا را محاسبه میکند. به این مرحله مینیمم سازی خطا میگویند. برای رگرسیون خطی میانگین مربع خطا (MSE(Min Square Error نیز نامیده میشود. که از نظر ریاضی به این صورت است:
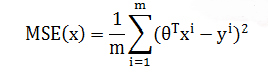

هدف یافتن بهترین ماتریس وزنی است که MSE را مینیمم کند. اگر میانگین خطا بزرگ باشد به این معنی است که مدل ضعیف عمل میکند و وزنها به خوبی انتخاب نشده اند. برای اصلاح وزنها به یک بهینه ساز نیاز است. بهینه ساز مرسوم گرادیان کاهشی (Gradient Descent) با گرفتن مشتق وزنها را کم و زیاد میکند. اگر مشتق مثبت باشد وزن کاهش مییابد و اگر منفی باشد وزن افزایش مییابد.
مدل، وزنها را بروزرسانی میکند و مقدار خطا را دوباره محاسبه میکند. این فرایند تا زمانی که مقدار خطا تغییر نکند تکرار میشود. هر مرحله یک تکرار (Iteration) نامیده میشود. علاوه بر این گرادیان هادر یک نرخ یادگیری ضرب میشوند که بیان گر سرعت یادگیری است. اگر نرخ یادگیری مقدار خیلی کوچکی باشد باعث میشود که زمان همگرایی الگوریتم طولانیتر شود. (یعنی تعداد تکرار بیشتری نیاز داشته باشد.) اگر نرخ یادگیری مقدار خیلی بزرگی داشته باشد باعث میشود که الگوریتم هرگز همگرا نشود.
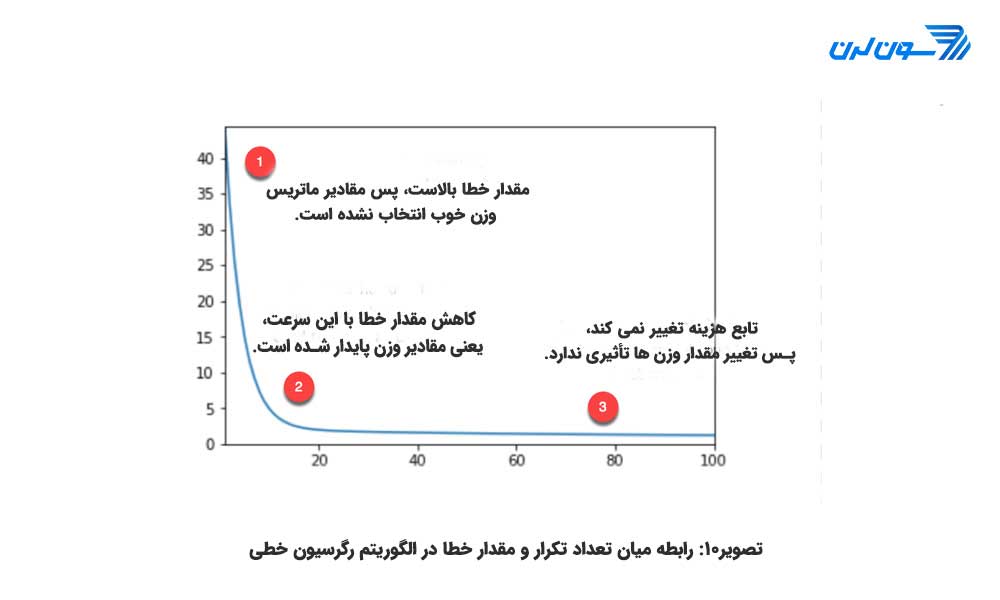
همان طور که در شکل بالا میبینید، مدل بیست مرتبه پیش از یافتن یک مقدار پایدار برای وزنها تکرار میشود و سپس به کمترین میزان خطا دست مییابد. توجه کنید خطا به صفر نمیرسد بلکه حدود مقدار 5 پایدار و بدون تغییر میشود. این به این معنی است که مدل خطایی با مقدار 5 دارد. اگر بخواهیم خطا را کاهش دهیم نیاز به افزودن دادههای بیشتری به مدل، مثل متغیرهای بیشتر و یا استفاده از تخمین گرهای متفاوتی داریم.
چگونه یک رگرسیون خطی را با Tensorflow آموزش میدهیم
حال که مفهوم رگرسیون خطی را فهمیده اید قادر به به کارگیری API تخمین گر ارائه شده توسط Tensorflow برای آموزش اولین رگرسیون خطی خود هستید. در این آموزش از مجموعه داده ی Boston که شامل متغیرهای زیر است استفاده میکنیم.
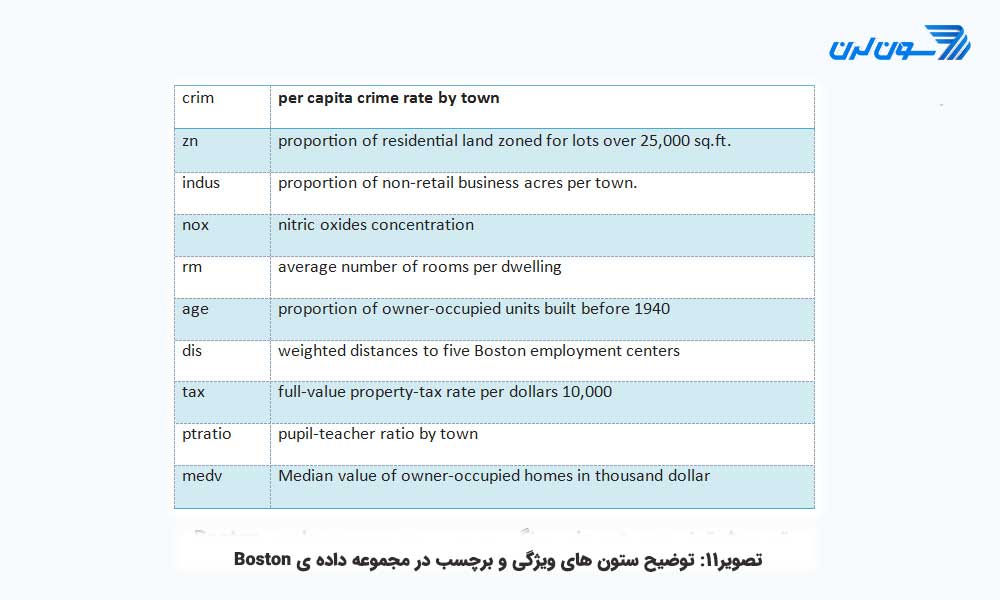
این مجموعه داده را به سه قسمت به شرح زیر تقسیم خواهیم کرد:
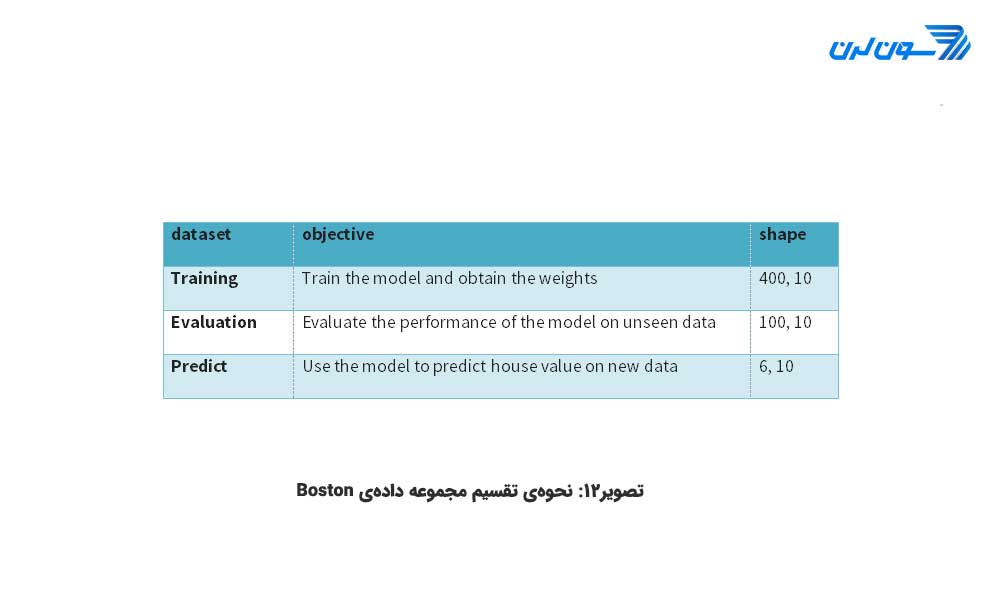
هدف به کارگیری ویژگیهای مجموعه داده برای پیش بینی ارزش قیمت یک خانه است. در ادامه ی آموزش TensorFlow ، شما یاد خواهید گرفت که چگونه و از طریق دو روش مختلف داده را وارد محیط Tensorflow کنید. توجه کنید که هر دوی این روشها نتایج یکسانی در پی دارند:
- به کمک Pandas
- تنها با Tensorflow
دوباره یادآوری میکنیم که در این آموزش، نحوه ی چگونگی استفاده از API سطح بالا برای ایجاد و آموزش ارزیابی یک مدل رگرسیون خطی در تنسورفلو را یاد خواهید گرفت. اگر شما از یک API سطح پایین برای این کار استفاده کنید میبایست تابع Loss Function، بهینه سازی، گرادیان کاهشی، ضرب ماتریسی، گراف و تنسور را به صورت دستی تعریف کنید که اینها برای افراد مبتدی پیچیده اند.
رگرسیون خطی به کمک Pandas
برای آموزش مدل باید کتابخانههای مربوط را نصب و فعال سازی کنید. (در صورت نیاز میتوانید به مقاله ی آموزش Pandas مراجعه کنید.)
import pandas as pd
from sklearn import datasets
import tensorflow as tf
import itertoolsقدم اول: وارد کردن داده با Pandas
نام ستونها (ویژگی) را تعریف و در متغیر COLUMNS ذخیره میکنید. میتوانید از تابع ()pd.read_csv برای وارد کردن دادهها استفاده کنید.
COLUMNS = ["crim", "zn", "indus", "nox", "rm", "age",
"dis", "tax", "ptratio", "medv"]
#-------------------------------------------------
training_set = pd.read_csv("E:/boston_train.csv", skipinitialspace=True,skiprows=1, names=COLUMNS)
test_set = pd.read_csv("E:/boston_test.csv", skipinitialspace=True,skiprows=1, names=COLUMNS)
prediction_set = pd.read_csv("E:/boston_predict.csv", skipinitialspace=True,skiprows=1, names=COLUMNS)می توان شکل (ابعاد) داده را با دستور زیر به دست آورد:
print(training_set.shape, test_set.shape, prediction_set.shape) (400, 10) (100, 10) (6, 10)
توجه کنید که برچسب (منظور مقدار y در معادله ی رگرسیون یا همان ارزش قیمت خانه در مسئله) در مجموعه داده Boston وجود دارد. بنابراین باید دو لیست دیگر را تعریف کنید. یکی تنها شامل ویژگیها و دیگری تنها با نام برچسب. این دو لیست به تخمین گر شما ویژگیهای مجموعه داده و نام ستون برچسب هر کلاس را نشان خواهد داد. از طریق کد زیر این کار را انجام میدهیم:
FEATURES = ["crim", "zn", "indus", "nox", "rm",
"age", "dis", "tax", "ptratio"]
LABEL = "medv"قدم دوم: تبدیل داده ها
باید متغیرهای عددی را به فرمت مناسب تبدیل کرد. Tensorflow متدی را برای تبدیل متغیرهای پیوسته تحت عنوان ()tf.feature_column.numeric_column در اختیار شما قرار میدهد. در گام قبلی شما لیستی از ویژگی هایی که برای مدل در نظر داشتید را تعریف کردید. اکنون از این لیست برای تبدیل آنها به داده ی عددی میتوانید استفاده کنید. اگر میخواهید ویژگی هایی را در مدل خود حذف کنید این کار را پیش از ساخت ستونهای ویژگی مدل خود (feature_cols) انجام دهید.
feature_cols = [tf.feature_column.numeric_column(k) for k in FEATURES]قدم سوم: تعریف تخمین گر (Estimator)
در این مرحله شما نیاز به تعریف تخمین گر دارید. Tensorflow در حال حاضر شش تخمین گر از پیش ساخته شده را فراهم میکند که سه تای آن برای طبقه بندی (Classification) و سه تای آن برای رگرسیون به کار میرود.
تخمین گر رگرسیون (Regressor):
- DNN Linear Combined Regressor
- Linear Regressor
- DNN Regressor
تخمین گر طبقه بندی (Classifier):
- DNN Linear Combined Classifier
- Linear Classifier
- DNN Classifier
در این آموزش از Linear Regressor استفاده خواهیم کرد. برای دسترسی به این تابع از tf.estimator استفاده میکنیم. برای تابع tf.estimator باید دو آرگومان تعریف شود:
- Feature_columns : شامل متغیرهای موجود در مدل است.
Model_dir : مسیر ذخیره سازی گراف، ذخیره ی پارامترهای مدل و ... . Tensorflow به طور اتوماتیک فایلی تحت عنوان train در دایرکتوری کاری شما ایجاد میکند. شما باید این مسیر را برای دستیابی به تنسوربرد (Tensor board) استفاده کنید.
estimator = tf.estimator.LinearRegressor( feature_columns=feature_cols, model_dir="train")
INFO:tensorflow:Using default config. INFO:tensorflow:Using config: {'_model_dir': 'train', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a215dc550>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
قسمت پیچیده ی کار با Tensorflow نحوه ی فیددهی مدل (وارد کردن داده ها) است. Tensorflow برای کار با محاسبات موازی و مجموعه دادههای بزرگ طراحی شده است. به خاطر محدودیت منابع کامپیوتر فیددهی مدل با همه ی دادهها به طور همزمان غیرممکن است. برای این کار شما باید هر بار دسته ای از دادهها (Batch of Data) را به مدل بدهید. توجه داشته باشید که ما در مورد مجموعه دادههای عظیم با میلیونها داده یا حتی بیشتر صحبت میکنیم. اگر به صورت دسته ای دادهها را اضافه نکنید در نهایت با خطای حافظه مواجه خواهید شد. به طور مثال اگر داده ی شما شامل صد نمونه باشد و شما دسته ی داده ای به اندازه ی ده تایی تعریف کنید این به این معنی است که مدل ده نمونه به ازای هر تکرار مشاهده خواهد کرد (10*10). وقتی که مدل تمامی دادهها را دریافت کرد یک دوره (Epoch) را تمام میکند هر دوره تعیین میکند که چند مرتبه شما میخواهید مدل، کل داده را مشاهده کند.
موضوع بعدی این است که شما دادهها را قبل از هر تکرار تغییر دهید یا ترکیب کنید. در طول آموزش مدل تغییر دادهها مسأله ی مهمی است تا مدل یک الگوی خاص از مجموعه ی داده را یاد نگیرد. چون اگر مدل جزییات الگوی موجود در دادهها را یاد بگیرد نمیتوان آن را برای پیش بینی دادههای جدید و دیده نشده تعمیم داد. در واقع میخواهیم از بیش برازش (over fitting) جلوگیری کنیم. بیش برازش (over fitting) سبب میشود تا مدل روی دادههای آموزشی عملکرد بسیار خوبی داشته باشد. اما دادههای تست را با خطای بسیار بالا برچسب دهی کند.
Tensorflow این دو مسأله ی تعداد مشاهدات مورد نیاز (Batchها یا همان تعداد تکرار) و همچنین تغییر داده را به خوبی مدیریت میکند. برای ساخت نحوه ی فیددهی به مدل میتوان از pandas_input_fn استفاده کرد. این آبجکت (object) به 5 پارامتر نیاز دارد.
- x: داده ی ویژگی.
- y: داده ی مربوط به برچسب.
- batch_size: اندازه ی دستهها یا همان تعداد نمونه ی آموزشی که به طور پیش فرض 128 است.
- num_epoch: تعداد مراحل که به طور پیش فرض یک است.
- shuffle: تعیین میکند که دادهها را ترکیب کند یا نه. که پیش فرض None دارد.
چون مدل در چندین مرحله آموزش مییابد، باید دادهها را به الگوریتم چندین بار فیددهی کنیم. برای این کار از تابع get_input_fn استفاده میکنیم تا پروسه ی فیددهی دادهها را تکرار کند.
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)متد رایج ارزیابی کارایی مدل شامل موارد زیر است:
- آموزش مدل
- ارزیابی مدل برای یک مجموعه داده ی متفاوت
- پیش بینی برچسب داده
تخمین گر Tensorflow سه تابع مختلف را برای انجام این سه مرحله فراهم کرده و آن را بسیار ساده میسازد.
قدم چهارم: آموزش مدل
می توان از estimator.train برای ارزیابی مدل استفاده کرد. train. estimator دو آرگومان ورودی دارد، یکی تابعی با عنوان input_fn و دیگری پارامتری با نام steps. میتوانید از تابعی که در مراحل قبلی با عنوان get_input_fn ساخته اید برای فیددهی استفاده کنید. سپس مدل را با تکرار 1000 مرتبه روی دادهها بسازید. توجه کنید که شما تعداد epochها رو تعیین نمیکنید و شما تنها مدل را 1000 مرتبه تکرار میکنید. اگر شما epoch را برابر یک تنظیم کنید، مدل 4 مرتبه تکرار میشود: چون 400 نمونه در مجموعه داده ی آموزشی دارید و اندازه ی هر دسته (batch size) برابر 128 است. پس بهتر است epoch را None گذاشته و تعداد تکرار را تعیین کرد.
estimator.train(input_fn=get_input_fn(training_set,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000) INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into train/model.ckpt. INFO:tensorflow:loss = 83729.64, step = 1 INFO:tensorflow:global_step/sec: 238.616 INFO:tensorflow:loss = 13909.657, step = 101 (0.420 sec) INFO:tensorflow:global_step/sec: 314.293 INFO:tensorflow:loss = 12881.449, step = 201 (0.320 sec) INFO:tensorflow:global_step/sec: 303.863 INFO:tensorflow:loss = 12391.541, step = 301 (0.327 sec) INFO:tensorflow:global_step/sec: 308.782 INFO:tensorflow:loss = 12050.5625, step = 401 (0.326 sec) INFO:tensorflow:global_step/sec: 244.969 INFO:tensorflow:loss = 11766.134, step = 501 (0.407 sec) INFO:tensorflow:global_step/sec: 155.966 INFO:tensorflow:loss = 11509.922, step = 601 (0.641 sec) INFO:tensorflow:global_step/sec: 263.256 INFO:tensorflow:loss = 11272.889, step = 701 (0.379 sec) INFO:tensorflow:global_step/sec: 254.112 INFO:tensorflow:loss = 11051.9795, step = 801 (0.396 sec) INFO:tensorflow:global_step/sec: 292.405 INFO:tensorflow:loss = 10845.855, step = 901 (0.341 sec) INFO:tensorflow:Saving checkpoints for 1000 into train/model.ckpt. INFO:tensorflow:Loss for final step: 5925.9873.
می توانید با دستور زیر گراف محاسباتی را در Tensorbord چک کنید.
# For Windows
tensorboard --logdir=trainقدم پنجم: ارزیابی مدل
با کد زیر میتوان مدل یاد گرفته شده را روی داده ی تست fit کرد و به کار گرفت.
ev = estimator.evaluate(
input_fn=get_input_fn(test_set,
num_epochs=1,
n_batch = 128,
shuffle=False))INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2018-05-13-01:43:13 INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Finished evaluation at 2018-05-13-01:43:13 INFO:tensorflow:Saving dict for global step 1000: average_loss = 32.15896, global_step = 1000, loss = 3215.896
مقدار خطای مدل یا همان loss را با دستور زیر جداگانه میتوان چاپ کرد.
loss_score = ev["loss"]
print("Loss: {0:f}".format(loss_score))Loss: 3215.895996
این مدل حدود ۳۰۰۰ خطا داشته است. برای بررسی میزان کم یا زیاد بودن خطای مدل حاصل، میتوانیم اطلاعات آماری داده هایمان را بررسی کنیم. به دستور زیر و خروجی آن توجه کنید:
training_set['medv'].describe() count 400.000000 mean 22.625500 std 9.572593 min 5.000000 25% 16.600000 50% 21.400000 75% 25.025000 max 50.000000 Name: medv, dtype: float64
از اطلاعات آماری خلاصه شده در خروجی بالا، میتوان فهمید که میانگین قیمت خانه در دادههای آموزشی حدود 22 هزار تا است و این درحالی است که کمترین میزان قیمت 9 هزار تا و بیشترین میزان قیمت 50 هزار تا است. مدل ساخته شده هم، حدود سه هزار تا میتواند در تخمین قیمتها خطا داشته باشد.
قدم ششم: پیش بینی
درنهایت میتوانید از estimator.predict برای پیش بینی قیمت شش خانه در این مثال استفاده کنید.
y = estimator.predict(
input_fn=get_input_fn(prediction_set,
num_epochs=1,
n_batch = 128,
shuffle=False))خروجی کد بالا را با دستور زیر چاپ کنید.
predictions = list(p["predictions"] for p in itertools.islice(y, 6))print("Predictions: {}".format(str(predictions)))INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. Predictions: [array([32.297546], dtype=float32), array([18.96125], dtype=float32), array([27.270979], dtype=float32), array([29.299236], dtype=float32), array([16.436684], dtype=float32), array([21.460876], dtype=float32)]
راه حل مبتنی بر Tensorflow
در این بخش به توضیح نحوه ی حل مسأله تنها با استفاده از فریم ورک Tensorflow میپردازیم که کمی پیچیدهتر از روش قبلی است. توجه کنید که اگر از Jupyter notebook استفاده میکنید آن را Restart کرده و kernel را پاک کنید. در این بخش تابع input_fn را خودتان تعریف خواهیدکرد.
قدم اول رگرسیون خطی در تنسورفلو: تعریف مسیر و فرمت داده ها:
ابتدا دو متغیر را برای مسیر دادههای فایل csv تعیین میکنید. توجه داشته باشید که شما دو فایل csv دارید: یکی دادههای آموزشی و دیگری دادههای آزمایشی.
import tensorflow as tf
df_train = "E:/boston_train.csv"
df_eval = "E:/boston_test.csv"سپس باید ستون هایی که نیاز دارید به کار ببرید را تعیین کنید که در این مثال ما همه ی ستونها را به کارمی گیریم و همچنین نوع متغیرها را هم باید مشخص کرد. متغیرهای اعشاری را با [.0] تعریف میکنیم.
COLUMNS = ["crim", "zn", "indus", "nox", "rm", "age",
"dis", "tax", "ptratio", "medv"]RECORDS_ALL = [[0.0], [0.0], [0.0], [0.0],[0.0],[0.0],[0.0],[0.0],[0.0],[0.0]]قدم دوم رگرسیون خطی در تنسورفلو: تعریف تابع input_fn:
تابع میتواند به سه قسمت مساوی تقسیم شود:
- وارد کردن داده
- ایجاد iterator یا اشاره گر
- استفاده از داده ها
کد در حالت کلی به شکل زیر تعریف میشود که توضیحات کد در ادامه آورده شده است.
def input_fn(data_file, batch_size, num_epoch = None):
# Step 1
def parse_csv(value):
columns = tf.decode_csv(value, record_defaults= RECORDS_ALL)
features = dict(zip(COLUMNS, columns))
#labels = features.pop('median_house_value')
labels = features.pop('medv')
return features, labels
# Extract lines from input files using the
Dataset API.
dataset = (tf.data.TextLineDataset(data_file) # Read text file
.skip(1) # Skip header row
.map(parse_csv))
dataset = dataset.repeat(num_epoch)
dataset = dataset.batch(batch_size)
# Step 3
iterator = dataset.make_one_shot_iterator()
features, labels = iterator.get_next()
return features, labels1. وارد کردن داده
برای یک فایل csv، متد مجموعه داده در هر دفعه میتواند یک سطر را بخواند. برای ساخت مجموعه داده، نیاز به استفاده از آبجکت TextLineDataset داریم. مجموعه داده ی شما یک سرآیند (Header) دارد که شامل نام ویژگیها و برچسب دادهها است و در محاسبات استفاده نمیشود، پس خط اول را نمیخوانید. برای فیددهی به مدل ستون برچسب را از دادهها جدا میکنیم. از متد map برای تبدیل هرگونه داده استفاده میکنیم. این متد تابعی را فراخوانی میکند که شما برای ایجاد مبدل داده از آن استفاده خواهید کرد.
به طور خلاصه شما باید داده را به شیء TextLineDataset بدهید، سرآیند دادهها را حذف کنید و در نهایت یک تبدیل داده به کمک یک تابع انجام دهید:
(tf.data.TextLineDataset(data_file: این خط فایل csv را میخواند.
(skip(1. :سرآیند را رد کرده و درنظر نمیگیرد.
(map(parse_csv.: فایل csv را خوانده و به فرم تنسور تبدیل میکند. pars_csv فایل csv را با tf.decode_csv پیمایش کرده و ستونهای ویژگی و برچسب را تعیین میکند.
ویژگیها میتوانند به فرم دیکشنری یا تاپل باشند که فرم دیکشنری برای استفاده راحتتر است. توضیح کد:
(tf.decode_csv(value, record_defaults= RECORDS_ALL: متد decode_csv از خروجی TextLineDataset برای خواندن فایل csv استفاده میکند. record_defaults مرتبط به نوع داده ی ستون هاست.
- (dict(zip(_CSV_COLUMNS, columns): دادههای استخراجی ستونها را به شکل دیکشنری تبدیل میکند.
- ('features.pop('median_house_value: متغیر برچسب را از متغیرهای ویژگی جدا میکند.
مجموه داده در طول آموزش چندین مرتبه به تنسورها داده (فیددهی) میشود. پس باید متدی تعریف شود تا این فیددهی را به طور مکرر و نامحدود بتواند انجام دهد و اجرای برنامه با خطا مواجه نگردد. batch_size هم تعیین میکند که در هر مرتبه چه تعداد از دادههای مجموعه داده به پایپ لاین برای انجام محاسبات ارسال شود.
2. ایجاد iterator یا اشاره گر
هدف ساخت Iterator و یا اشاره گرهایی برای برگرداندن عناصر مجموعه داده است. سادهترین راه استفاده از make_one_shot_iterator است و پس از آن شما قادر به ایجاد کار کردن با ویژگیها و برچسب کلاس به کمک iterator خواهید بود.
3. استفاده از داده ها
برای اینکه بدانید چه اتفاقی در تابع input_fn رخ میدهد، میتوانید با به کارگیری دادهها آن را کنترل کنید. این کار را با batch_size=1 انجام دهید. توجه کنید که قطعه کد زیر ویژگیها را به صورت دیکشنری و ستون برچسب را به شکل آرایه نمایش میدهد. اگر میخواهید در خروجی، سطرهای دیگر فایل csv مجموعه داده را ببینید میتوانید کد را با batch_sizeهای دیگر امتحان کنید.
next_batch = input_fn(df_train, batch_size = 1, num_epoch = None)
with tf.Session() as sess:
first_batch = sess.run(next_batch)
print(first_batch)({'crim': array([2.3004], dtype=float32), 'zn': array([0.], dtype=float32), 'indus': array([19.58], dtype=float32), 'nox': array([0.605], dtype=float32), 'rm': array([6.319], dtype=float32), 'age': array([96.1], dtype=float32), 'dis': array([2.1], dtype=float32), 'tax': array([403.], dtype=float32), 'ptratio': array([14.7], dtype=float32)}, array([23.8], dtype=float32))
قدم سوم رگرسیون خطی در تنسورفلو: تعریف ستونهای ویژگی
ویژگیهای عددی را به شکل زیر تعریف میکنیم:
X1= tf.feature_column.numeric_column('crim')
X2= tf.feature_column.numeric_column('zn')
X3= tf.feature_column.numeric_column('indus')
X4= tf.feature_column.numeric_column('nox')
X5= tf.feature_column.numeric_column('rm')
X6= tf.feature_column.numeric_column('age')
X7= tf.feature_column.numeric_column('dis')
X8= tf.feature_column.numeric_column('tax')
X9= tf.feature_column.numeric_column('ptratio')توجه کنید که شما نیاز دارید تا تمام متغیرها را در یک براکت، به شکل زیر جمع کنید.
base_columns = [X1, X2, X3,X4, X5, X6,X7, X8, X9]قدم چهارم رگرسیون خطی در تنسورفلو: ساختن مدل
مدل را با تخمین گر رگرسیون خطی به شکل زیر آموزش میدهیم.
model = tf.estimator.LinearRegressor(feature_columns=base_columns, model_dir='train3')INFO:tensorflow:Using default config. INFO:tensorflow:Using config: {'_model_dir': 'train3', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1820a010f0>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
باید از تابع لامبدا برای نوشتن آرگومانهای داخل input_fn استفاده کرد و بدون لامبدا فانکشن قادر به آموزش مدل نخواهید بود.
# Train the estimatormodel.train(steps =1000,
input_fn= lambda : input_fn(df_train,batch_size=128, num_epoch = None))INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into train3/model.ckpt. INFO:tensorflow:loss = 83729.64, step = 1 INFO:tensorflow:global_step/sec: 72.5646 INFO:tensorflow:loss = 13909.657, step = 101 (1.380 sec) INFO:tensorflow:global_step/sec: 101.355 INFO:tensorflow:loss = 12881.449, step = 201 (0.986 sec) INFO:tensorflow:global_step/sec: 109.293 INFO:tensorflow:loss = 12391.541, step = 301 (0.915 sec) INFO:tensorflow:global_step/sec: 102.235 INFO:tensorflow:loss = 12050.5625, step = 401 (0.978 sec) INFO:tensorflow:global_step/sec: 104.656 INFO:tensorflow:loss = 11766.134, step = 501 (0.956 sec) INFO:tensorflow:global_step/sec: 106.697 INFO:tensorflow:loss = 11509.922, step = 601 (0.938 sec) INFO:tensorflow:global_step/sec: 118.454 INFO:tensorflow:loss = 11272.889, step = 701 (0.844 sec) INFO:tensorflow:global_step/sec: 114.947 INFO:tensorflow:loss = 11051.9795, step = 801 (0.870 sec) INFO:tensorflow:global_step/sec: 111.484 INFO:tensorflow:loss = 10845.855, step = 901 (0.897 sec) INFO:tensorflow:Saving checkpoints for 1000 into train3/model.ckpt. INFO:tensorflow:Loss for final step: 5925.9873. Out[8]: <tensorflow.python.estimator.canned.linear.LinearRegressor at 0x18225eb8d0>
مدل ایجاد شده را میتوان روی داده ی تست به شکل زیر به کار گرفت:
results = model.evaluate(steps =None,input_fn=lambda: input_fn(df_eval, batch_size =128, num_epoch = 1))
for key in results:
print(" {}, was: {}".format(key, results[key]))INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2018-05-13-02:06:02 INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train3/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Finished evaluation at 2018-05-13-02:06:02 INFO:tensorflow:Saving dict for global step 1000: average_loss = 32.15896, global_step = 1000, loss = 3215.896 average_loss, was: 32.158958435058594 loss, was: 3215.89599609375 global_step, was: 1000
و اما در آخرین گام میخواهیم مقدار قیمت خانه را برای شش عضو مجموعه ی Predict پیش بینی کنیم. چون که این مجموعه (Predict) ستون برچسب ندارد، پس یک تابع input_fn جدید برایش تعریف میکنیم. برای این کار میتوان از API ی from_tensor موجود در Dataset استفاده کرد.
prediction_input = {
'crim': [0.03359,5.09017,0.12650,0.05515,8.15174,0.24522],
'zn': [75.0,0.0,25.0,33.0,0.0,0.0],
'indus': [2.95,18.10,5.13,2.18,18.10,9.90],
'nox': [0.428,0.713,0.453,0.472,0.700,0.544],
'rm': [7.024,6.297,6.762,7.236,5.390,5.782],
'age': [15.8,91.8,43.4,41.1,98.9,71.7],
'dis': [5.4011,2.3682,7.9809,4.0220,1.7281,4.0317],
'tax': [252,666,284,222,666,304],
'ptratio': [18.3,20.2,19.7,18.4,20.2,18.4]
}
def test_input_fn():
dataset = tf.data.Dataset.from_tensors(prediction_input)
return dataset
# Predict all our prediction_inputpred_results = model.predict(input_fn=test_input_fn) مقدار پیش بینی شده را با دستور زیر میتوان چاپ کرد.
for pred in enumerate(pred_results):
print(pred)INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train3/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. (0, {'predictions': array([32.297546], dtype=float32)}) (1, {'predictions': array([18.96125], dtype=float32)}) (2, {'predictions': array([27.270979], dtype=float32)}) (3, {'predictions': array([29.299236], dtype=float32)}) (4, {'predictions': array([16.436684], dtype=float32)}) (5, {'predictions': array([21.460876], dtype=float32)}) INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train3/model.ckpt-5000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. (0, {'predictions': array([35.60663], dtype=float32)}) (1, {'predictions': array([22.298521], dtype=float32)}) (2, {'predictions': array([25.74533], dtype=float32)}) (3, {'predictions': array([35.126694], dtype=float32)}) (4, {'predictions': array([17.94416], dtype=float32)}) (5, {'predictions': array([22.606628], dtype=float32)})
به طور کلی مراحل زیر را برای اعمال یک مدل یادگیری ماشین درTensorFlow داریم:
تعریف ویژگیها یا همان متغیرهای مستقل: x
تعریف برچسب یا متغیر وابسته: y
ایجاد مجموعه ی آموزشی و آزمایشی
تعریف وزنهای اولیه (در مثال ما ضرایب متغیرهای مستقل و بایاس)
تعریف تابع نقصان یا هزینه یا ضرر (در مثال ما MSE)
بهینه سازی مدل (همچون بکارگیری گرادیان کاهشی)
تعریف کردن:
نرخ یادگیری
تعداد epoch
اندازه ی هر دسته یا batch_size
در این آموزش چگونگی به کارگرفتن API سطح بالا برای رگرسیون خطی تشریح شد. دیدیم که باید موارد زیر را برای این منظور تعریف کنیم:
تعریف ستونهای ویژگی : ()feature_column.numeric_column
به کارگیری تخمین گر: (estimator.LinearRegressor(feature_columns, model_dir
تابعی برای وارد کردن داده و اندازه ی دستهها و تعداد مراحل: ()input_fn
و در آخر قادر به آموزش (train)، ارزیابی (evaluate) و پیش بینی (predict) خواهید بود.
نتیجه گیری
در مقاله ی آموزش TensorFlow با فریم ورک تنسورفلو به طور کلی آشنا شدیم. مفاهیم آن را بررسی کردیم، مثالهای ساده ای برای درک بهتر موضوع، کدزنی کردیم و در پایان چگونگی آموزش یک مدل برمبنای رگرسیون خطی در تنسورفلو را هم دیدیم. اگر در مورد این مقاله سوال یا نظری داشتید خوشحال میشویم که در بخش نظرات با ما و کاربران سون لرن به اشتراک بگذارید.
اگر دوست داری به یک متخصص داده کاوی اطلاعات با زبان پایتون تبدیل شوی و با استفاده از آن در بزرگترین شرکتها مشغول به کار شوی، شرکت در دوره جامع آموزش پایتون را پیشنهاد میکنیم.



۱۱ دیدگاه
۱۶ آبان ۱۴۰۱، ۱۰:۰۴
۰۷ مهر ۱۴۰۱، ۲۰:۳۰
۲۰ شهریور ۱۴۰۱، ۰۶:۴۵
۰۱ دی ۱۴۰۰، ۱۴:۰۹
مریم
۱۰ آبان ۱۴۰۰، ۱۰:۰۲
Nazanin KarimiMoghaddam
۱۰ آبان ۱۴۰۰، ۱۱:۲۲
مهسا
۱۰ شهریور ۱۴۰۰، ۰۴:۱۲
نازنین کریمی مقدم
۱۳ شهریور ۱۴۰۰، ۲۰:۴۱
پدرام
۱۹ شهریور ۱۳۹۹، ۰۰:۵۵
محسن محمدی رهنما
۰۹ خرداد ۱۳۹۹، ۲۲:۳۶
المیرا ناصح
۱۶ خرداد ۱۳۹۹، ۱۰:۴۰

دوره الفبای برنامه نویسی با هدف انتخاب زبان برنامه نویسی مناسب برای شما و پاسخگویی به سوالات متداول در شروع یادگیری موقتا رایگان شد: