۰
دیدگاه
نظر

راهنمای سئو برای مبتدی ها: موتورهای جستجو چطور کار می کنند؟
سرفصلهای مقاله
- موتورهای جستجو چطور کار میکنن؟
- خزش در موتورهای جستجو یعنی چی؟
- ایندکس موتور جستجو چیه؟
- رتبه بندی موتور جستجو
- آیا موتورهای جستجو میتونن صفحات سایتت رو پیدا کنن؟
- چرا سایتت توی نتایج جستجو نیست؟
- به موتورهای جستجو بگو چطور سایتت رو خزش کنن
- ایندکس شدن: موتورهای جستجو چطور صفحاتت رو تفسیر و ذخیره میکنن؟
- چطور به موتورهای جستجو بگیم سایت ما رو چطور ایندکس کنن؟
- چطور موتورهای جستجو URLها رو رتبه بندی میکنن؟
- نقش لینکها در سئو
- جستجوی محلی
- سوالات متداول
- جمع بندی
اول از همه، باید دیده بشی!
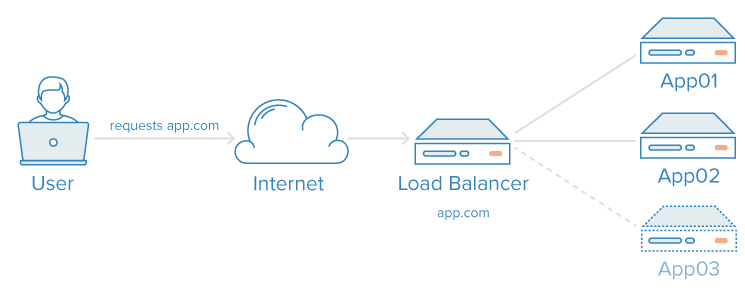
همونطور که توی مقاله اول (راهنمای سئو برای مبتدیها (پارت 1)) گفتیم، موتورهای جستجو مثل ماشینهای جواب گویی هستن. اونا وجود دارن تا محتوای اینترنت رو کشف، فهم و مرتب کنن تا وقتی کسی یه سوال داره، بهترین جواب رو بهش بدن.
برای اینکه سایتت توی نتایج جستجو نمایش داده بشه، اولین قدم اینه که محتوات برای موتورهای جستجو قابل دیدن باشه. این مهمترین قسمت از معمای سئوئه: اگه سایتت پیدا نشه، عمراً بتونی توی نتایج جستجو (SERP) دیده بشی.
موتورهای جستجو چطور کار میکنن؟
موتورهای جستجو سه تا کار اصلی انجام میدن:
- خزش (Crawling): اینترنت رو زیر و رو میکنن تا محتوای جدید پیدا کنن. کدها و محتوای هر URL رو بررسی میکنن.
- ایندکس کردن (Indexing): محتوایی رو که طی خزش پیدا کردن، ذخیره و سازماندهی میکنن. وقتی یه صفحه توی ایندکس قرار گرفت، یعنی آماده ست که به عنوان یه نتیجه مرتبط به کاربر نشون داده بشه.
- رتبه بندی (Ranking): محتوایی که بیشترین ارتباط رو با سوال کاربر داره، به ترتیب از مرتبطترین تا کم ارتباطترین نشون میدن.
خزش در موتورهای جستجو یعنی چی؟
خزش همون فرآیند کشف محتوای جدیده که توش موتورهای جستجو یه تیم از رباتها (بهشون خزنده یا عنکبوت هم میگن) رو میفرستن تا محتوای جدید و آپدیت شده رو پیدا کنن. این محتوا میتونه هر چیزی باشه؛ از یه صفحه وب گرفته تا عکس، ویدیو یا حتی فایل PDF.
گوگل بات (خزنده گوگل) کارش رو با بررسی چند صفحه وب شروع میکنه و بعد از طریق لینک هایی که توی اون صفحات هست، به صفحات جدید میرسه. با دنبال کردن این لینک ها، گوگل بات میتونه محتوای جدید پیدا کنه و اونو توی یه ایندکس بزرگ به نام "کافئین" ذخیره کنه. این ایندکس، یه پایگاه داده عظیم از URLهای کشف شده ست که بعداً وقتی کسی چیزی جستجو میکنه، گوگل میتونه ازش استفاده کنه و نتایج مرتبط رو به کاربر نشون بده.
پیشنهاد میکنم یه سر به مقاله خزنده وب چیست؟ بزنی تا بیشتر با این رباتهای کوچولو و نحوه کارشون آشنا بشی 🕷🕸
ایندکس موتور جستجو چیه؟
موتورهای جستجو اطلاعاتی که پیدا میکنن رو توی یه ایندکس ذخیره میکنن. این ایندکس در واقع یه پایگاه داده خیلی بزرگه که شامل همه محتواییه که موتورهای جستجو کشف کردن و اونقدر خوب تشخیص دادن که برای نمایش به کاربرا مناسب باشه.

رتبه بندی موتور جستجو
وقتی کسی یه چیزی رو جستجو میکنه، موتورهای جستجو ایندکس خودشون رو زیر و رو میکنن تا محتوای مرتبط با جستجوی کاربر رو پیدا کنن. بعد این محتواها رو به ترتیب از مرتبطترین تا کم ارتباطترین میچینن. این فرآیند مرتب کردن نتایج بر اساس میزان ارتباط به سوال کاربر، همون رتبه بندی هست. به طور کلی، هرچی سایتت بالاتر باشه، یعنی موتور جستجو فکر میکنه که محتوای سایتت برای اون جستجو مرتبط تره.
البته میتونی موتورهای جستجو رو از دسترسی به بخشی از سایتت منع کنی یا بگی که یه سری صفحات رو توی ایندکس ذخیره نکنن. ولی اگه میخوای محتوای سایتت توی نتایج جستجو پیدا بشه، باید مطمئن شی که محتوای سایتت قابل دسترسی و ایندکس شدن باشه. وگرنه انگار که اصلاً وجود نداره!
توی دنیای سئو، همه موتورهای جستجو برابر نیستن!
خیلی از کسایی که تازه وارد سئو میشن، میپرسن که بهینه سازی برای کدوم موتور جستجو مهم تره؟ بیشتر مردم میدونن که گوگل سهم بازار بیشتری داره، ولی آیا باید برای بینگ، یاهو و بقیه هم بهینه سازی کنیم؟
واقعیت اینه که با اینکه بیش از 30 موتور جستجوی مهم وجود داره، جامعه سئو بیشتر توجهش به گوگله. چرا؟ چون بیشتر مردم از گوگل برای جستجو استفاده میکنن. اگه گوگل ایمیجز، گوگل مپس و یوتیوب (که همشون متعلق به گوگلن) رو هم حساب کنیم، بیش از 90 درصد جستجوهای اینترنتی توی گوگل انجام میشه – یعنی تقریباً 20 برابر بیشتر از بینگ و یاهو با هم!
آیا موتورهای جستجو میتونن صفحات سایتت رو پیدا کنن؟
همون طور که یاد گرفتی، مطمئن شدن از اینکه سایتت خزیده و ایندکس بشه، اولین قدم برای دیده شدن توی نتایج جستجوئه. اگه قبلاً سایتت رو راه اندازی کردی، شاید بهتره اول ببینی چند تا از صفحاتت توی ایندکس گوگل هستن. این کار بهت یه دید کلی میده که آیا گوگل همه صفحاتی که میخواستی رو خزیده و ایندکس کرده یا نه.
یه راه ساده برای چک کردن صفحات ایندکس شدت استفاده از اپراتور جستجوی پیشرفته "site:yourdomain.com" توی گوگله. فقط کافیه توی نوار جستجوی گوگل بنویسی "site:yourdomain.com" تا نتایج سایتت که توی ایندکس گوگل هستن برگرده.
تعداد نتایجی که گوگل نشون میده، دقیق نیست، ولی بهت یه ایده کلی میده که کدوم صفحات ایندکس شدن و چطور توی نتایج جستجو نمایش داده میشن.
برای نتایج دقیق تر، میتونی از Index Coverage report توی گوگل سرچ کنسول استفاده کنی. اگه هنوز حساب گوگل سرچ کنسول نداری، میتونی رایگان ثبت نام کنی. با این ابزار، میتونی نقشه سایتت رو ارسال کنی و ببینی که چند تا از صفحات ارسالی واقعاً توی ایندکس گوگل قرار گرفتن.
چرا سایتت توی نتایج جستجو نیست؟
اگه هیچ اثری از سایتت توی نتایج جستجو نیست، ممکنه به یکی از این دلایل باشه:
- سایتت تازه راه اندازی شده و هنوز خزیده نشده.
- سایتت از هیچ سایت دیگه ای لینک نشده.
- ناوبری سایتت برای رباتهای موتور جستجو پیچیده ست و نمیتونن به درستی خزش کنن.
- کدهایی به نام crawler directives توی سایتت هست که جلوی دسترسی موتورهای جستجو رو میگیره.
- سایتت به خاطر استفاده از روشهای اسپم، توسط گوگل جریمه شده.
به موتورهای جستجو بگو چطور سایتت رو خزش کنن
اگه از Google Search Console یا دستور جستجوی پیشرفته "site:yourdomain.com" استفاده کردی و دیدی که بعضی از صفحات مهمت توی ایندکس نیستن یا برعکس، یه سری صفحات غیرضروری اشتباهی ایندکس شدن، میتونی به کمک یه سری بهینه سازیها به گوگل بات بگی که چطور محتوای سایتت رو خزش کنه. این کار بهت کنترل بیشتری روی این میده که چه صفحاتی توی ایندکس قرار بگیرن.
خیلیها فقط به این فکر میکنن که گوگل بتونه صفحات مهمشون رو پیدا کنه، اما شاید یادت بره که یه سری صفحات هستن که اصلاً نمیخوای گوگل بات بهشون دسترسی داشته باشه. این صفحات میتونن شامل URLهای قدیمی با محتوای کم ارزش، URLهای تکراری (مثلاً فیلترها و دسته بندیهای محصولات توی سایتهای فروشگاهی)، صفحات مخصوص کدهای تخفیف، صفحات تست یا استیجینگ و غیره باشن.
برای اینکه گوگل بات رو از خزش بعضی صفحات دور کنی، از فایل robots.txt استفاده کن.
robots.txt چیه؟
فایل robots.txt توی دایرکتوری اصلی سایت قرار میگیره (مثلاً yourdomain.com/robots.txt) و به موتورهای جستجو میگه که کدوم بخشهای سایت رو باید یا نباید خزش کنن. همچنین میتونی با استفاده از دستورهای مخصوص توی robots.txt سرعت خزش رو هم تنظیم کنی.
گوگل بات چطور با robots.txt برخورد میکنه؟
- اگه گوگل بات نتونه فایل robots.txt رو پیدا کنه، شروع به خزش سایت میکنه.
- اگه فایل robots.txt رو پیدا کنه، معمولاً از دستورهای موجود توی اون پیروی میکنه و بعدش سایت رو خزش میکنه.
- اگه موقع دسترسی به فایل robots.txt با خطا مواجه بشه و نتونه بفهمه که فایل موجود هست یا نه، سایت رو خزش نمیکنه.
بهینه سازی بودجه خزش (Crawl Budget)
بودجه خزش، میانگین تعداد URLهایی هست که گوگل بات قبل از ترک سایتت خزش میکنه. بهینه سازی بودجه خزش باعث میشه که گوگل بات وقتش رو برای خزش صفحات غیرضروری تلف نکنه و بتونه صفحات مهمت رو بهتر بررسی کنه. این موضوع مخصوصاً توی سایتهای خیلی بزرگ با هزاران URL اهمیت داره، ولی حتی اگه سایت کوچیکی داری، بد نیست مطمئن بشی که خزندهها به محتوایی که برات مهم نیست دسترسی پیدا نمیکنن.
فقط حواست باشه که صفحات مهمی که دستورهای دیگه ای مثل canonical یا noindex دارن رو اشتباهی مسدود نکنی، چون اگه گوگل بات نتونه به یه صفحه دسترسی پیدا کنه، نمیتونه دستورهایی که توش گذاشتی رو هم ببینه.
برای این که بیشتر با Crawl Budget آشنا بشی یه سر به این مقاله بزن:
همه رباتهای وب از robots.txt پیروی نمیکنن
ربات هایی که نیت بد دارن (مثل رباتهای جمع آوری آدرس ایمیل) معمولاً از این پروتکل پیروی نمیکنن. حتی بعضی از افراد بد از فایل robots.txt استفاده میکنن تا بفهمن محتوای خصوصی سایتت کجاست. ممکنه به نظرت منطقی بیاد که رباتها رو از صفحات خصوصی مثل صفحه ورود یا بخش مدیریت دور نگه داری تا این صفحات توی ایندکس ظاهر نشن، اما وقتی مکان این صفحات رو توی فایل robots.txt قرار میدی، افراد با نیت بد راحتتر میتونن بهشون دسترسی پیدا کنن. به جای این کار، بهتره اون صفحات رو با تگ NoIndex از ایندکس گوگل خارج کنی و اونا رو پشت فرم ورود قفل کنی، نه اینکه توی فایل robots.txt بذاری.
تعریف پارامترهای URL در گوگل سرچ کنسول
توی بعضی سایت ها، مخصوصاً سایتهای فروشگاهی، ممکنه همون محتوای اصلی با URLهای مختلفی نمایش داده بشه. این کار معمولاً با اضافه کردن یه سری پارامتر به انتهای URL انجام میشه. اگه تا حالا آنلاین خرید کرده باشی، احتمالش زیاده که برای پیدا کردن محصول موردنظرت از فیلترها استفاده کرده باشی. مثلاً توی دیجی کالا دنبال "کفش" گشتی و بعدش نتایج رو بر اساس سایز، رنگ یا مدل محدود کردی. هر بار که فیلترها رو تغییر میدی، URL هم کمی تغییر میکنه:
مثال:
https://www.example.com/products/women/dresses/green.htm
https://www.example.com/products/women?category=dresses&color=green
https://example.com/shopindex.php?product_id=32&highlight=green+dress&cat_id=1&sessionid=123$affid=43 حالا سوال اینه که گوگل چطور میفهمه کدوم نسخه از این URLها رو باید به کاربرا نشون بده؟ گوگل معمولاً خودش کارش رو خوب انجام میده و URL اصلی رو تشخیص میده، ولی با استفاده از ویژگی URL Parameters توی گوگل سرچ کنسول میتونی به گوگل دقیقاً بگی که با صفحات سایتت چطور برخورد کنه. اگه از این قابلیت استفاده کنی و به گوگل بات بگی "هیچ URLی با پارامتر ____ رو خزش نکن"، در واقع داری از گوگل میخوای که اون صفحات رو از نتایج جستجو حذف کنه. این کار برای زمانی که پارامترها باعث ایجاد صفحات تکراری میشن عالیه، ولی اگه میخوای اون صفحات توی ایندکس باشن، ایده خوبی نیست.
آیا خزندهها میتونن همه محتوای مهمت رو پیدا کنن؟
حالا که یاد گرفتی چطور مطمئن بشی موتورهای جستجو از محتوای غیرضروری دور بمونن، وقتشه که درباره بهینه سازی هایی صحبت کنیم که به گوگل بات کمک میکنن صفحات مهمت رو پیدا کنه.
گاهی موتورهای جستجو میتونن بعضی بخشهای سایتت رو خزش کنن، ولی شاید نتونن به همه صفحات یا بخشهای دیگه برسن، به هر دلیلی. خیلی مهمه که مطمئن بشی موتورهای جستجو میتونن همه محتوای موردنظرت رو پیدا و ایندکس کنن، نه فقط صفحه اصلی سایتت.
از خودت بپرس: آیا ربات میتونه داخل سایتت بگرده یا فقط به صفحه اصلی دسترسی داره؟

آیا محتوای سایتت پشت فرمهای ورود مخفی شده؟
اگه برای دسترسی به بعضی از صفحات سایتت از کاربران بخوای که وارد سایت بشن، فرم پر کنن یا به سوالات نظرسنجی جواب بدن، موتورهای جستجو نمیتونن این صفحات محافظت شده رو ببینن. خزندههای موتور جستجو اصلاً وارد حساب کاربری نمیشن!
آیا به فرمهای جستجو متکی هستی؟
رباتهای موتور جستجو نمیتونن از فرمهای جستجو استفاده کنن. بعضیها فکر میکنن اگه یه جعبه جستجو توی سایت بذارن، موتورهای جستجو میتونن هرچی کاربرا جستجو میکنن رو پیدا کنن. اما این طور نیست!
آیا متنت توی محتوای غیرمتنی مخفی شده؟
اگه متنی داری که میخوای موتورهای جستجو ایندکس کنن، نباید اون رو داخل فایلهای تصویری، ویدیویی یا GIF بذاری. هرچند که موتورهای جستجو توی شناسایی تصاویر بهتر شدن، ولی هنوز تضمینی نیست که بتونن متنت رو بخونن و بفهمن. بهترین کار اینه که متنت رو توی کد HTML صفحه بذاری.
آیا موتورهای جستجو میتونن توی سایتت پیمایش کنن؟
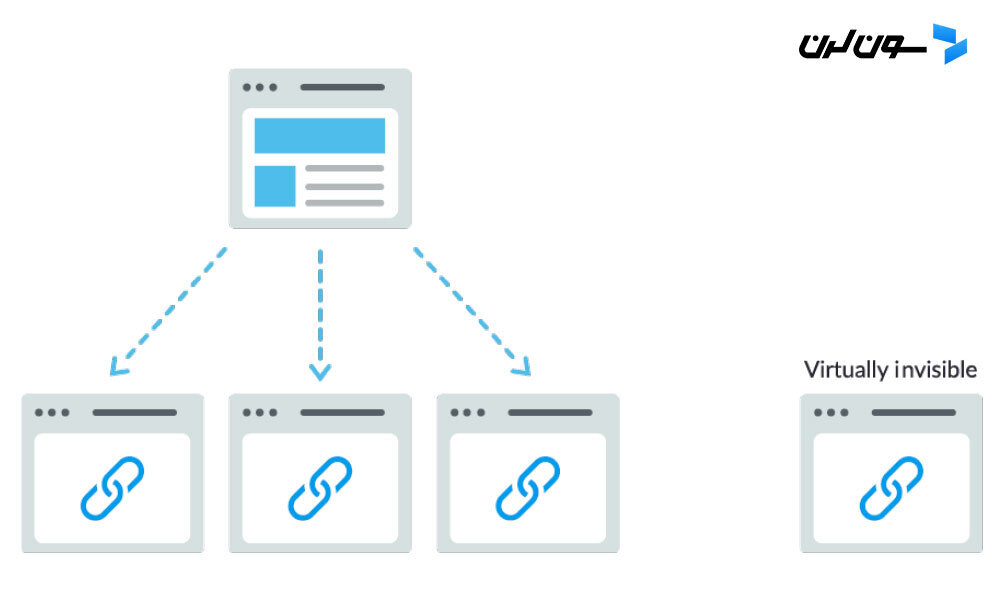
همون طور که خزندهها باید از طریق لینکهای سایتهای دیگه به سایتت برسن، برای پیدا کردن صفحات داخلی سایتت هم به مسیر لینکهای داخلی نیاز دارن. اگه صفحه ای داری که میخوای موتورهای جستجو پیداش کنن، ولی از هیچ صفحه دیگه ای بهش لینک ندادی، در واقع مثل اینه که اون صفحه وجود نداره! خیلی از سایتها این اشتباه مهم رو میکنن که ناوبری سایتشون رو طوری طراحی میکنن که برای موتورهای جستجو قابل دسترس نیست و این باعث میشه نتونن توی نتایج جستجو ظاهر بشن.
اشتباهات رایجی که ممکنه دسترسی خزندهها به سایتت رو محدود کنه:
- داشتن منوی ناوبری موبایل که نتایج متفاوتی نسبت به نسخه دسکتاپ نشون میده.
- هر نوع ناوبری ای که آیتمهای منو رو توی HTML نداشته باشه، مثل ناوبریهای مبتنی بر جاوااسکریپت. درسته که گوگل توی خزش و درک جاوااسکریپت بهتر شده، ولی همچنان یه فرآیند کامل و بی نقص نیست. بهترین راه برای اینکه مطمئن بشی محتوایی که داری پیدا، فهمیده و ایندکس میشه، اینه که اونو توی HTML بذاری.
- شخصی سازی ناوبری برای کاربران خاص ممکنه از دید خزندهها مثل تکنیکهای مخفی کاری (Cloaking) به نظر برسه.
- فراموش کردن لینک دادن به صفحات اصلی سایتت از طریق ناوبری.
به همین دلیله که داشتن یه ناوبری شفاف و ساختار پوشه ای مفید برای URLها توی سایت خیلی مهمه.
معماری اطلاعات سایتت منظم و تمیزه؟
معماری اطلاعات یعنی اینکه محتوای سایتت رو طوری دسته بندی و برچسب گذاری کنی که کاربران راحتتر بتونن اون چیزی که میخوان رو پیدا کنن. یه معماری اطلاعات خوب باید طوری باشه که کاربران بدون فکر کردن زیاد بتونن توی سایت بچرخن و به خواسته شون برسن.
از نقشه سایت استفاده میکنی؟
نقشه سایت دقیقاً همون چیزیه که به نظر میاد: یه لیست از URLهای سایت که موتورهای جستجو میتونن ازش برای پیدا کردن و ایندکس کردن محتوای سایت استفاده کنن. یکی از راحتترین روشها برای اینکه مطمئن شی گوگل صفحات مهم سایتت رو پیدا میکنه، اینه که یه فایل استاندارد برای نقشه سایت بسازی و اون رو از طریق گوگل سرچ کنسول ارسال کنی. درست کردن نقشه سایت جایگزین ناوبری خوب توی سایت نیست، ولی قطعاً میتونه کمک کنه خزندهها راحتتر به صفحات مهم برسن.
یادت باشه که فقط URLهایی رو توی نقشه سایت بذاری که میخوای موتورهای جستجو ایندکس کنن و همیشه دستورهای یکسانی به خزندهها بدی. مثلاً نباید URLی که توی robots.txt بلاک کردی رو توی نقشه سایت بذاری، یا URLهای تکراری رو توی نقشه سایت بذاری، چون باید فقط نسخه اصلی (canonical) رو بذاری. (توی مقالات بعدی بیشتر درباره canonicalization صحبت میکنیم.)
اگه سایتت لینکهای ورودی زیادی نداره، میتونی از طریق ارسال نقشه سایت به گوگل سرچ کنسول همچنان شانس ایندکس شدن داشته باشی. هرچند هیچ تضمینی نیست که گوگل همه URLهای ارسالی رو ایندکس کنه، ولی امتحانش ضرر نداره!
حتما مقاله "سایت مپ چیست؟" رو هم بخونی تا بیشتر با این مفهوم آشنا بشی.
خزندهها موقع دسترسی به URLهات خطا میگیرن؟
توی فرآیند خزش سایت، ممکنه خزندهها به خطاهایی بر بخورن. میتونی به گزارش خطاهای خزش توی گوگل سرچ کنسول سر بزنی تا URLهایی که ممکنه این مشکل رو داشته باشن پیدا کنی. این گزارش بهت خطاهای سرور و خطاهای "صفحه پیدا نشد" رو نشون میده. فایلهای لاگ سرور هم میتونن این اطلاعات رو بهت بدن، به علاوه کلی اطلاعات دیگه مثل تعداد دفعات خزش. البته دسترسی به این فایلها و تجزیه وتحلیلشون یه کار پیشرفته تره که توی این راهنمای مبتدی خیلی بهش نمیپردازیم.
قبل از اینکه بخوای کاری روی گزارش خطاهای خزش انجام بدی، لازمه که مفهوم خطاهای سرور و خطاهای "Not Found" رو خوب بفهمی.
کدهای 4xx: وقتی خزندههای موتور جستجو نمیتونن به محتوای سایتت دسترسی پیدا کنن به خاطر خطای کاربر
کدهای 4xx نشون دهنده خطاهای کاربری هستن؛ یعنی URL درخواستی یا اشتباهه یا به دلیلی نمیشه بهش دسترسی پیدا کرد. یکی از رایجترین خطاهای 4xx، خطای "404 – not found" هست. این خطا ممکنه به خاطر اشتباه توی تایپ URL، حذف صفحه یا ریدایرکت خراب باشه. وقتی موتورهای جستجو با خطای 404 روبرو میشن، نمیتونن به اون URL دسترسی داشته باشن. و وقتی کاربرا با این خطا روبرو میشن، معمولاً ناامید میشن و سایتت رو ترک میکنن.
کدهای 5xx: وقتی خزندههای موتور جستجو به خاطر خطای سرور نمیتونن به محتوای سایتت دسترسی پیدا کنن
کدهای 5xx نشون دهنده خطاهای سروری هستن؛ یعنی سروری که صفحه وب روی اون قرار داره نتونسته درخواست کاربر یا موتور جستجو برای دسترسی به صفحه رو انجام بده. توی گزارش "خطاهای خزش" گوگل سرچ کنسول یه تب مخصوص به این خطاها اختصاص داده شده. این خطاها معمولاً به خاطر تایم اوت شدن درخواست URL اتفاق میافتن و گوگل بات درخواست رو رها میکنه. برای اطلاعات بیشتر درباره حل مشکلات ارتباطی سرور، میتونی مستندات گوگل رو بخونی.
خوشبختانه یه راه حل برای این مشکل وجود داره: ریدایرکت 301 که هم به کاربران و هم به موتورهای جستجو اطلاع میده که صفحه به آدرس جدید منتقل شده.
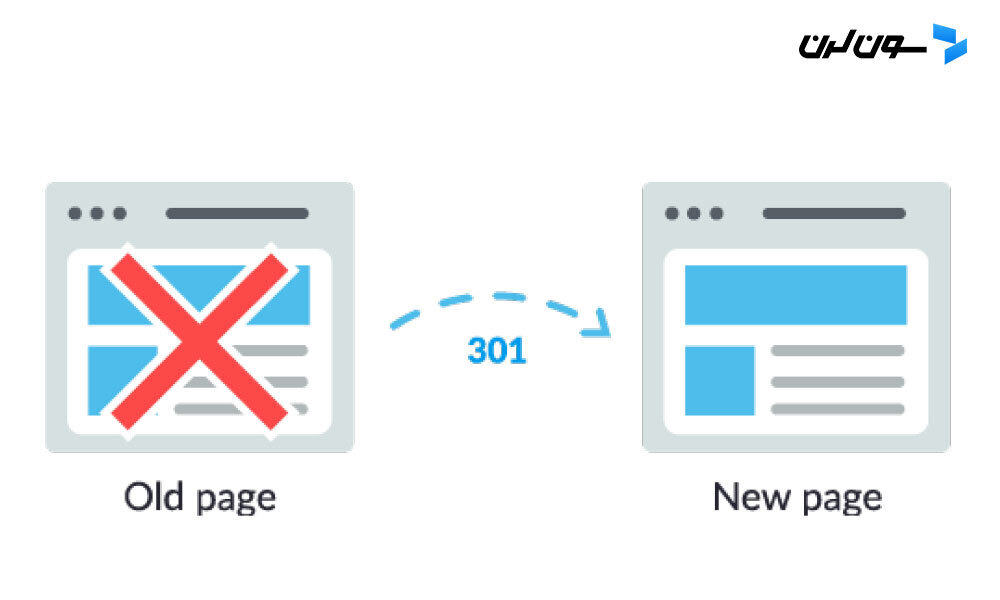
مثلاً فرض کن یه صفحه رو از example.com/young-dogs/ به example.com/puppies/ منتقل میکنی. موتورهای جستجو و کاربرا نیاز دارن یه پلی داشته باشن که از آدرس قدیمی به آدرس جدید برسن. این پل همون ریدایرکت 301 هست.
وقتی از ریدایرکت 301 استفاده میکنی:
- انتقال اعتبار لینک ها: اعتبار و قدرت لینکها از آدرس قدیمی به آدرس جدید منتقل میشه.
- ایندکس شدن: به گوگل کمک میکنه نسخه جدید صفحه رو پیدا و ایندکس کنه.
- تجربه کاربری: کاربرها به جای برخورد با صفحه خطا، به صفحه ای که دنبالشن هدایت میشن.
وقتی از ریدایرکت 301 استفاده نمیکنی:
- منتقل نشدن اعتبار لینک ها: اگه ریدایرکت 301 نزاری، اعتبار و قدرت URL قبلی به آدرس جدید منتقل نمیشه.
- ایندکس نشدن: خطاهای 404 به تنهایی به سئوی سایت آسیب نمیزنن، ولی اگه صفحات مهمت که رتبه و ترافیک دارن 404 بشن، ممکنه از ایندکس گوگل حذف بشن و رتبه و ترافیکشون رو از دست بدن. خب، این اصلاً خوب نیست!
- تجربه کاربری بد: وقتی کاربرا روی لینکهای خراب کلیک میکنن، به جای رسیدن به صفحه موردنظرشون، به صفحه خطا میرن و این خیلی کلافه کننده ست!
کد وضعیت 301 به این معنیه که صفحه به طور دائمی به یه مکان جدید منتقل شده. پس نباید URLها رو به صفحاتی که ربطی به محتوای قبلی ندارن ریدایرکت کنی — صفحاتی که محتوای قبلی توشون وجود نداره. اگه یه صفحه ای برای یه کلمه کلیدی رتبه داره و تو اونو با 301 به یه URL دیگه با محتوای متفاوت ریدایرکت کنی، ممکنه رتبه اون صفحه پایین بیاد، چون محتوایی که باعث شده اون رتبه رو بگیره دیگه اونجا نیست. ریدایرکت 301 قدرتمنده — پس با دقت و مسئولیت ازش استفاده کن!
همچنین میتونی از ریدایرکت 302 استفاده کنی، ولی این نوع ریدایرکت فقط برای جابه جایی موقتی مناسبه، جایی که انتقال اعتبار لینک خیلی مهم نیست. 302 مثل یه مسیر موقتی برای ترافیک سایت عمل میکنه؛ یعنی به طور موقتی مسیر رو عوض میکنی، ولی برای همیشه این طوری نمیمونه.
مراقب زنجیرههای ریدایرکت باش!
اگه گوگل بات بخواد از چند تا ریدایرکت عبور کنه تا به صفحه برسه، ممکنه کار براش سخت بشه. گوگل به این زنجیرهها میگه "redirect chains" و پیشنهاد میکنه که تا حد امکان اونها رو کم کنی. مثلاً اگه example.com/1 رو به example.com/2 ریدایرکت کنی و بعدش تصمیم بگیری اون رو به example.com/3 ریدایرکت کنی، بهتره که وسطی رو حذف کنی و مستقیماً example.com/1 رو به example.com/3 ریدایرکت کنی.
پیشنهاد میکنم یه سر به مقاله "ریدایرکت چیست؟" بزنی تا بیشتر با ریدایرکتها و انواعشون آشنا بشی.
ایندکس شدن: موتورهای جستجو چطور صفحاتت رو تفسیر و ذخیره میکنن؟
حالا که مطمئن شدی سایتت قابل خزشه، قدم بعدی اینه که مطمئن بشی صفحاتت میتونن ایندکس بشن. فقط به این خاطر که موتور جستجو صفحاتت رو پیدا کرده و خزش کرده، به این معنی نیست که اونا توی ایندکس هم ذخیره میشن.
توی بخش قبلی درباره خزش گفتیم که موتورهای جستجو چطور صفحات وب رو پیدا میکنن. ایندکس جاییه که صفحات کشف شده ذخیره میشن. بعد از اینکه خزنده یه صفحه رو پیدا کرد، موتور جستجو اون رو مثل یه مرورگر رندر میکنه. توی این فرآیند، محتوای صفحه رو تحلیل میکنه و همه این اطلاعات رو توی ایندکسش ذخیره میکنه.

به خوندن ادامه بده تا بیشتر درباره ایندکس شدن یاد بگیری و بفهمی چطور میتونی سایتت رو وارد این دیتابیس مهم کنی!
چطور میتونم ببینم گوگل بات صفحاتم رو چطوری میبینه؟
نسخه ذخیره شده (cached) صفحت یه تصویر لحظه ای از آخرین باریه که گوگل بات اونو خزش کرده.
گوگل صفحات وب رو با فرکانسهای مختلف خزش و ذخیره میکنه. سایتهای معروف و پرطرفدار مثل نیویورک تایمز که مرتباً پست میذارن، خیلی بیشتر از سایتهای کوچیک و ناشناخته ای مثل سایت خیالی کیکهای مورد علاقه راجر موزبات (ای کاش واقعی بود...) خزش میشن!
برای اینکه ببینی نسخه ذخیره شده صفحت چطوریه، میتونی توی نتایج جستجو روی فلش کنار URL کلیک کنی و گزینه "Cached" رو انتخاب کنی:
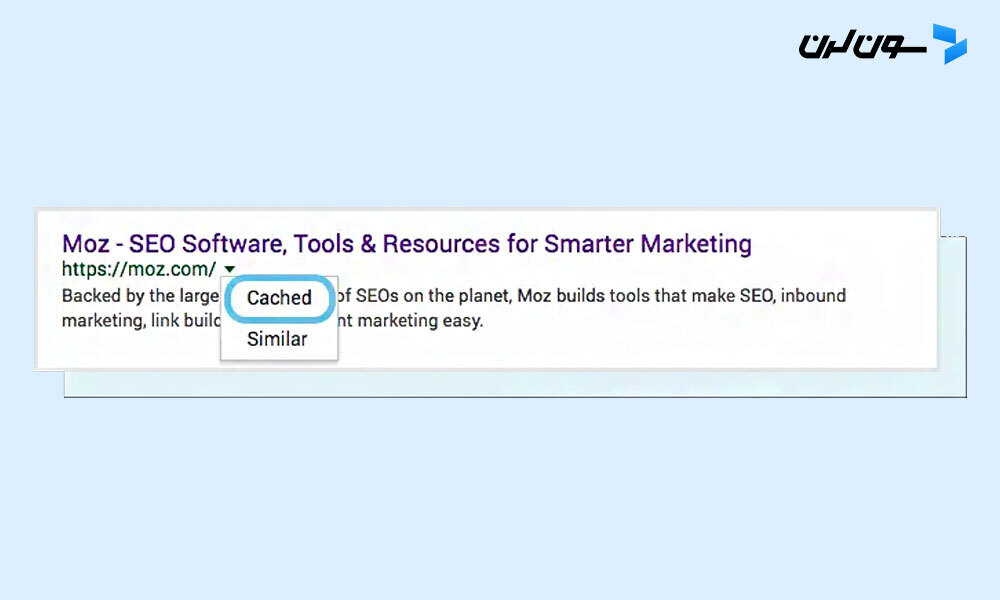
همچنین میتونی نسخه متنی سایتت رو ببینی تا مطمئن بشی محتوای مهمت به درستی خزش و ذخیره شده.
آیا ممکنه صفحات از ایندکس حذف بشن؟
بله، بعضی وقتا صفحات از ایندکس حذف میشن! دلایل اصلی برای حذف URL از ایندکس گوگل میتونه اینها باشه:
- صفحه خطای "یافت نشد" (4XX) یا خطای سرور (5XX) میده: این میتونه به صورت تصادفی اتفاق بیفته (مثلاً صفحه منتقل شده ولی ریدایرکت 301 تنظیم نشده) یا عمدی باشه (مثلاً صفحه حذف شده و خطای 404 داره تا از ایندکس حذف بشه).
- به URL متاتگ noindex اضافه شده: این تگ توسط مدیر سایت گذاشته میشه تا به موتور جستجو بگه صفحه رو ایندکس نکنه.
- URL به دلیل نقض قوانین موتور جستجو جریمه شده: و به صورت دستی از ایندکس حذف شده.
- صفحه به دلیل نیاز به رمز عبور برای دسترسی مسدود شده: یعنی بازدیدکننده باید اول لاگین کنه تا بتونه به صفحه دسترسی داشته باشه.
اگه فکر میکنی یه صفحه از سایتت که قبلاً توی ایندکس گوگل بوده، الان دیگه نمایش داده نمیشه، میتونی از ابزار URL Inspection استفاده کنی تا وضعیت صفحه رو بفهمی، یا از ابزار Fetch as Google استفاده کنی که قابلیت "درخواست ایندکس" برای ارسال URLهای جداگانه به ایندکس رو داره.
نکته: ابزار Fetch گوگل سرچ کنسول همچنین یه گزینه رندر داره که بهت کمک میکنه ببینی آیا گوگل صفحت رو درست تفسیر کرده یا نه.
چطور به موتورهای جستجو بگیم سایت ما رو چطور ایندکس کنن؟
دستورات متا برای ربات ها
استفاده از متا تگها راهیه که باهاش میتونی به موتورهای جستجو بگی چطور با صفحه وبت رفتار کنن.
مثلاً میتونی به خزندههای موتور جستجو بگی: "این صفحه رو توی نتایج جستجو نشون نده" یا "اعتبار لینکهای داخل این صفحه رو انتقال نده". این دستورات از طریق متا تگهای ربات توی تگ <head> صفحات HTML (که رایجترین روشه) یا با استفاده از X-Robots-Tag در هدر HTTP اجرا میشن.
متا تگ Robots
متا تگ Robots رو میتونی توی بخش <head> صفحه HTML استفاده کنی. این تگ میتونه همه موتورهای جستجو یا یه سری موتور خاص رو از خزش و ایندکس صفحه استثنا کنه. بیایید نگاهی به رایجترین دستورات متا و موقعیت هایی که ممکنه ازشون استفاده کنی بندازیم:
- index/noindex به موتورهای جستجو میگه که آیا باید صفحه رو بخزن و توی ایندکس ذخیره کنن یا نه. اگه از "noindex" استفاده کنی، داری به خزندهها میگی این صفحه رو از نتایج جستجو حذف کنن. به طور پیش فرض، موتورهای جستجو فرض میکنن میتونن همه صفحات رو ایندکس کنن، پس استفاده از "index" لازم نیست.
- کجا استفاده میکنی: اگه میخوای یه سری صفحات ضعیف رو از ایندکس گوگل حذف کنی (مثل صفحات پروفایل کاربری)، ولی همچنان میخوای این صفحات برای بازدیدکنندگان قابل دسترس باشن، میتونی از "noindex" استفاده کنی.
- follow/nofollow به موتورهای جستجو میگه آیا لینکهای داخل صفحه رو دنبال کنن یا نه. با "follow"، خزندهها لینکهای صفحه رو دنبال میکنن و اعتبار لینک رو به اون URLها منتقل میکنن. ولی اگه از "nofollow" استفاده کنی، خزندهها لینکهای صفحه رو دنبال نمیکنن و هیچ اعتباری هم منتقل نمیشه. به طور پیش فرض، همه صفحات ویژگی "follow" دارن.
- کجا استفاده میکنی: معمولاً "nofollow" همراه با "noindex" استفاده میشه وقتی که میخوای یه صفحه هم ایندکس نشه و هم خزنده لینکهای داخلش رو دنبال نکنه.
- noarchive به موتورهای جستجو میگه که از صفحه یه نسخه کش شده ذخیره نکنن. به طور پیش فرض، موتورهای جستجو یه کپی قابل مشاهده از همه صفحات ایندکس شده ذخیره میکنن که از طریق لینک کش شده در نتایج جستجو در دسترسه.
- کجا استفاده میکنی: اگه یه سایت فروشگاهی داری و قیمت هات مدام تغییر میکنه، شاید بخوای از تگ "noarchive" استفاده کنی تا کاربرا قیمتهای قدیمی رو توی نتایج جستجو نبینن.
مثال از متا تگ Robots با "noindex" و "nofollow":
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="noindex, nofollow" />
</head>
<body>
...
</body>
</html>این مثال نشون میده که همه موتورهای جستجو از ایندکس کردن این صفحه و دنبال کردن لینکهای داخلش منع میشن. اگه بخوای چندتا خزنده خاص مثل گوگل بات و بینگ رو استثنا کنی، میتونی از چندتا تگ مجزا استفاده کنی.
X-Robots-Tag چیه؟
X-Robots-Tag در هدر HTTP URL استفاده میشه و نسبت به متا تگ ها، انعطاف و کارایی بیشتری داره، به خصوص وقتی بخوای در مقیاس وسیع موتورهای جستجو رو مسدود کنی. با استفاده از این تگ میتونی از عبارات منظم (regular expressions) استفاده کنی، فایلهای غیر HTML رو هم بلاک کنی یا حتی به طور سراسری تگهای noindex بذاری.
مثلاً، میتونی به راحتی پوشهها یا انواع فایلها (مثل فایلهای قدیمی با دستور noindex) رو از ایندکس خارج کنی:
<Files ~ “\/?no\-bake\/.*”> Header set X-Robots-Tag “noindex, nofollow”</Files>حتی میتونی فایل هایی مثل PDF رو هم به طور خاص بلاک کنی:
<Files ~ “\.pdf$”> Header set X-Robots-Tag “noindex, nofollow”</Files>همه دستورات متا تگهای ربات رو میتونی توی X-Robots-Tag هم استفاده کنی. برای اطلاعات بیشتر، پیشنهاد میکنم مستندات Google’s Robots Meta Tag رو مطالعه کنی.
اگه دوست داری مهارت هات توی سئو رو حرفه ای کنی و راه و چاه این دنیای جذاب رو یاد بگیری، پیشنهاد میکنم دوره متخصص سئو سون لرن رو از دست ندی! تو این دوره از صفر تا صد سئو رو یاد میگیری و میتونی خودت رو به یه متخصص واقعی تبدیل کنی.
چطور موتورهای جستجو URLها رو رتبه بندی میکنن؟
موتورهای جستجو چطور مطمئن میشن وقتی کسی یه عبارت رو توی نوار جستجو تایپ میکنه، نتایج مرتبط رو بهش نشون بدن؟ این پروسه به عنوان "رتبه بندی" شناخته میشه، یعنی مرتب سازی نتایج جستجو از بیشترین تا کمترین ارتباط با اون عبارت خاص.

برای تعیین میزان ارتباط، موتورهای جستجو از الگوریتمها استفاده میکنن، یعنی یه فرمول یا فرآیندی که اطلاعات ذخیره شده رو به شکلی معنادار بازیابی و مرتب میکنه. این الگوریتمها طی سالها تغییرات زیادی کردن تا کیفیت نتایج جستجو رو بهبود بدن. مثلاً، گوگل هر روز تغییرات کوچیکی توی الگوریتم هاش اعمال میکنه؛ بعضی هاشون تغییرات کوچیک در کیفیت هستن، اما بعضیها تغییرات بزرگ و اساسی برای رفع مشکلات خاص، مثل الگوریتم پنگوئن برای مقابله با اسپم لینک ها. میتونی توی تاریخچه تغییرات الگوریتمهای گوگل همه این آپدیتهای تأییدشده و تأییدنشده رو از سال ۲۰۰۰ ببینی.
حالا چرا الگوریتم این قدر تغییر میکنه؟ گوگل داره مارو اذیت میکنه؟ خب، گوگل همیشه دلیل دقیق تغییراتش رو نمیگه، اما هدفش از این آپدیتها بهبود کیفیت جستجوئه. برای همین وقتی میپرسن چرا یه الگوریتم رو به روز کرده، معمولاً جوابشون اینه: "ما داریم همیشه کیفیت رو بهبود میدیم." اگه بعد از یه آپدیت، سایتت دچار مشکل شد، بهتره که سایتت رو با دستورالعملهای کیفیت گوگل مقایسه کنی.
موتورهای جستجو چی میخوان؟
موتورهای جستجو همیشه دنبال یه چیز بودن: ارائه جوابهای مفید به سوالات کاربران، اونم به بهترین شکل ممکن. اما اگه این موضوع همیشه بوده، چرا به نظر میاد که سئو الان با گذشته فرق کرده؟
بذار با یه مثال از یادگیری یه زبان جدید برات توضیح بدم. وقتی کسی تازه شروع به یادگیری زبان میکنه، درکش از زبان خیلی ابتداییه. کم کم، این فرد معنی و رابطه بین کلمات رو میفهمه. بعد از یه مدت، با تمرین زیاد حتی میتونه به سوالات مبهم یا ناقص هم جواب بده.
اولین موتورهای جستجو هم همین طوری بودن. خیلی راحت میشد سیستم رو با ترفندهایی که برخلاف دستورالعملهای کیفیت بودن فریب داد. مثلاً یه زمانی اگه میخواستی برای یه کلمه مثل "جوکهای خنده دار" رتبه بگیری، کافی بود این عبارت رو چندین بار توی صفحت تکرار کنی و برجستش کنی، شاید این طوری رتبه بهتری میگرفتی:
به جوکهای خنده دار خوش اومدین! ما خنده دارترین جوکهای دنیا رو داریم. جوکهای خنده دار خیلی باحال و دیوونه کننده ان. جوک خنده دارت اینجاست. بشین و بخون جوکهای خنده دار، چون جوکهای خنده دار میتونن تورو خوشحال و خنده دار کنن. چندتا از خنده دارترین جوکهای موردعلاقه!
این روش تجربه کاربری خیلی بدی ایجاد میکرد. به جای خندیدن به جوک ها، کاربر با یه متن خسته کننده و سخت خوان مواجه میشد. شاید این روش قبلاً جواب میداد، اما هیچ وقت خواسته موتورهای جستجو نبوده.
نقش لینکها در سئو
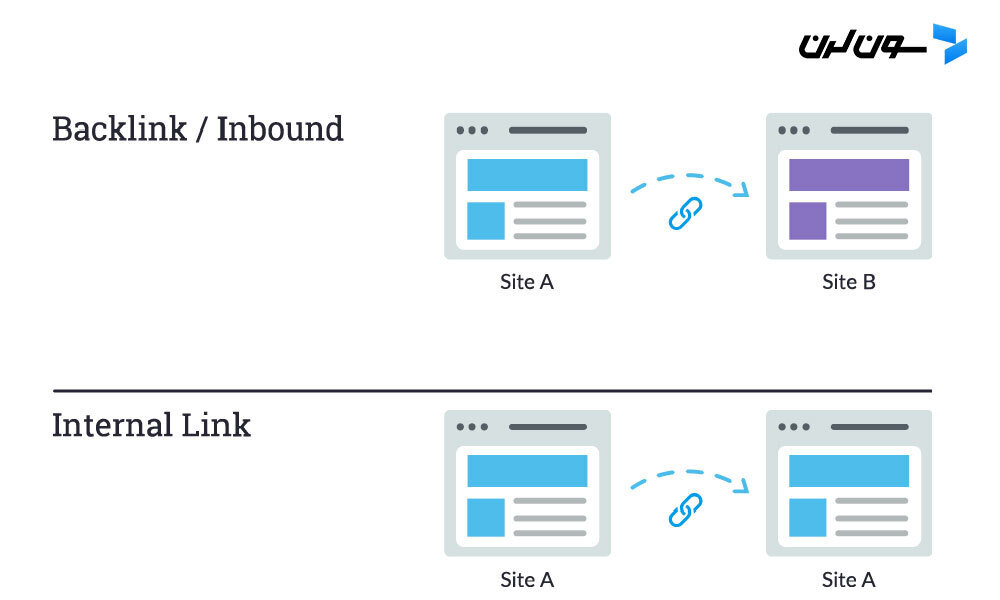
وقتی از لینکها حرف میزنیم، دو نوع لینک رو مدنظر داریم. بک لینکها (یا "لینکهای ورودی") که از سایتهای دیگه به سایت تو اشاره میکنن و لینکهای داخلی که از صفحات سایت خودت به صفحات دیگه توی همون سایت اشاره دارن.
لینکها همیشه نقش بزرگی توی سئو داشتن. اوایل، موتورهای جستجو برای تشخیص اینکه کدوم URLها قابل اعتمادترن، نیاز به کمک داشتن تا بتونن نتایج جستجو رو بهتر رتبه بندی کنن. شمارش لینک هایی که به یه سایت اشاره میکردن، بهشون تو این کار کمک میکرد.
بک لینکها مثل توصیههای زبانی تو دنیای واقعی کار میکنن (همون "Word-of-Mouth"). بیاین یه کافه خیالی به اسم "کافه رز" رو مثال بزنیم:
- توصیههای بقیه = نشونه خوبی از اعتبار
مثال: خیلیها بهت گفتن که "کافه رز" بهترین کافه شهره. - توصیه خودت = سوگیری، پس نشونه خوبی از اعتبار نیست
مثال: خود رز میگه که کافه خودش بهترینه! - توصیه از منابع بی ربط یا کم کیفیت = نشونه بدی از اعتبار و حتی ممکنه باعث اسپم بشه
مثال: رز پول داده که آدمایی که حتی کافش رو ندیدن بگن کافش خوبه. - بدون هیچ توصیه ای = اعتبار نامعلوم
مثال: شاید "کافه رز" خوب باشه، ولی کسی رو پیدا نکردی که نظر بده، پس مطمئن نیستی.
اینجاست که PageRank وارد ماجرا شد. PageRank (که بخشی از الگوریتم اصلی گوگل هست) یه الگوریتم تحلیلی برای لینک هاست که به افتخار یکی از بنیان گذاران گوگل، "لری پیج" نام گذاری شده. PageRank اهمیت یه صفحه وب رو با اندازه گیری کیفیت و تعداد لینک هایی که بهش اشاره میکنن، برآورد میکنه. فرض بر اینه که هر چی یه صفحه وب مرتبط تر، مهمتر و قابل اعتمادتر باشه، لینکهای بیشتری به دست میاره.
هر چی بک لینکهای طبیعی بیشتری از سایتهای معتبر و باکیفیت داشته باشی، شانس بیشتری برای رتبه گیری بالاتر توی نتایج جستجو داری.
نقش محتوا در سئو
اگه لینکها به چیزی اشاره نکنن، واقعاً فایده ای ندارن! و اون "چیز" همون محتواست. محتوا فقط به متن محدود نمیشه؛ بلکه شامل ویدیوها، تصاویر و هر چیزی میشه که مخاطبها میتونن استفاده کنن. اگه بخوایم موتورهای جستجو رو به ماشین جواب دهی تشبیه کنیم، محتوا همون چیزی هست که جوابها رو به دست کاربرها میرسونه.
هر بار که کسی یه جستجو انجام میده، هزاران نتیجه ممکنه وجود داشته باشه. اما چطوری موتورهای جستجو تصمیم میگیرن کدوم صفحهها به درد کاربر میخوره؟ یه بخش مهم از این ماجرا اینه که محتوای صفحه چقدر با هدف جستجوی کاربر هم خوانی داره. یعنی این صفحه چقدر با کلماتی که کاربر جستجو کرده هم خونی داره و چقدر توی انجام کاری که دنبالش بوده بهش کمک میکنه؟
به خاطر همین تمرکز روی رضایت کاربر و رسیدن به هدف، هیچ استاندارد دقیق و مشخصی برای طول محتوا، تعداد کلمات کلیدی یا استفاده از تگهای عنوان وجود نداره. همه اینها ممکنه روی عملکرد صفحه توی جستجو تأثیر بذارن، اما تمرکز اصلی باید روی افرادی باشه که دارن محتواتو میخونن.
امروز، با وجود صدها یا حتی هزاران سیگنال رتبه بندی، سه تا از مهم ترینها همچنان ثابت مونده: لینک هایی که به سایتت اشاره میکنن (به عنوان نشونه ای از اعتبار)، محتوای صفحه (محتوای باکیفیتی که به نیاز کاربر پاسخ میده)، و RankBrain.
RankBrain چیه؟
RankBrain بخش یادگیری ماشینی الگوریتم اصلی گوگله. یادگیری ماشینی یه برنامه کامپیوتریه که با مرور زمان و با دریافت دادههای جدید، پیش بینی هاش رو بهتر و بهتر میکنه. یعنی دائماً در حال یادگیریه و چون دائماً یاد میگیره، نتایج جستجو هم باید همیشه بهبود پیدا کنن.
مثلاً اگه RankBrain ببینه یه صفحه ای با رتبه پایینتر داره نتیجه بهتری برای کاربرا ارائه میده، مطمئن باش اون نتیجه رو بالاتر میبره و اون صفحههای کم ربطتر رو پایینتر میذاره.

همون طور که درباره بیشتر چیزای مربوط به موتورهای جستجو صدق میکنه، دقیقاً نمیدونیم RankBrain چطور کار میکنه، و حتی گوگل هم کامل ازش سر درنمیاره!
این موضوع چه معنایی برای سئوکارها داره؟
از اونجایی که گوگل با استفاده از RankBrain به دنبال نمایش محتوای مرتبطتر و مفیدتره، ما به عنوان سئوکارها باید بیشتر از قبل روی پاسخ به نیاز کاربرها تمرکز کنیم. وقتی بهترین اطلاعات و تجربه ممکن رو به کاربرهایی که وارد صفحت میشن ارائه بدی، عملاً اولین قدم بزرگ رو برای موفقیت توی دنیای RankBrain برداشتی.
معیارهای تعامل: همبستگی، علت یا هر دو؟
وقتی صحبت از رتبه بندی توی گوگل میشه، معیارهای تعامل احتمالاً هم یه جور همبستگی دارن و هم یه جور رابطه علت و معلولی.
منظورمون از معیارهای تعامل، داده هایی هست که نشون میده کاربرها چطور با سایتت از طریق نتایج جستجو تعامل میکنن. این معیارها شامل موارد زیره:
- کلیک ها: تعداد بازدیدهایی که از نتایج جستجو به سایتت میرسه
- زمان حضور در صفحه: مدت زمانی که کاربر قبل از ترک کردن صفحه، توش مونده
- نرخ پرش (Bounce Rate): درصد جلساتی که کاربرها فقط یه صفحه رو بازدید میکنن و بدون رفتن به صفحه دیگه از سایت خارج میشن
- پوگو استیکینگ (Pogo-sticking): وقتی کاربر روی یه نتیجه ارگانیک کلیک میکنه و سریع برمی گرده به صفحه نتایج و یه نتیجه دیگه رو انتخاب میکنه
تستهای مختلف، نشون دادن که معیارهای تعامل با رتبههای بالاتر توی جستجو همبستگی دارن، ولی اینکه آیا این رابطه علت و معلولی هم هست یا نه، همیشه مورد بحث بوده. یعنی آیا معیارهای خوب تعامل نشونه ای از سایتهای با رتبه بالاست؟ یا اینکه سایتها به خاطر داشتن این معیارهای خوب رتبه بالاتری دارن؟
گوگل چی گفته؟
درسته که گوگل هیچ وقت از عبارت "سیگنال مستقیم رتبه بندی" استفاده نکرده، اما کاملاً مشخص کرده که از دادههای کلیک برای تغییر نتایج جستجو توی برخی از کوئریها استفاده میکنه.
اودی منبر، یکی از مدیران سابق بخش کیفیت جستجوی گوگل، گفته:
"خودِ رتبه بندی تحت تأثیر دادههای کلیک قرار میگیره. اگر متوجه بشیم که برای یه کوئری خاص، 80 درصد از کاربران روی نتیجه دوم کلیک میکنن و فقط 10 درصد روی نتیجه اول، بعد از یه مدت متوجه میشیم که احتمالاً نتیجه دوم همون چیزی هست که مردم دنبالش بودن، پس جاشون رو عوض میکنیم."
همچنین، ادموند لاو، یکی از مهندسان سابق گوگل، تأیید کرده:
"خیلی واضحه که هر موتور جستجوی معقولی از دادههای کلیک روی نتایج خودش برای بهبود کیفیت جستجو استفاده میکنه. جزئیات دقیق اینکه چطور از این دادهها استفاده میشه معمولاً محرمانه ست، اما گوگل با داشتن پتنت هایی مثل سیستمهای رتبه بندی محتوا، نشون داده که از این دادهها استفاده میکنه."
به خاطر اینکه گوگل باید همیشه کیفیت جستجوها رو حفظ و بهتر کنه، خیلی منطقیه که معیارهای تعامل فقط یه همبستگی نباشن، بلکه نشون میده که گوگل از این دادهها برای بهبود کیفیت نتایج استفاده میکنه و تغییر رتبه صفحات نتیجه طبیعی اون فرایند بهبودیه.
تست هایی که تأییدش کردن
تستهای مختلف نشون دادن که گوگل میتونه ترتیب نتایج رو براساس تعامل کاربران تغییر بده:
- تست رند فیشکین در سال 2014 باعث شد که یک نتیجه از رتبه ۷ به رتبه ۱ برسه. اون حدود ۲۰۰ نفر رو تشویق کرد که روی اون لینک از صفحه نتایج جستجو کلیک کنن. جالب اینکه بهبود رتبه بیشتر محدود به لوکیشن اون افراد بود. مثلاً در آمریکا که اکثر شرکت کنندگان اونجا بودن، رتبه بالاتر رفت، ولی توی گوگل کانادا و استرالیا همون رتبه پایینتر باقی موند.
- تست لری کیم هم نشون داد که مقایسه زمان سپری شده روی صفحات برتر، قبل و بعد از الگوریتم RankBrain، گویا نشون میده که بخش یادگیری ماشینی این الگوریتم صفحات رو که کاربران زمان کمتری توشون میمونن، پایینتر میاره.
- تستهای دارن شاو هم نشون دادن که رفتار کاربران روی نتایج جستجوی محلی و نمایش نقشه تأثیر میذاره.
از اونجا که معیارهای تعامل کاربر مستقیماً روی کیفیت نتایج تأثیر میذارن و رتبه صفحات هم به عنوان یک نتیجه جانبی تغییر میکنه، میشه گفت که سئوکارها باید روی بهینه سازی تعامل کاربران تمرکز کنن. تعامل کاربر شاید کیفیت اصلی صفحه رو تغییر نده، ولی نشون دهنده ارزش صفحه برای کاربرانه و به گوگل کمک میکنه رتبه بندی دقیقتری بده. به همین دلیله که ممکنه بدون تغییر در محتوای صفحه یا لینک ها، رتبه صفحه افت کنه، اگه رفتار کاربران نشون بده که صفحات دیگه بیشتر به دردشون میخوره.
تو رتبه بندی صفحات وب، معیارهای تعامل مثل یه ناظر عمل میکنن. اول لینکها و محتوا صفحه رو رتبه بندی میکنن، بعد این تعاملها کمک میکنن که اگه چیزی درست نبود، گوگل اونو اصلاح کنه.
تکامل نتایج جستجو
یه زمانی که موتورهای جستجو مثل الان پیچیده نبودن، اصطلاح "10 لینک آبی" ابداع شد تا ساختار ساده صفحه نتایج جستجو (SERP) رو توصیف کنه. اون موقع هر بار که جستجویی انجام میشد، گوگل یه صفحه با ۱۰ نتیجه ارگانیک به شکل یکنواخت نمایش میداد.
در اون دوران، رتبه اول توی نتایج جستجو واقعاً همه چیز بود. اما بعد یه اتفاق افتاد. گوگل شروع کرد به اضافه کردن فرمتهای جدید به صفحات نتایج، که بهشون ویژگیهای SERP (SERP Features) میگن. از جمله این ویژگیها میشه به موارد زیر اشاره کرد:
- تبلیغات پولی
- اسنیپتهای ویژه
- جعبههای "مردم همچنین میپرسند"
- بسته محلی (نقشه)
- پنل دانش (Knowledge Panel)
- لینکهای داخلی سایت (Sitelinks)
و گوگل دائم داره ویژگیهای جدید اضافه میکنه. حتی یه بار یه آزمایشی انجام داد که بهش میگفتن "SERP بدون نتیجه"، یعنی فقط یک نتیجه از نمودار دانش (Knowledge Graph) نمایش داده میشد و زیرش هیچ نتیجه ای نبود جز گزینه "مشاهده نتایج بیشتر."
اضافه شدن این ویژگیها باعث یه جور نگرانی شد، چون دو تا اتفاق افتاد: یکی اینکه نتایج ارگانیک بیشتر پایین صفحه میافتادن و کمتر دیده میشدن. دوم اینکه کاربران کمتر روی نتایج ارگانیک کلیک میکردن، چون خیلی از سوال هاشون توی خود صفحه جستجو جواب داده میشد.
حالا چرا گوگل این کار رو کرد؟ برمی گرده به بهبود تجربه کاربری. رفتار کاربران نشون میده که بعضی جستجوها با فرمتهای مختلف محتوا بهتر جواب داده میشن. مثلاً:
- برای جستجوهای اطلاعاتی: اسنیپتهای ویژه نمایش داده میشن
- برای سوالات با یه جواب مشخص: نمودار دانش یا جواب سریع (Instant Answer) ظاهر میشه
- برای جستجوهای محلی: بسته نقشه (Map Pack) میاد
- برای خرید: نتایج فروشگاهی نمایش داده میشه
در مقاله "راهنمای سئو برای مبتدی ها: تحقیق کلمه کلیدی" بیشتر درباره هدف جستجو (intent) صحبت میکنیم، ولی فعلاً اینو بدون که جوابها میتونن توی فرمتهای مختلف به کاربر ارائه بشن و اینکه چطور محتوای خودتو ساختار بدی، روی اینکه توی چه فرمتی ظاهر بشی، تأثیر داره.
جستجوی محلی
اگه داری برای یه کسب وکار محلی (مثل دندان پزشکی که مردم میتونن بهش سر بزنن) یا یه کسب وکار سیار (مثل لوله کش که خودش به خونه مشتریها میره) کار سئوی محلی انجام میدی، یادت نره که حتماً یه پروفایل رایگان توی Google My Business بسازی، تأییدش کنی و بهینش کنی.
وقتی بحث نتایج جستجوی محلی میشه، گوگل با توجه به سه فاکتور اصلی ترتیب نتایج رو مشخص میکنه:
- مرتبط بودن
- فاصله
- برجستگی
مرتبط بودن
مربوط بودن یعنی اینکه چقدر کسب وکار با چیزی که کاربر دنبالش میگرده تطابق داره. برای اینکه کسب وکارت مطمئن بشه توی جستجوها ظاهر میشه، حتماً اطلاعات رو کامل و دقیق وارد کن.
فاصله
گوگل از موقعیت جغرافیایی شما استفاده میکنه تا نتایج نزدیک به شما رو بهتر نشون بده. نتایج جستجوی محلی خیلی حساس به فاصله هستن، یعنی اینکه چقدر به موقعیت فیزیکی کسب وکار نزدیک هستی. حتی اگه توی کوئری هم محل خاصی رو وارد کرده باشی، باز هم گوگل اینو در نظر میگیره.
برجستگی
گوگل میخواد کسب وکارهایی رو که توی دنیای واقعی هم معروف و برجسته هستن، پاداش بده. علاوه بر اینکه چقدر توی دنیای واقعی معروف هستی، یه سری فاکتورهای آنلاین هم هست که روی رتبه بندیت تاثیر میذارن، مثل:
- نظرات مشتری ها: تعداد و کیفیت نظرات توی گوگل تأثیر مستقیم روی رتبه بندیت داره.
- استنادها (Citations): یعنی هر جایی که اسم، آدرس و شماره تلفن کسب وکار تو توی یه پلتفرم محلی (مثل Yelp یا YP) ذکر بشه. گوگل این اطلاعات رو از منابع مختلف جمع میکنه و هرچی این استنادها منظمتر و بیشتر باشن، اعتماد گوگل به درستی اطلاعات بیشتر میشه.
رتبه بندی ارگانیک
علاوه بر همه اینا، گوگل موقع رتبه بندی محلی، جایگاه سایتت توی نتایج ارگانیک رو هم در نظر میگیره. پس اصول سئوی کلی رو هم باید توی سئوی محلی رعایت کنی.
توی مقاله بعد، به اصول بهینه سازی صفحات میپردازیم که باعث میشه گوگل و کاربرا بهتر محتوای سایتتو بفهمن.
سوالات متداول

1. موتورهای جستجو چطور صفحات سایت من رو پیدا میکنن؟
موتورهای جستجو با استفاده از فرآیندی به نام خزش (Crawling) و ایندکس کردن (Indexing)، صفحات سایت شما رو پیدا میکنن. اونها از لینکهای موجود در سایتهای دیگه و همین طور نقشه سایت (Sitemap) استفاده میکنن تا محتوا رو کشف کنن و در پایگاه داده خودشون ذخیره کنن.
2. چرا رتبه بندی سایت در نتایج جستجو انقدر متغیره؟
رتبه بندی سایتها به الگوریتمهای گوگل بستگی داره که دائم به روزرسانی میشن. این الگوریتمها سعی میکنن بهترین و مرتبطترین نتایج رو به کاربران ارائه بدن و عواملی مثل محتوای سایت، لینکهای ورودی و رفتار کاربران رو بررسی میکنن.
3. چرا لینکها برای سئو اهمیت دارن؟
لینکها مثل اعتبارنامه ای برای سایت شما عمل میکنن. وقتی سایتهای معتبر به سایت شما لینک میدن، این نشون میده که محتوای شما ارزشمنده و گوگل این رو به عنوان یک سیگنال مثبت در نظر میگیره و ممکنه رتبه شما رو بالاتر ببره.
4. چرا محتوای سایت باید با نیاز کاربر هماهنگ باشه؟
گوگل سعی میکنه بهترین نتایج رو به کاربرها نمایش بده، پس محتوای شما باید مستقیماً به سوالات و نیازهای کاربران پاسخ بده. هرچی محتوای شما بهتر نیازهای کاربران رو برآورده کنه، احتمال رتبه گیری اون در نتایج جستجو بیشتره.
5. چرا اطلاعات کسب وکار محلی توی گوگل اهمیت داره؟
اطلاعات کسب وکار محلی شما، مثل نام، آدرس و شماره تلفن، به گوگل کمک میکنه تا شما رو به کاربران محلی معرفی کنه. وقتی این اطلاعات دقیق و به روز باشه، اعتماد گوگل به شما بیشتر میشه و شانس رتبه گرفتن در جستجوهای محلی افزایش پیدا میکنه.
6. چه فاکتورهایی روی رتبه بندی محلی تأثیر میذارن؟
سه فاکتور اصلی که گوگل برای رتبه بندی محلی در نظر میگیره شامل ارتباط (میزان تطابق کسب وکار شما با نیاز کاربر)، فاصله (نزدیکی مکان کسب وکار به کاربر) و معروفیت (چقدر کسب وکار شما شناخته شده است) میشه.
7. چطور میتونم از ابزار Check Listing استفاده کنم؟
Moz یه ابزار رایگان به نام Check Listing داره که بهت کمک میکنه صحت و دقت اطلاعات کسب وکار محلی خودت رو بررسی کنی. این ابزار میتونه نواقص رو پیدا کنه و به بهبود رتبه بندی محلی شما کمک کنه.
8. چطور تعاملات واقعی بر نتایج محلی گوگل تأثیر میذاره؟
گوگل از دادههای واقعی مثل بازدیدهای مشتریان، نظرات و سوالات کاربران برای تعیین مرتبط بودن و کیفیت کسب وکار استفاده میکنه. هرچه تعاملات شما با مشتریان واقعی بیشتر باشه، احتمالاً رتبه تون هم بهتر میشه.
جمع بندی
گوگل همیشه دنبال ارائه بهترین نتایج به کاربراست، پس طبیعیه که از دادههای واقعی و زنده برای تعیین کیفیت و مرتبط بودن کسب وکارها استفاده کنه.
نیازی نیست که همه جزئیات الگوریتم گوگل رو بدونی (اون خودش یه راز بزرگه!)، ولی الان دیگه باید یه درک کلی از نحوه کارکرد موتور جستجو تو پیدا کردن، تفسیر کردن، ذخیره و رتبه بندی محتوا داشته باشی. با این دانش، آماده ایم که بریم سراغ انتخاب کلمات کلیدی که محتوای سایتت قراره روی اونا متمرکز بشه! برای یادگیری بیشتر، مقاله 4اُم (تحقیق کلمات کلیدی) رو از دست نده!


۰ دیدگاه

دوره الفبای برنامه نویسی با هدف انتخاب زبان برنامه نویسی مناسب برای شما و پاسخگویی به سوالات متداول در شروع یادگیری موقتا رایگان شد: