۲۹
دیدگاه
نظر

آموزش کامل کتابخانه NumPY
سرفصلهای مقاله
- نصب آناکوندا
- آرایه در NumPy
- Broadcasting یا انتشار همگانی در Numpy
- شکل آرایه (Shape of Array)
- آرایه با مقادیر صفر و یا با مقادیر یک در NumPy
- numpy.reshape و numpy.flatten در پایتون
- اتصال آرایهها به هم در NumPy (Stacking)
- تقسیم آرایه در NumPy (Splitting)
- پیمایش آرایه در NumPy
- جبرخطی در NumPy
- تولید اعداد تصادفی در NumPy
- کار با تاریخ و زمان در NumPy
- numpy.asarray در پایتون
- numpy.arrange در پایتون
- numpy.linspace و numpy.logspace در پایتون
- اندیس دهی (Indexing) و برش (Slicing) آرایههای NumPy در پایتون
- توابع آماری NumPy
- ضرب در پایتون به کمک NumPy
- تفاوت میان Copy و View در NumPy
- نتیجه گیری
اگر به دنبال یادگیری علم داده توسط پایتون هستید، چاره ای جز یادگیری نحوه ی کار با کتابخانههای پایتون که به طور تخصصی برای این منظور طراحی شده اند، ندارید. NumPy، Matplot، Pandas، Seaborn، SiPy، Tensorflow و ... نمونه ای از این پکیجهای نرم افزاری برای محاسبات ریاضی اند که شما در کار با دادهها و پردازش شان باید از آنها استفاده کنید. در مجموعه مقالات آموزش علم داده با پایتون به تشریح کاربردی و مفید این پکیجها و نحوه ی کار با آنها خواهیم پرداخت. NumPy که مخفف Numerical Python است، برای محاسبات عددی متنوعی در پایتون به کار میرود. محاسبات به کمک آرایهها در Numpy سرعت خوبی دارند و علاوه بر آن، توابع این پکیج در ساخت پکیجهای محاسباتی دیگر مورد استفاده قرار گرفته است.
محیط پیشنهادی ما برای کار با پکیجهای محاسباتی در پایتون آناکوندا (Anaconda) است. از این رو نحوه ی نصب آن را نیز آموزش داده ایم. در مقاله ی آموزش کامل کتابخانه NumPY ، سعی بر آن شده تا مجموعه ای از متدها و توابع Numpy به طور کامل تشریح شود. تعداد توابع این نرم افزار بسیار گسترده است و شما در طول انجام پروژههای بزرگ به انواع مختلفی از توابع نیاز خواهید داشت که میتوانید از طیف گسترده ای از پکیجها استفاده کنید. یادگیری Numpy در عین سادگی مفاهیم و قدرتمندی بالای آن، برای کار با سایر کتابخانههای محاسباتی پایتون ضروری است. در ادامه به بررسی توابع این بسته ی نرم افزاری میپردازیم.
نصب آناکوندا
در این قسمت از مقاله ی آموزش کامل کتابخانه NumPY ، با آموزش نصب آناکوندا با ما همراه باشید. آناکوندا پکیجی است که شامل تعدادی از ماژولها و کتابخانههای پایتون است که IDEهایی برای کدزنی در اختیار شما قرار میدهد و Jupyter Notebook یکی از آن هاست. با نصب آناکوندا بسیاری از کتابخانههای محاسباتی پایتون مثل NumPy، Pandas، Matplotlib و ... به طور خودکار نصب میشوند. برای دانلود و نصب آناکوندا متناسب با سیستم خود و همچنین نسخه ی پایتون نصب شده روی سیستم خودتان میتوانید به سایت اصلی آناکوندا مراجعه کنید و اگر به هر دلیلی موفق به بازکردن سایت نشدید میتوانید با جستجو در اینترنت، آناکوندای مناسب سیستم عامل خودتان را بیابید و نصب کنید. (محیطی که ما با آن کار میکنیم سیستم عامل ویندوز و پایتون ورژن 3.7 است.) Jupyter امکان کارکردن با پایتون را در خلال نوت بوک (Notebook) مجازی فراهم میکند و در دنیای علم داده بسیار مشهور است. ژوپیتر این امکان را فراهم میکند که کدها، تصاویر، نمودارها را کنار هم و در یک صفحه ببینید و از این رو برای درک مسائل علم داده به خصوص برای دانشجویان بسیار کاربردی و مفید است.
نصب این نرم افزار نکته ی خاصی ندارد و راحت است. تنها نکته ای که باید توجه کنید این است که شما پس از دانلود فایل و اجرای آن در طول نصب دو پنجره ی زیر را (پنجره ی سمت چپ را زودتر از سمت راست) مشاهده خواهید کرد. توجه کنید که در پنجره ی سمت چپ، تیک گزینه ی اول را طبق توضیحی که خود نرم افزار داده، علامت نزنید. پنجره ی سمت راست مرحله ی نهایی نصب است، و دو گزینه ی آخر را تیک نزنید.
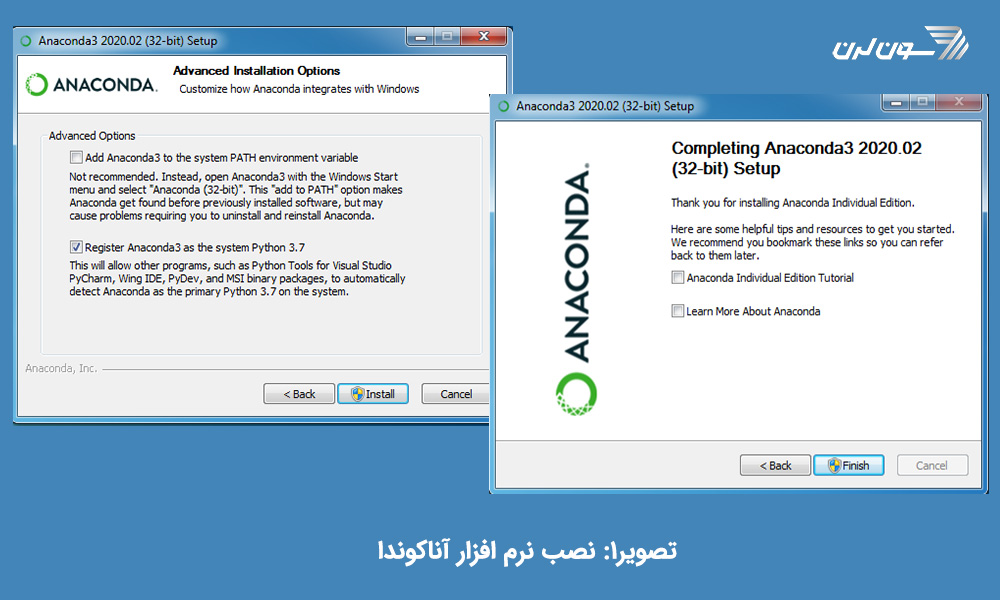
پس از نصب نرم افزار (در ویندوز) در قسمت search از منوی start عبارت anaconda را تایپ کنید و Anaconda Navigator را انتخاب کنید. محیطی را برای شما باز میکند که انواع مختلفی از IDEها را در آن میبینید. Jupyter Notebook را انتخاب کنید. پس از آن وارد صفحه ای به شکل تصویر 2 خواهید شد. از قسمت New گزینه ی Python را انتخاب کنید و وارد محیط کدنویسی شوید.
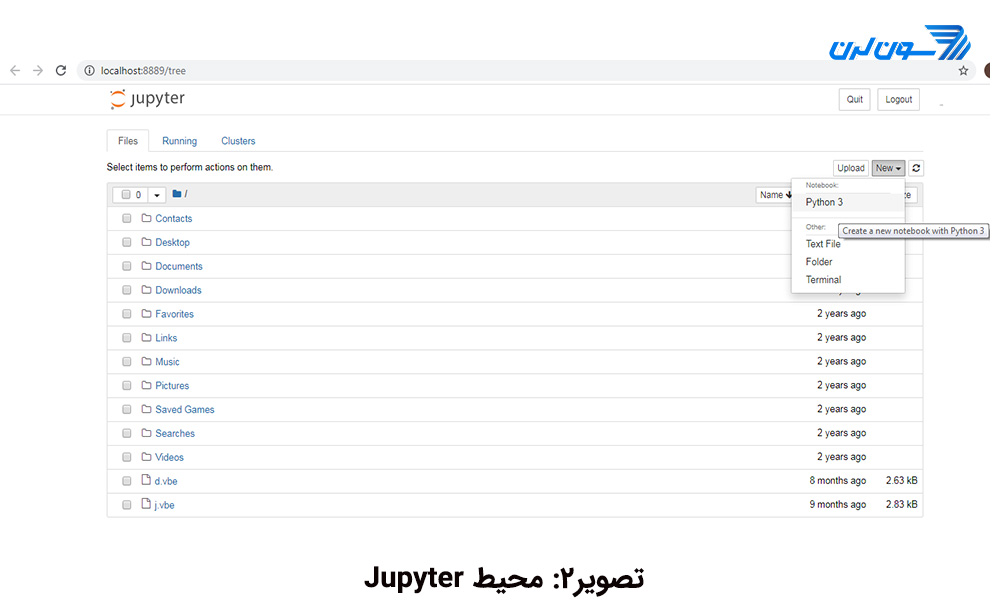
محیط کدنویسی به شکل تصویر 3 است. پس از نوشتن کد خود، برای اجرا روی گزینه ی Run کلیک کنید. 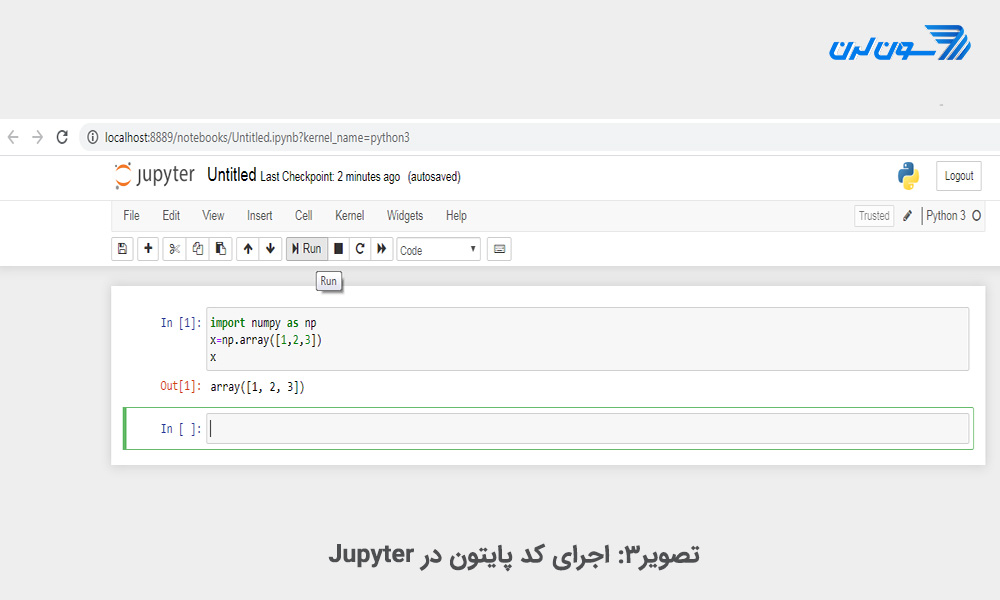
اگر به دلیل حجم بالای آناکوندا (حدود 500MB) نمیخواهید آن را نصب کنید میتوانید از miniconda استفاده کنید که پکیجی خلاصه شده از برخی ویژگیهای آناکوندا برای کار با پایتون است. پس از نصب آن برای نصب JupyterNotebook دستور زیر را در محیط ترمینال یا خط فرمان وارد کنید:
conda install -c conda-forge notebookاگر میخواهید از pip برای نصب استفاده کنید دستور زیر را بنویسید:
pip install notebookبرای اجرای ژوپیتر نوتبوک از طریق خط فرمان میتوانید دستور زیر را تایپ کنید:
jupyter notebookآرایه در NumPy
آرایهها در NumPy تاحدودی شبیه لیست در پایتون هستند اما در اصل با آن تفاوت دارند. اجازه بدهید به طور کامل این موضوع را تشریح کنیم. همان طور که از نام این کتابخانه مشخص است، NumPy از Numeric Python برگرفته شده و امکان کار با اعداد را به طور گسترده فراهم میکند و آرایه ی NumPy ساختار داده ی این کتابخانه است. یعنی برای اینکه بتوانیم با دادهها در این کتابخانه کار کنیم باید آنها را به شکل آرایه تبدیل کرد. در ادامه ی مقاله ی آموزش کامل کتابخانه NumPY ، با ایجاد یک آرایه ی numpy و عملیات ریاضی بر روی آرایهها آشنا میشوید.

ایجاد یک آرایه ی NumPy
سادهترین روش برای ساخت این آرایه استفاده از لیست پایتون است:
myPythonList = [1,9,8,3]برای تبدیل لیست پایتون به آرایه ی NumPy از دستور np.array استفاده میکنیم. (برای چاپ خروجی در ژوپیتر نام متغیر numpy_array_from_list را تایپ میکنیم.)
import numpy as np
numpy_array_from_list = np.array(myPythonList)
numpy_array_from_listarray([1, 9, 8, 3])
در عمل نیازی به تعریف لیست پایتونی به طور مجزا نیست و میتوان به شکل زیر آرایه را تعریف کرد:
a = np.array([1,9,8,3])توجه: در مستندات NumPy از np.darray هم برای ایجاد آرایه استفاده شده، اما روش ذکر شده مرسومتر است. همچنین به جای لیست میتوان از تاپل (tuple) نیز استفاده کرد.
عملیات ریاضی بر روی آرایه ها
عملیات ریاضی همچون جمع، تفریق، ضرب و تقسیم بر روی آرایهها قابل انجام است. دستور کار به صورت استفاده از نام آرایه و عملگر موردنظر (*,?,+,-) و عملوند است:
numpy_array_from_list + 10array([11, 19, 18, 13])
توجه کنید که عدد 10 با تمامی عناصر آرایه جمع زده شده است. در این خصوص مفهوم Broadcasting را در ادامه توضیح میدهیم.
Broadcasting یا انتشار همگانی در Numpy
واژه ی Broadcasting به چگونگی رفتار Numpy با آرایه هایی با Shape متفاوت در خلال عملگرهای محاسباتی اشاره دارد. به طور خلاصه، آرایه ی کوچکتر به اندازه ی آرایه ی بزرگتر پخش میشود تا به شکل و Shape یکسانی با آن تبدیل شود. اینکه از Broadcast استفاده بکنیم یا خیر؛ به شرایط داده و الگوریتم بستگی دارد و میتواند با توجه به آنها به کارگیری این مفهوم در کارایی برنامه تأثیر مثبت یا منفی داشته باشد. Broadcasting در Numpy با توجه به محدودیتهای مسأله و داده، کارایی را کنترل میکند.
قانون Broadcasting: باید اندازه ی محور نهایی یا آخر (یا همان مقدار آخرین Shape)، در هر دو آرایه داده یکسان باشد؛ یا مقدار بُعد آخرِ حداقل یکی از آرایهها برابر یک باشد. حالتهای زیر را در نظر بگیرید:
A(2-D array): 4 x 3 # these numbers are the shape of array
B(1-D array): 3
Result : 4 x 3
A(4-D array): 7 x 1 x 6 x 1
B(3-D array): 3 x 1 x 5
Result : 7 x 3 x 6 x 5
اما این یکی قابلیت Broadcasting ندارد. چون نه مقدار بُعد آخرشان یکی است(یکی 3 و دیگری 0) و نه بُعد نهایی هیچ یک برابر عدد 1 است:
A: 4 x 3
B: 4
سادهترین حالت Broadcast حین انجام عملیات محاسباتی میان یک آرایه و یک عدد اسکالر است.
import numpy as np
a = np.array([1.0, 2.0, 3.0])
# Example 1
b = 2.0
print(a * b)
# Example 2
c = [2.0, 2.0, 2.0]
print(a * c)[ 2. 4. 6.] [ 2. 4. 6.]
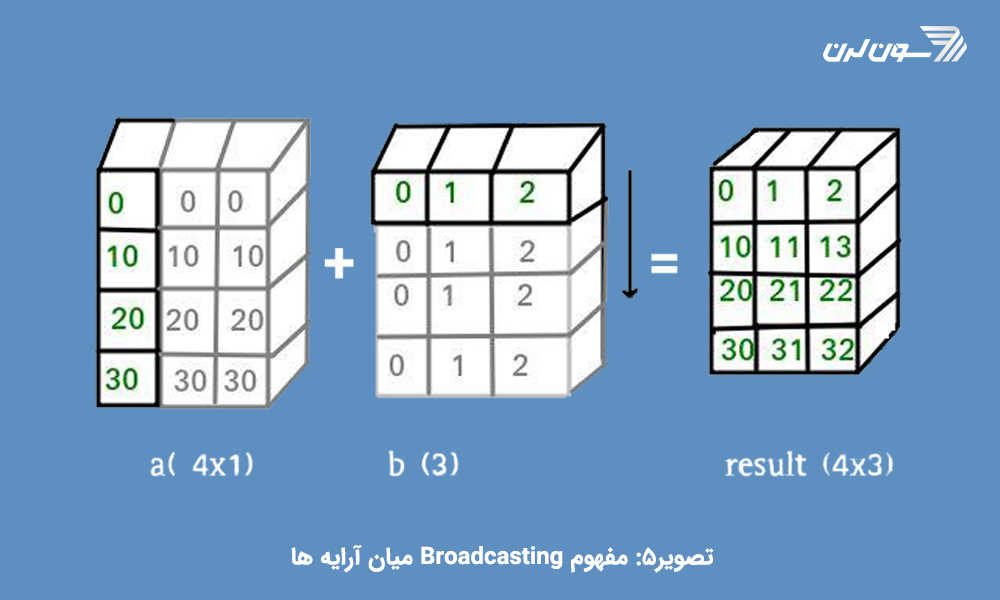
می توان این گونه تصور کرد که عدد اسکالر به تعداد اندازه ی آرایه ای که قرار است با آن در محاسبات شرکت کند، کپی میشود. البته این یک توصیف مفهومی از کار است ( تصویر 4) و Numpy با توجه به هوشمندی که در طراحی اش به کار رفته، برای حفظ کارایی عملکرد و حافظه، چنین کپی ای از آن عدد اسکالر ایجاد نمیکند. 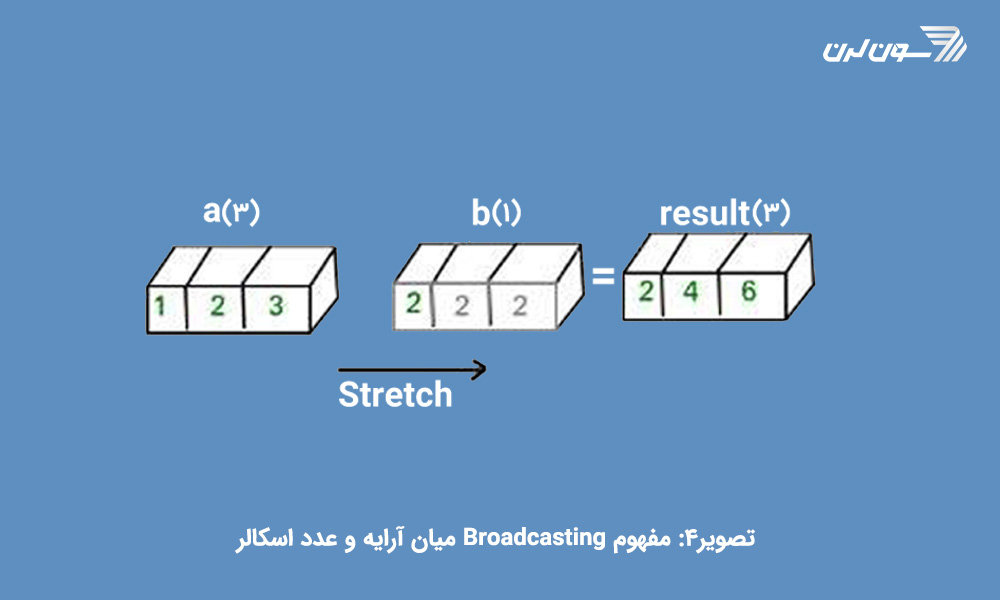
حال مثالی را بررسی میکنیم که هر دو آرایه باید گسترش یابند:
import numpy as np
a = np.array([0.0, 10.0, 20.0, 30.0])
b = np.array([0.0, 1.0, 2.0])
print(a[:, np.newaxis] + b)[[ 0. 1. 2.] [ 10. 11. 12.] [ 20. 21. 22.] [ 30. 31. 32.]]
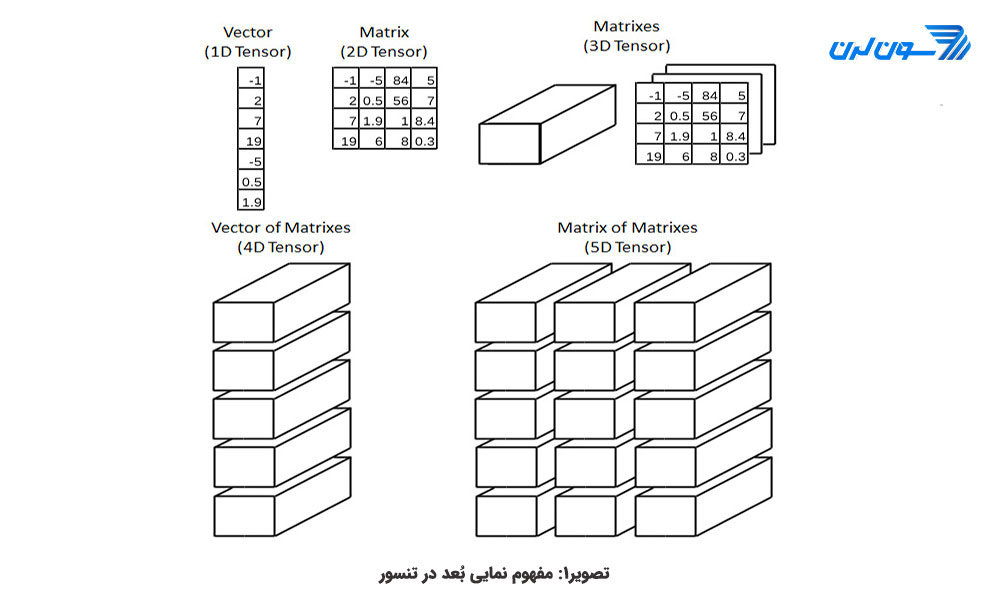
شکل آرایه (Shape of Array)
در این بخش از مقاله ی آموزش کامل کتابخانه NumPY ، شکل آرایه را توضیح خواهیم داد، که میتواند یک بعدی، دوبعدی، یا سه بعدی باشد. شکل آرایه را میتوان با دستور shape. بدست آورد و نیز با دستور dtype. میتوان نوع دادههای آرایه و مقدار فضای اختصاص یافته به آن را فهمید.
import numpy as np
a = np.array([1,2,3])
print(a.shape)
print(a.dtype)
#### Different type
b = np.array([1.1,2.0,3.2])
(3, ) int64
float64
آرایه ی دو بعدی
بعد دوم را میتوان با افزودن یک کاما "," تعریف کرد. البته توجه کنید که دادههای پس از کاما هم داخل براکت باز و بسته [] ( ویا پرانتز () اگر که تاپل باشد ) باید قرار گیرند.
### 2 dimension
c = np.array([(1,2,3),
(4,5,6)])
print(c.shape)(2, 3)
آرایه ی سه بعدی
آرایهها با ابعاد بالاتر به شکل زیر تعریف میشوند: (دوباره یک کاما و یک براکت باز و بسته ی دیگر افزوده میشود.)
### 3 dimension
d = np.array([
[[1, 2,3],
[4, 5, 6]],
[[7, 8,9],
[10, 11, 12]]
])
print(d.shape)(2, 2, 3)
اگر بخواهید فضای اشغال شده توسط آرایه را به دست آورید از تابع itemsize استفاده کنید. به مثال زیر توجه کنید:
x = np.array([1,2,3], dtype=np.complex128)
x.itemsize
16 # element x has 16 bytes
آرایه با مقادیر صفر و یا با مقادیر یک در NumPy
می توان با دستورات np.zeros و np.ones به ترتیب ماتریس هایی ایجاد کرد که تمامی عناصر آن صفر و یک باشند. چنین ماتریس هایی میتوانند به طور مثال برای مقداردهی اولیه ی ماتریس وزنها در شبکه ی عصبی مورد استفاده قرار گیرند. قاعده ی کلی به شکل زیر است:
numpy.zeros(shape, dtype=float, order='C')numpy.ones(shape, dtype=float, order='C')
shape شکل آرایه را تعیین میکند و dtype یا همان datatype نوع داده را مشخص میکند و پارامتری اختیاری است که به طور پیش فرض مقدار آن float64 است. پارامتر order هم اختیاری است و مقدار پیش فرض C را میگیرد و یک استایل پایه برای سطرهای ماتریس است. در زیر چند مثال را میبینیم.
#Example numpy zero
import numpy as np
np.zeros((2,2))
#Example numpy zero with datatype
np.zeros((2,2), dtype=np.int16)
#Example numpy one 2D Array with datatype
np.ones((1,2,3), dtype=np.int16)
خروجیها به ترتیب زیر هستند:
array([[0., 0.], [0., 0.]]) array([[0, 0], [0, 0]], dtype=int16) array([[[1, 1, 1], [1, 1, 1]]], dtype=int16)
numpy.reshape و numpy.flatten در پایتون
گاهی شما نیاز به تغییر (reshape) دادهها از فرم عرضی به طولی دارید. برای این کار از تابع reshape به شکل زیر استفاده میکنیم: (a ورودی ماست.)numpy.reshape(a, newShape, order='C')
import numpy as np
e = np.array([(1,2,3), (4,5,6)])
print(e)
e.reshape(3,2)
// Before reshape [[1 2 3] [4 5 6]] //After Reshape array([[1, 2], [3, 4], [5, 6]])
گاهی در حین کار با شبکههای عصبی نیاز دارید تا آرایه ی خود را مسطح (flat) کنید. برای این کار از flatten. به شکل زیر استفاده میکنیم:
numpy.flatten(order='C')e.flatten()array([1, 2, 3, 4, 5, 6])
اتصال آرایهها به هم در NumPy (Stacking)
چندین آرایه میتوانند در امتداد محورهای مختلف به همدیگر متصل شوند. که در این بخش از مقاله ی آموزش کامل کتابخانه NumPY ، انواع اتصال آرایهها به هم را توضیح میدهیم.
np.vstack: آرایهها را به طور عمودی به هم وصل میکند.
np.hstack: آرایهها را به طور افقی متصل میکند.
np.column_stack: برای اتصال آرایه ی یک بُعدی به عنوان ستون به سطر آرایه ی دوبعدی.
np.concatenate: برای اتصال آرایهها به همدیگر در خلال یک محور معین (یعنی محور یا همان axis به عنوان پارامتر ورودی تابع تعریف میشود.)
مثال زیر نحوه ی کارکرد هر یک را نشان میدهد.
import numpy as np
a = np.array([[1, 2],
[3, 4]])
b = np.array([[5, 6],
[7, 8]])
# vertical stacking
print("Vertical stacking:\n", np.vstack((a, b)))
# horizontal stacking
print("\nHorizontal stacking:\n", np.hstack((a, b)))
c = [5, 6]
# stacking columns
print("\nColumn stacking:\n", np.column_stack((a, c)))
# concatenation method
print("\nConcatenating to 2nd axis:\n", np.concatenate((a, b), 1)) Vertical stacking: [[1 2] [3 4] [5 6] [7 8]] Horizontal stacking: [[1 2 5 6] [3 4 7 8]] Column stacking: [[1 2 5] [3 4 6]] Concatenating to 2nd axis: [[1 2 5 6] [3 4 7 8]]
تقسیم آرایه در NumPy (Splitting)
در این بخش از مقاله ی آموزش کامل کتابخانه NumPY ، توابعی برای تقسیم آرایهها را معرفی میکنیم.
توابعی برای تقسیم آرایهها تعریف شده که به شرح زیر است:
np.hsplit: تقسیم آرایه به شکل افقی.
np.vsplit: تقسیم آرایه به شکل عمودی.
np.array_split: آرایه را در خلال امتداد تعیین شده در ورودی (با پارامتر axis) تقسیم میکند.
import numpy as np
a = np.array([[1, 3, 5, 7, 9, 11],
[2, 4, 6, 8, 10, 12]])
# horizontal splitting
print("Splitting along horizontal axis into 2 parts:\n", np.hsplit(a, 2))
# vertical splitting
print("\nSplitting along vertical axis into 2 parts:\n", np.vsplit(a, 2))Splitting along horizontal axis into 2 parts: [array([[1, 3, 5], [2, 4, 6]]), array([[ 7, 9, 11], [ 8, 10, 12]])] Splitting along vertical axis into 2 parts: [array([[ 1, 3, 5, 7, 9, 11]]), array([[ 2, 4, 6, 8, 10, 12]])]
پیمایش آرایه در NumPy
پیمایش آرایه یا Iterate کردن آن یعنی عناصر آن را یکی یکی مشاهده کنیم. چون با آرایههای چند بعدی در numpy سروکار داریم، پیمایش را میتوان با حلقه ی for در پایتون انجام داد. آرایه ی یک بعدی (1D) را به شکل زیر پیمایش میکنیم:
import numpy as np
arr = np.array([1, 2, 3])
for x in arr:
print(x)1 2 3
در آرایه ی دو بعدی (2D) پیمایش به صورت سطر به سطر انجام میشود:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
for x in arr:
print(x)[1 2 3] [4 5 6]
اگر بخواهیم مقادیر به صورت اسکالر برگردانده شود، به شکل زیر عمل میکنیم.
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
for x in arr:
for y in x:
print(y)1 2 3 4 5 6
در پیمایش آرایه ی سه بعدی (3D) آرایههای دوبعدی آن را جدا میکنیم:
import numpy as np
arr = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
for x in arr:
print(x)[[1 2 3] [4 5 6]] [[ 7 8 9] [10 11 12]]
برای برگرداندن هر عنصر نیز باید آرایه را در هر بعد، جداگانه پیمایش کنیم:
import numpy as np
arr = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
for x in arr:
for y in x:
for z in y:
print(z)1 2 3 4 5 6 7 8 9 10 11 12
پیمایش آرایه با nditer
تابع nditer تابعی است که میتواند از سادهترین تا پیچیدهترین حالت پیمایش را اجرا کند و بسیاری از مشکلات ما را در زمینه ی Iteration حل میکند. به طور مثال برای استخراج عناصر آرایه ی سه بعدی به شکل اسکالر میتوان با این تابع به شکل زیر عمل کرد و درگیر پیچیدگی forهای تودرتو نشد:
import numpy as np
arr = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
for x in np.nditer(arr):
print(x)
1 2 3 4 5 6 7 8
پیمایش آرایه با نوع داده ای مختلف
می توان از آرگومان op_dtypes استفاده کرد و نوع دادهها را به نوع داده ی مورد نظر حین پیمایش تغییر داد. Numpy قادر نیست به طور درجا نوع دادهها را تغییر دهد و برای این کار به فضای اضافی نیاز دارد که این فضای اضافه بافر نام دارد و برای فعال سازی بافر در تابع nditer از flag=['buffered'] استفاده میکنیم.
import numpy as np
arr = np.array([1, 2, 3])
for x in np.nditer(arr, flags=['buffered'], op_dtypes=['S']):
print(x)b'1' b'2' b'3'
پیمایش با گامهای متفاوت
می توانیم دادهها را به طور فیلتر شده پیمایش کنیم. به طور مثال در آرایه ی دوبعدی زیر یک در میان عناصر را خواند.
import numpy as np
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
for x in np.nditer(arr[:, ::2]):
print(x)1 3 5 7
پیمایش با اندیس ها
گاهی حین پیمایش عناصر به اندیس عنصر مورد نظر نیاز داریم. متد ndenumerate برای این منظور به کار میرود.
import numpy as np
arr = np.array([1, 2, 3])
for idx, x in np.ndenumerate(arr):
print(idx, x)(0,) 1 (1,) 2 (2,) 3
مثالی از آرایه ی دو بعدی را هم در این خصوص ببینید:
import numpy as np
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
for idx, x in np.ndenumerate(arr):
print(idx, x)(0, 0) 1 (0, 1) 2 (0, 2) 3 (0, 3) 4 (1, 0) 5 (1, 1) 6 (1, 2) 7 (1, 3) 8
جبرخطی در NumPy
در ادامه ی مقاله ی آموزش کامل کتابخانه NumPY به آموزش جبر خطی در NumPY میپردازیم، ماژول جبرخطی در NumPy متدهای بسیاری را برای اعمال روی انواع آرایهها در NumPy فراهم میکند. شما با این ماژول قادر هستید موارد زیر را محاسبه کنید:
- مرتبه، اثر ماتریس (trace of matrix) و دترمینان یک آرایه
- مقادیر ویژه ی یک ماتریس (eigen values)
- ضربهای ماتریسی و برداری (ضرب نقطه ای، داخلی، خارجی و ...)
- حل معادلات خطی یا تانسور
مثال زیر چگونگی اعمال عملیات جبری را نشان میدهد.
import numpy as np
A = np.array([[6, 1, 1],
[4, -2, 5],
[2, 8, 7]])
print("Rank of A:", np.linalg.matrix_rank(A))
print("\nTrace of A:", np.trace(A))
print("\nDeterminant of A:", np.linalg.det(A))
print("\nInverse of A:\n", np.linalg.inv(A))
print("\nMatrix A raised to power 3:\n", np.linalg.matrix_power(A, 3))Rank of A: 3 Trace of A: 11 Determinant of A: -306.0 Inverse of A: [[ 0.17647059 -0.00326797 -0.02287582] [ 0.05882353 -0.13071895 0.08496732] [-0.11764706 0.1503268 0.05228758]] Matrix A raised to power 3: [[336 162 228] [406 162 469] [698 702 905]]
تصور کنید میخواهیم این معادله ی خطی را محاسبه کنیم.
x + 2*y = 8
3*x + 4*y = 18
این معادله با به کارگیری متد linalg.solve قابل حل است.
import numpy as np
# coefficients
a = np.array([[1, 2], [3, 4]])
# constants
b = np.array([8, 18])
print("Solution of linear equations:", np.linalg.solve(a, b))Solution of linear equations: [ 2. 3.]
در آخر مثالی را بررسی میکنیم که چگونگی محاسبه ی رگرسیون خطی را با استفاده از روش کاهش مربعات خطا نشان میدهد. یادآوری
رگرسیون خطی، خطی است که به فرم w1xi+w2=y است و سعی دارد wiها را طوری تعیین کند که مجموع مربعات فاصله ی نقاطی مانند yi از خط حاصل به کمترین مقدار برسد. (yi مقدار حقیقی برای صفات xi است و w1xi+w2 مقدار تخمینی توسط رگرسیون خطی است.)
import numpy as np
import matplotlib.pyplot as plt
# x co-ordinates
x = np.arange(0, 9)
A = np.array([x, np.ones(9)])
# linearly generated sequence
y = [19, 20, 20.5, 21.5, 22, 23, 23, 25.5, 24]
# obtaining the parameters of regression line
w = np.linalg.lstsq(A.T, y)[0]
# plotting the line
line = w[0]*x + w[1] # regression line
plt.plot(x, line, 'r-')
plt.plot(x, y, 'o')
plt.show() خروجی این معادله به شکل زیر است: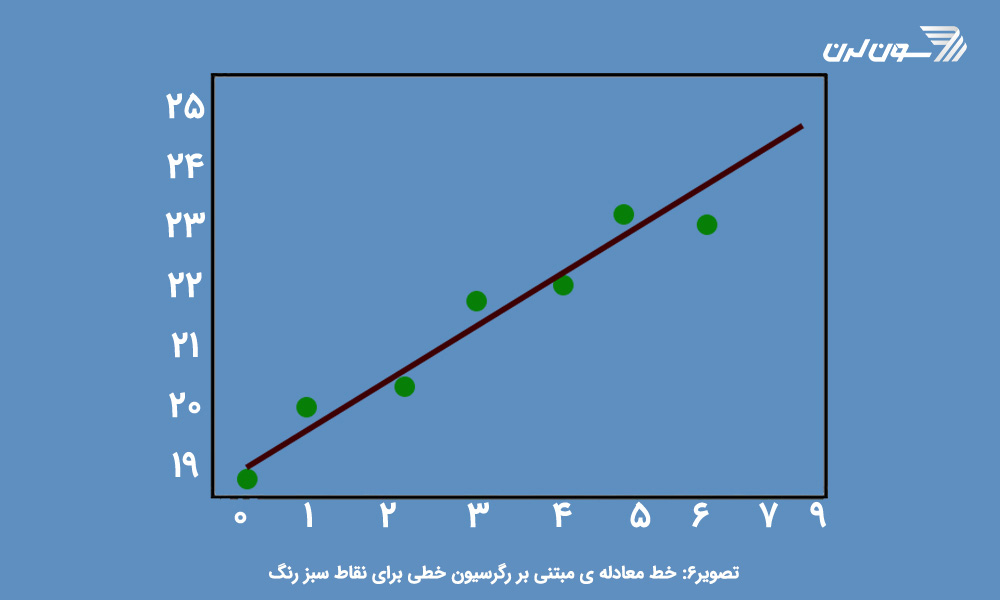
تولید اعداد تصادفی در NumPy
برای تولید اعداد تصادفی در NumPy به طور کلی از تابع random استفاده میکنیم و میتوانیم برای اینکه این اعداد تصادفی در یک توزیع خاص آماری با ویژگیهای مورد نظر ما باشند، از توابع دیگری نیز کمک بگیریم.
numpy.random.rand(d0,d1,…,dn): آرایه ای در ابعاد مشخص ایجاد میکند و درایههای آن را با اعداد تصادفی پر میکند. d0,d1,…,dn ابعاد آرایه را مشخص میکنند و اعدادی صحیح و اختیاری اند. اگر آرگومانی داده نشود یک مقدار اعشاری تولید میکند.
numpy.random.normal(loc, scale, size): آرایه ای در شکل و ابعاد مشخص تولید میکند و درایههای آن را با مقادیر تصادفی که بخشی از یک توزیع نرمال (گوسی) محسوب میشوند، پر میکند. به این توزیع به خاطر شکلی که دارد، منحنی زنگ هم میگویند. و اما پارامترهای این تابع:
loc: میانگین توزیع.
scale: انحراف معیار توزیع.
size: تعداد نمونه داده هاست.
مثالهای زیر را درنظر بگیرید:
# numpy.random.rand() method
import numpy as np
# 1D Array
array = np.random.rand(5)
print("1D Array filled with random values : \n", array)
1D Array filled with random values : [ 0.84503968 0.61570994 0.7619945 0.34994803 0.40113761]
در مثال بعدی آرایه ای یک بُعدی که از توزیع گوسی پیروی میکند، تولید میکنیم:
import numpy as np
# 1D Array
array = np.random.normal(0.0, 1.0, 5)
print("1D Array filled with random values "
"as per gaussian distribution : \n", array)
# 3D array
array = np.random.normal(0.0, 1.0, (2, 1, 2))
print("\n\n3D Array filled with random values "
"as per gaussian distribution : \n", array)
1D Array filled with random values as per gaussian distribution : [-0.99013172 -1.52521808 0.37955684 0.57859283 1.34336863] 3D Array filled with random values as per gaussian distribution : [[[-0.0320374 2.14977849]] [[ 0.3789585 0.17692125]]]
مثال زیر نیز تفاوت تولید اعداد تصادفی در حالت معمول با حالتی که از توزیع نرمال پیروی میکند را نمایش میدهد (از کتابخانه ی matplot برای رسم نمودار کمک گرفته ایم):
import numpy as np
import matplotlib.pyplot as plot
# 1D Array as per Gaussian Distribution
mean = 0
std = 0.1
array = np.random.normal(0, 0.1, 1000)
print("1D Array filled with random values "
"as per gaussian distribution : \n", array);
# Source Code :
# https://docs.scipy.org/doc/numpy-1.13.0/reference/
# generated/numpy-random-normal-1.py
count, bins, ignored = plot.hist(array, 30, normed=True)
plot.plot(bins, 1/(std * np.sqrt(2 * np.pi)) *
np.exp( - (bins - mean)**2 / (2 * std**2) ),
linewidth=2, color='r')
plot.show()
# 1D Array constructed Randomly
random_array = np.random.rand(5)
print("1D Array filled with random values : \n", random_array)
plot.plot(random_array)
plot.show()
خروجی این کد به شکل زیر است: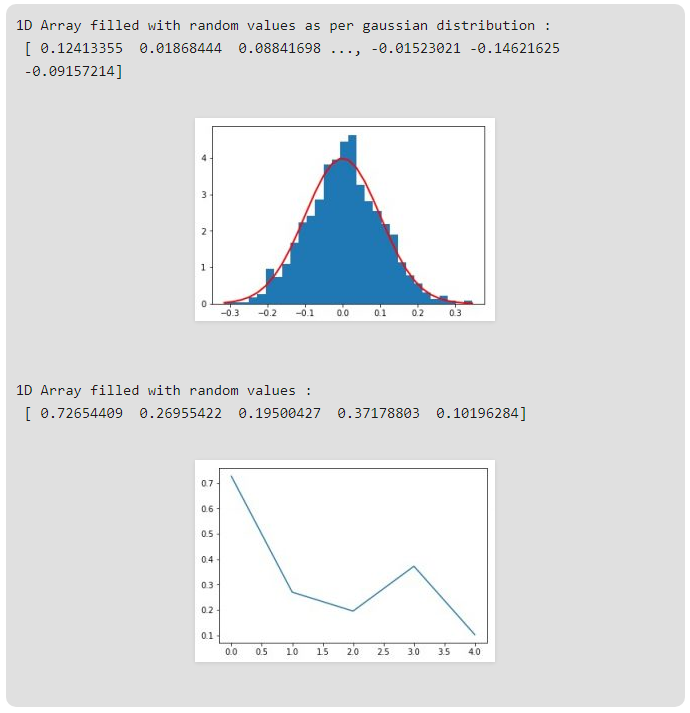
توابع دیگری نیز برای تولید اعداد تصادفی با ویژگیهای مختلف وجود دارد که پیشنهاد میدهیم آنها را از داکیومنت مربوطه، مطالعه کنید.
کار با تاریخ و زمان در NumPy
در این بخش از مقاله ی آموزش کامل کتابخانه NumPY کار با تاریخ و زمان در NumPY را آموزش میدهیم، NumPy دارای انواعی از ساختارهای داده (Data Structure) است که به طور طبیعی از عملکرد datetime پشتیبانی میکنند. این نوع داده 'datetime64' نامیده میشود که از کتابخانه ای در زبان پایتون با همین نام برگرفته شده است. در مثال زیر چند نمونه از کاربرد زمان و تاریخ را میبینید.
mport numpy as np
# creating a date
today = np.datetime64('2017-02-12')
print("Date is:", today)
print("Year is:", np.datetime64(today, 'Y'))
# creating array of dates in a month
dates = np.arange('2017-02', '2017-03', dtype='datetime64[D]')
print("\nDates of February, 2017:\n", dates)
print("Today is February:", today in dates)
# arithmetic operation on dates
dur = np.datetime64('2017-05-22') - np.datetime64('2016-05-22')
print("\nNo. of days:", dur)
print("No. of weeks:", np.timedelta64(dur, 'W'))
# sorting dates
a = np.array(['2017-02-12', '2016-10-13', '2019-05-22'], dtype='datetime64')
print("\nDates in sorted order:", np.sort(a))Date is: 2017-02-12 Year is: 2017 Dates of February, 2017: ['2017-02-01' '2017-02-02' '2017-02-03' '2017-02-04' '2017-02-05' '2017-02-06' '2017-02-07' '2017-02-08' '2017-02-09' '2017-02-10' '2017-02-11' '2017-02-12' '2017-02-13' '2017-02-14' '2017-02-15' '2017-02-16' '2017-02-17' '2017-02-18' '2017-02-19' '2017-02-20' '2017-02-21' '2017-02-22' '2017-02-23' '2017-02-24' '2017-02-25' '2017-02-26' '2017-02-27' '2017-02-28'] Today is February: True No. of days: 365 days No. of weeks: 52 weeks Dates in sorted order: ['2016-10-13' '2017-02-12' '2019-05-22']
numpy.asarray در پایتون
تابع as array برای تبدیل داده ی ورودی به آرایه استفاده میشود. ورودی میتواند به شکل لیست، تاپل و یا ndarray و... باشد. فرم کلی به شکل زیر است:
numpy.asarray(data, dtype=None, order=None)data: داده ای که میخواهید به آرایه تبدیل کنید.
dtype: یک پارامتر اختیاری است و اگر مقداردهی نشود، مقدار آن از نوع دادههای ورودی گرفته میشود.
order: یک پارامتر اختیاری است و مقدار پیش فرض ان C است و استایل پایه برای سطرهاست و مقدار دیگری که میتواند بگیرد F است.
ماتریس دو بُعدی زیر را که شامل چهار سطر و ستون پرشده با یک است در نظر بگیرید:
import numpy as np
A = np.matrix(np.ones((4,4)))
نمی توان مقدار درایههای این ماتریس را با کپی و انتساب به شکل زیر تغییر داد:
np.array(A)[2]=2
print(A)
[[1. 1. 1. 1.] [1. 1. 1. 1.] [1. 1. 1. 1.] [1. 1. 1. 1.]]
ماتریس تغییرناپذیر است. اگر بخواهید تغییری در مقادیر درایهها داشته باشید، میتوانید از تابع asarray استفاده کنید و مثلاً مقادیر سطر سوم را به دو تغییر دهیم:
np.asarray(A)[2]=2
print(A)
[[1. 1. 1. 1.] [1. 1. 1. 1.] [2. 2. 2. 2.] # new value [1. 1. 1. 1.]]
numpy.arrange در پایتون
این تابع در NumPy آرایه ای را برمی گرداند که نتیجه ی آن بازه ای از اعداد است که فاصله ی بین آنها برابر است. قاعده ی کلی دستور به شکل زیر است:
numpy.arrange(start, stop,step)
- start: شروع بازه.
- stop: پایان بازه (که خود این عدد را شامل نمیشود.)
- step: فاصله ی میان اعداد در بازه که به طور پیش فرض یک است.
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
مثال دیگر:
import numpy np
np.arrange(1, 14, 4)
array([ 1, 5, 9, 13])
numpy.linspace و numpy.logspace در پایتون
این تابع نیز دنباله ای از اعداد را تولید میکند و قاعده ی تعریف آن به صورت زیر است:numpy.linspace(start, stop, num, endpoint)
start: مقدار شروع دنباله.
stop: مقدار پایان دنباله (خود مقدار پایانی در نظر گرفته میشود.)
num: تعداد اعداد مورد نظر که مقدار پیش فرض 50 را دارد.
endpoint: اگر True باشد، (که به طور پیش فرض هست) مقدار stop را به عنوان مقدار نهایی درنظرمی گیرد و اگر False بود آن را در نظر نمیگیرد.
به عنوان مثال میتوان ده مقدار با فاصله ی یکسان در بازه ی 1 تا 5 به شکل زیر تولید کرد:
import numpy as np
np.linspace(1.0, 5.0, num=10)array([1. , 1.44444444, 1.88888889, 2.33333333, 2.77777778, 3.22222222, 3.66666667, 4.11111111, 4.55555556, 5. ])
اگر نمیخواهید آخرین عدد در بازه جزو اعداد تولیدی باشد، همان طور که گفته شد مقدار endpoint را برابر False قرار دهید:
np.linspace(1.0, 5.0, num=5, endpoint=False)array([1. , 1.8, 2.6, 3.4, 4.2])
np.logspace هم مشابه linspace عمل میکند با این تفاوت که توان اعداد را محاسبه میکند و پایه به طور پیش فرض برابر عدد 10 است. قاعده ی آن به شکل زیر است:numpy.logspace(start, stop, num, endpoint)حالات مختلف را با مثالهای زیر بررسی میکنیم:
np.logspace(3.0, 4.0, num=4)array([ 1000. , 2154.43469003, 4641.58883361, 10000. ])
np.logspace(4.0, 5.0, num=3, endpoint=False)array([ 10000. , 21544.34690032, 46415.88833613])
np.logspace(4.0, 5.0, num=3, base=2.0)array([ 16. , 22.627417, 32. ])
اندیس دهی (Indexing) و برش (Slicing) آرایههای NumPy در پایتون
برش ماتریس و یا آرایه توسط NumPy کار ساده ای است. به مثالهای زیر توجه کنید:
## Slice
import numpy as np
e = np.array([(1,2,3), (4,5,6)])
print(e)
[[1 2 3], [4 5 6]]
print('First row:', e[0])
print('Second row:', e[1])
First row: [1 2 3] Second row: [4 5 6]
یادآوری: در زبان پایتون داریم:
- مقدار قبل از کاما در براکت، به سطر اشاره میکند.
- مقدار سمت راست کاما به ستون اشاره میکند.
- اگر بخواهید تنها ستون را انتخاب کنید، قبل از شماره ی ستون باید دو نقطه (:) قرار دهید [ :column_index] .
- دو نقطه [ :column_index] به این معنی است که شما تمامی سطرهای آن ستون را انتخاب کرده اید.
print('Second column:', e[:,1])Second column: [2 5]
برای برگرداندن دو مقدار اول از سطر دوم (اندیس یکم) آرایه ی e دستور را به شکل زیر مینویسند: (توجه کنید باید دو نقطه را قرار دهید تا همه ی مقادیر پیش از ستون سوم یعنی اندیس دوم، با اندیسهای صفر و یک، انتخاب شوند.)
## Second Row, two values
print(e[1, :2])
#result
[4 5]
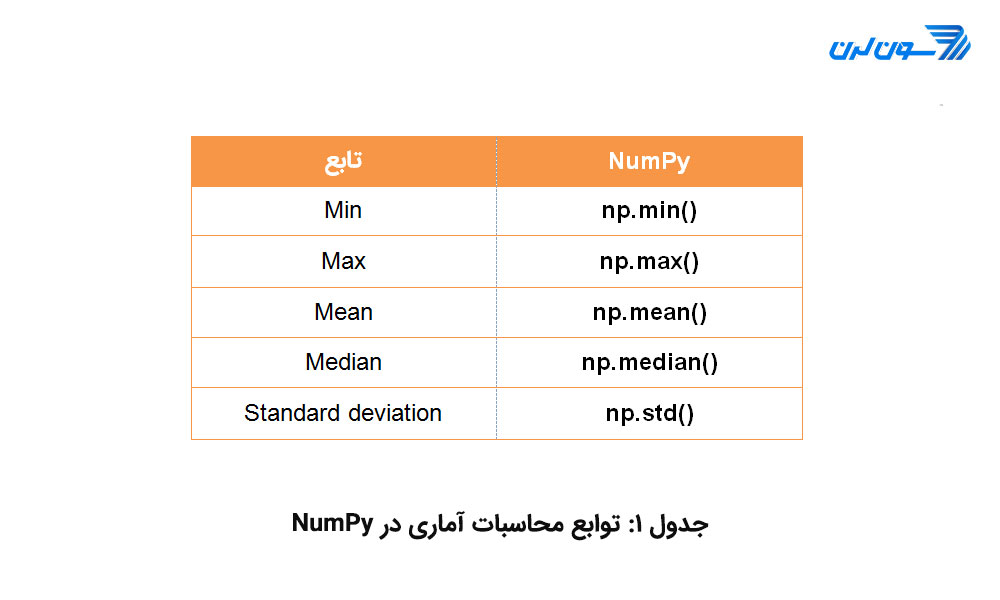
توابع آماری NumPy
این کتابخانه تعدادی تابع آماری برای محاسبه ی مواردی همچون مینیمم، ماکزیمم، میانگین، میانه، دهک و صدک، انحراف معیار، واریانس و ... برای اعمال روی آرایهها و ماتریسهای ورودی دارد. در جدول زیر برخی از این توابع آمده اند:
 آرایه ی زیر را در نظر بگیرید:
آرایه ی زیر را در نظر بگیرید:
import numpy as np
normal_array = np.random.normal(5, 0.5, 10)
print(normal_array)
[5.56171852 4.84233558 4.65392767 4.946659 4.85165567 5.61211317 4.46704244 5.22675736 4.49888936 4.68731125]
توابع آماری را روی دادههای تولید شده به شکل زیر اعمال میکنیم:
### Min
print(np.min(normal_array))
### Max
print(np.max(normal_array))
### Mean
print(np.mean(normal_array))
### Median
print(np.median(normal_array))
### Std
print(np.std(normal_array))
4.467042435266913 5.612113171990201 4.934841002270593 4.846995625786663 0.3875019367395316
ضرب در پایتون به کمک NumPy
numpy.dot ضرب نقطه ای بین ماتریسها یا همان ضرب ماتریسی را انجام میدهد. قاعده ی کلی به شکل زیر است:
numpy.dot(x, y, out=None)x و y آرایه ی ورودی اند که باید 1D یا 2D (یک بُعدی یا دو بُعدی) باشند. خروجی اگر ورودی آرایه یک بعدی باشد، مقدار اسکالر و در غیر این صورت یک آرایه است. به مثال زیر توجه کنید:
## Linear algebra
### Dot product: product of two arrays
f = np.array([1,2])
g = np.array([4,5])
### 1*4+2*5
np.dot(f, g)
14
اگر ورودیها به صورت اسکالر باشند و یا ضرب عضو به عضو اعضای آرایهها مدنظر باشد از numpy.multiply میتوان استفاده کرد. اما اگر ضرب ماتریسی برای آرایههای دوبعدی میخواهیم انجام دهیم، numpy.matmul ترجیح داده میشود.
تفاوت میان Copy و View در NumPy
تفاوت میان یک کپی و یک view از یک آرایه در این است که کپی یک آرایه ی جدید است اما؛ view فقط یک دید از آرایه ایجاد میکند. کپی مسئول دادههای خود است و هر گونه تغییر داده در آن، مستقل از آرایه ی اولیه است و بالعکس، هر تغییری در آرایه ی اولیه در کپی آن بی تأثیر است. درمورد view، این قضیه صادق نیست و تغییرات دادهها در view و آرایه ی اولیه بر یکدیگر اثر میگذارد.
Copy
یک کپی از آرایه ایجاد میکنیم و تغییرات آرایه و کپی آن را بر همدیگر مشاهده میکنیم:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
x = arr.copy()
arr[0] = 42
print(arr)
print(x)[42 2 3 4 5] [1 2 3 4 5]
View
یک view از آرایه ایجاد میکنیم و تغییرات آرایه و view آن را بر همدیگر مشاهده میکنیم:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
x = arr.view()
x[0] = 31
print(arr)
print(x)[31 2 3 4 5] [31 2 3 4 5]
همان طور که گفته شد کپی بر دادههای خود مالکیت دارد اما view نه. برای بررسی مالکیت آرایه ای درNumPy ، میتوان مقدار ویژگی base آن را بررسی کرد. اگر None بود، یعنی مالکیت دارد و اگر به آبجکت (Object) اصلی و اولیه اشاره کرد یعنی مالکیت ندارد.
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
x = arr.copy()
y = arr.view()
print(x.base)
print(y.base)None [1 2 3 4 5]
نتیجه گیری
در مقاله ی آموزش کامل کتابخانه NumPY ، با توجه به اهمیت انجام محاسبات در علم داده با توابع کتابخانه ی NumPy که از پکیجهای اساسی در ساخت سایر پکیجهای داده کاوی با پایتون است، آشنا شدیم. NumPy به عنوان کتابخانه ای با استفاده ی گسترده در محاسبات نقشی مهم در سایر کتابخانههای محاسباتی پایتون همچون sikit-learn ،tensorflow ،matplot ،opencv و... دارد. داشتن درک درستی از این کتابخانه در فهم سایر کتابخانههای پیشرفتهتر بسیار مفید خواهد بود. بی صبرانه منتظر نظرات شما خوانندگان عزیز هستیم و امیدواریم همراه ما در ادامه ی مباحث مقالات آموزشی علم داده باشید.


۲۹ دیدگاه
سولماز
۲۴ آبان ۱۴۰۲، ۰۵:۵۴
نازنین کریمی مقدم
۲۴ آبان ۱۴۰۲، ۰۷:۱۷
۲۵ تیر ۱۴۰۲، ۱۹:۵۷
۱۹ خرداد ۱۴۰۲، ۱۲:۳۹
نازنین کریمی مقدم
۲۵ خرداد ۱۴۰۲، ۱۹:۵۵
۰۹ بهمن ۱۴۰۱، ۰۶:۱۳
نازنین کریمی مقدم
۱۰ بهمن ۱۴۰۱، ۰۵:۴۱
۲۶ آذر ۱۴۰۱، ۱۶:۱۸
نازنین کریمی مقدم
۲۷ آذر ۱۴۰۱، ۰۶:۲۱
۱۷ تیر ۱۴۰۱، ۱۲:۳۶
نازنین کریمی مقدم
۱۸ تیر ۱۴۰۱، ۰۶:۱۸
۰۲ فروردین ۱۴۰۱، ۱۷:۵۷
علی وحیدی
۱۷ مرداد ۱۴۰۰، ۱۵:۱۰
mohamad
۱۳ مرداد ۱۴۰۰، ۰۳:۳۱
نازنین کریمی مقدم
۱۷ مرداد ۱۴۰۰، ۱۱:۵۱
Amirraza
۲۳ اردیبهشت ۱۴۰۰، ۰۳:۳۲
نازنین کریمی مقدم
۲۴ اردیبهشت ۱۴۰۰، ۲۲:۳۶
alireza
۰۹ بهمن ۱۳۹۹، ۱۸:۵۲
نازنین کریمی مقدم
۱۸ بهمن ۱۳۹۹، ۰۹:۴۰
m
۱۳ آذر ۱۳۹۹، ۱۵:۵۰
رامین
۱۲ آبان ۱۳۹۹، ۰۸:۳۶
نازنین کریمی مقدم
۱۲ آبان ۱۳۹۹، ۱۱:۲۴
Sahar
۲۵ مهر ۱۳۹۹، ۱۰:۱۲
نازنین کریمی مقدم
۲۷ مهر ۱۳۹۹، ۰۰:۱۲
سیران
۱۰ تیر ۱۳۹۹، ۱۴:۱۵
المیرا ناصح
۲۱ شهریور ۱۳۹۹، ۰۹:۲۸
mostafa
۰۳ تیر ۱۳۹۹، ۱۱:۱۴
نازنین کریمی مقدم
۱۹ شهریور ۱۳۹۹، ۲۰:۲۹
آنیس
۲۷ اردیبهشت ۱۳۹۹، ۱۹:۲۰

دوره الفبای برنامه نویسی با هدف انتخاب زبان برنامه نویسی مناسب برای شما و پاسخگویی به سوالات متداول در شروع یادگیری موقتا رایگان شد: