۷
دیدگاه
نظر

آموزش شبکه عصبی در پایتون : (ANN: Artificial Neural Network)
سرفصلهای مقاله
- شبکه ی عصبی مصنوعی چیست؟
- ساختار شبکه ی عصبی مصنوعی (ANN)
- روش feed-forward
- جمع بندی
اگر با هوش مصنوعی آشنایی داشته باشید و عنوان شبکههای عصبی مصنوعی (ANN: Artificial Neural Network) به گوشتان خورده باشد، احتمالاً این سؤال برای شما پیش آمده است که شبکه ی عصبی چیست، توانایی انجام چه کارهایی را دارد و کاربرد آن در چه زمینه هایی است؟ شبکههای عصبی، پایه و اساس یادگیری عمیق (Deep Learning) هستند. یادگیری عمیق یکی از زیرشاخههای یادگیری ماشین است که توانسته پیشرفتهای زیادی به دست آورد. از جمله مثالهای کاربردی آن میتوان به کنترل بازیکنان در بازیهای Go و Poker و همچنین تسریع کشف مواد مخدر و کمک به اتومبیلهای اتوماتیک (خودران) اشاره کرد.
اگر این نوع برنامههای پیشرفته شما را به هیجان بیاورند، احتمالاً به موضوع یادگیری عمیق علاقه مند هستید. با این حال، این امر مستلزم آن است که شما با عملکرد شبکههای عصبی آشنا باشید. هدف ما این است که در این مقاله ی آموزشی، شبکههای عصبی را با زبان و مفاهیم ساده، به صورت عمیق، کاربردی و سریع به شما آموزش دهیم. در این آموزش مفاهیم، کد و ریاضیاتی ارائه میشود که به شما امکان ساخت و درک یک شبکه ی عصبی ساده را به صورت عملی میدهد.
برخی از مقالات آموزشی فقط بر روی کدنویسی متمرکز هستند و از ریاضیات صرف نظر میکنند. اما توجه داشته باشید این موضوع مانع درک صحیح مطلب میشود. در این مقاله، آموزشها را با بیان دقیق جزئیات جلو میبریم. با این حال برای درک مطالب لازم است که با مفاهیمی چون ماتریسها و مشتق در ریاضیات آشنایی داشته باشید. کدهای مقاله با زبان پایتون نوشته شده اند، بنابراین اگر اطلاعات پایه ای از نحوه ی کار پایتون داشته باشید، برایتان مفید خواهد بود. به شما پیشنهاد میکنیم در صورت نیاز، آموزشهای ارائه شده در سایت درخصوص توابع پایتون، حلقهها و اصول کتابخانه ی Numpy را مطالعه کنید.
شبکه ی عصبی مصنوعی چیست؟
شبکههای عصبی مصنوعی (ANN)، یک پیاده سازی نرم افزاری از ساختار عصبی مغز ما هستند. نیازی نیست که در مورد زیست شناسی پیچیده ی ساختارهای مغزی خود صحبت کنیم، اما کافی است بدانیم که مغز حاوی سلولهای عصبی (نورون هایی) است که به نوعی مانند سوئیچهای آلی (ارگانیک) هستند. یعنی به عنوان واسطی میان مجموعه ای از ورودیها و خروجی قرار گرفته اند. این نورونها بسته به قدرت ورودی الکتریکی یا شیمیایی آنها میتوانند حالت خروجی خود را تغییر دهند.
شبکه ی عصبی در مغز یک فرد، یک شبکه ی کاملاً متصل به سلولهای عصبی (نورون ها) است که در آن خروجی هر نورون مشخص ممکن است که ورودی هزاران نورون دیگر باشد. یادگیری، با فعال سازی مکرر برخی اتصالات عصبی بر روی دیگر اتصالات رخ میدهد و این فعال سازیهای مکرر، آن اتصالها را تقویت میکند. این امر باعث میشود با توجه به هر ورودی مشخص، نتیجه ی مطلوبی ایجاد شود. این یادگیری نیازمند بازخورد (فیدبک) است. وقتی نتیجه ی مطلوب رخ میدهد، ارتباطات عصبی که آن نتیجه را ایجاد کرده اند، تقویت میشوند. شبکههای عصبی مصنوعی سعی در ساده سازی و تقلید از این رفتار مغز دارند. میتوان آنها را به دو شیوه ی نظارت شده (supervised) و بدون نظارت (unsupervised) آموزش داد. در یک شبکه ی ANN تحت نظارت، شبکه با تهیه ی نمونههای داده ی ورودی و خروجی تطبیق داده شده، آموزش میبیند. با این هدف که ANN بتواند خروجی مطلوبی را برای یک ورودی معین فراهم کند. یک مثال، فیلتر اسپم پست الکترونیکی است. داده ی آموزش ورودی میتواند تعداد کلمات مختلف در متن ایمیل باشد و دادههای آموزش خروجی، میتواند این طبقه بندی باشد که آیا ایمیل واقعاً اسپم بوده است یا خیر.
اگر نمونههای زیادی از نامههای الکترونیکی از طریق شبکه ی عصبی منتقل شده باشند، این امکان را به شبکه میدهد تا یاد بگیرد که کدام دادههای ورودی باعث میشود نامه ی الکترونیکی اسپم باشد یا نباشد. این یادگیری برای تنظیم وزن اتصالات ANN صورت میگیرد، اما درباره ی این موضوع در بخش بعدی بیشتر بحث خواهد شد. یادگیری بدون نظارت در ANN برای این است که "درک" ساختار دادههای ورودی ارائه شده به ANN "به خودی خود" صورت گیرد. این نوع از ANN در این مقاله بررسی نخواهد شد.
ساختار شبکه ی عصبی مصنوعی (ANN)
در ادامه با اجزای ساختار شبکه ی عصبی مصنوعی آشنا میشویم.
نورون مصنوعی
نورون بیولوژیکی توسط یک تابع فعال سازی در ANN شبیه سازی میشود. در وظایف طبقه بندی (به عنوان مثال شناسایی نامههای الکترونیکی اسپم)، این عملکرد فعال سازی باید دارای ویژگی "switch on" یا "روشن شدن" یا "فعال شدن" باشد. به عبارت دیگر، هنگامی که ورودی از مقدار مشخصی بزرگتر باشد، خروجی باید تغییر کند یعنی به طور مثال از 0 به 1، از 1- به 1 یا از 0 به مقداری بزرگتر از صفر تغییر حالت دهد. این در واقع، شبیه سازی روشن شدن یا فعال شدن یک نورون بیولوژیکی است. یک تابع فعال سازی که معمولا استفاده میشود تابع سیگموئید است. در تابع سیگموئید داریم: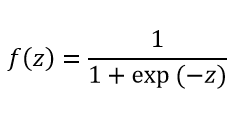
کد این تابع به شکل زیر است:
import matplotlib.pylab as plt
import numpy as np
x = np.arange(-8, 8, 0.1)
f = 1 / (1 + np.exp(-x))
plt.plot(x, f)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.show()که خروجی به این شکل است:
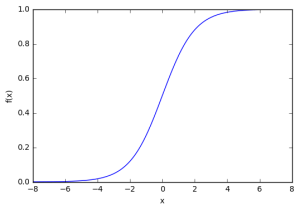
همانطور که در تصویر بالا مشاهده میشود، این تابع زمانی که ورودی x از یک مقدار مشخص بزرگتر باشد "فعال" میشود، یعنی از 0 به 1 حرکت میکند. تابع سیگموئید یک تابع پله ای نیست، لبه "نرم" است و خروجی به یکباره تغییر نمیکند. این بدان معنی است که مشتق تابع وجود دارد و این برای الگوریتم آموزش بر مبنای گرادیان مهم میباشد.

گره ها
همانطور که پیش از این ذکر شد، نورونهای بیولوژیکی به صورت شبکههای سلسله مراتبی به هم متصل هستند و خروجی برخی از سلولهای عصبی به ورودی دیگر سلولها متصل است. ما میتوانیم این شبکهها را به صورت لایههای متصل از گرهها نشان دهیم. هر گره چند ورودی وزن دار میگیرد، تابع فعال سازی را روی حاصل جمع وزن دار این ورودیها اعمال میکند و با این کار یک خروجی تولید میکند. این مورد را در ادامه تحلیل و بررسی میکنیم. نمودار زیر را در نظر بگیرید: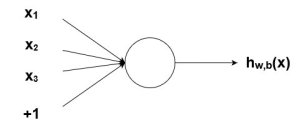
شکل1) گره با ورودی ها
در تصویر بالا، دایره نشان دهنده ی گره است. گره در واقع ورودیهای وزنی را گرفته، با هم جمع میکند و سپس نتیجه را به تابع فعال سازی وارد میکند. خروجی تابع فعال سازی در نمودار فوق با h نشان داده شده است.
توجه: در برخی مقالات و نوشتهها به گره ای که در بالا نشان داده شده است، perceptron (پرسپترون) نیز گفته میشود.
"وزن" گره چیست؟ وزنها اعداد حقیقی هستند (به عنوان مثال 1 یا 0 دودویی نیستند)، که در ورودیها ضرب میشوند (هر ورودی به وزن مربوط به خودش ضرب میشود) و سپس این حاصل ضربها در ورودی گره، با هم جمع میشوند. به عبارت دیگر، ورودی وزنی به گره فوق به صورت زیر است:
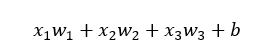
در اینجا wiوزنها هستند (فعلا b را نادیده بگیرید). اما این وزنها به چه مربوط هستند؟ در واقع، آنها متغیرهایی هستند که در طول فرآیند یادگیری تغییر میکنند و همراه با ورودی، خروجی گره را تعیین میکنند. b وزن عنصر بایاس 1+ است. گنجاندن این بایاس انعطاف پذیری گره را افزایش میدهد که بهتر است با یک مثال آن را ثابت کنیم.
بایاس
بیایید یک گره بسیار ساده را در نظر بگیریم، گره ای فقط با یک ورودی و یک 
شکل 2) گره ساده
ورودی به تابع فعال ساز گره در این حالت، مقدار x1w1 می باشد. تغییر w1 در این شبکه ی ساده چه کاری انجام میدهد؟ به کد زیر توجه کنید:
w1 = 0.5
w2 = 1.0
w3 = 2.0
l1 = 'w = 0.5'
l2 = 'w = 1.0'
l3 = 'w = 2.0'
for w, l in [(w1, l1), (w2, l2), (w3, l3)]:
f = 1 / (1 + np.exp(-x*w))
plt.plot(x, f, label=l)
plt.xlabel('x')
plt.ylabel('h_w(x)')
plt.legend(loc=2)
plt.show()خروجی کد به شکل زیر است:
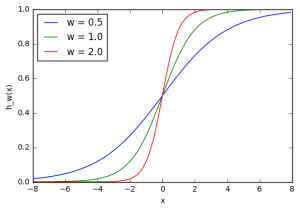
در اینجا میبینیم که تغییر وزن، شیب خروجی تابع فعال سازی سیگموئید را تغییر میدهد، که بدیهی است اگر بخواهیم نقاط قوت مختلف روابط بین متغیرهای ورودی و خروجی را مدل کنیم، مفید خواهد بود. با این حال، اگر بخواهیم خروجی تنها زمانی تغییر کند که x بزرگتر از 1 باشد، چه میکنیم؟ این مورد، حالتی است که بایاس وارد عمل میشود. بیایید همان شبکه را با ورودی بایاس در نظر بگیریم: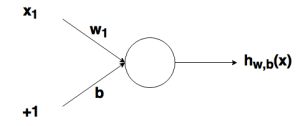
شکل 3) تأثیر بایاس
کد زیر که بایاس در آن در نظر گرفته شده را ببینید:
w = 5.0
b1 = -8.0
b2 = 0.0
b3 = 8.0
l1 = 'b = -8.0'
l2 = 'b = 0.0'
l3 = 'b = 8.0'
for b, l in [(b1, l1), (b2, l2), (b3, l3)]:
f = 1 / (1 + np.exp(-(x*w+b)))
plt.plot(x, f, label=l)
plt.xlabel('x')
plt.ylabel('h_wb(x)')
plt.legend(loc=2)
plt.show()خروجی کد به شکل زیر است که تأثیر تنظیم مقادیر بایاس را نشان میدهد:
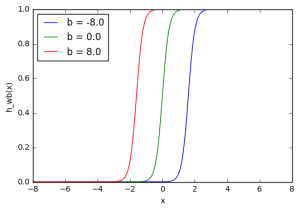
در این حالت، مقدار برای شبیه سازی عملکرد تعریف شده ی "روشن کردن" افزایش یافته است. همانطور که مشاهده میکنید با تغییر "وزن" بایاس (b) میتوانید زمان فعال شدن گره را تغییر دهید. بنابراین با افزودن بایاس میتوان گره را به گونه ای ایجاد کرد که مانند یک تابع if رفتار کند. مثلاً: if (x>z) then 1 else 0.
بدون بایاس، شما نمیتوانید مقدار z را در جمله ی if تغییر دهید. در حالت بدون بایاس، مقدار z همیشه حدود صفر باقی میماند. اگر سعی در شبیه سازی روابط شرطی دارید، این مورد بسیار مفید خواهد بود.
قراردادن تمامی ساختارهای شبکه کنار همدیگر
امیدواریم توضیحات قبلی به شما نمای خوبی از چگونگی عملکرد یک گره/ نورون/ پرسپترون داده شده در یک شبکه ی عصبی، ارائه داده باشد. با این حال، همانطور که احتمالا میدانید، تعداد زیادی از این گرههای به هم پیوسته در یک شبکه ی عصبی وجود دارد. این ساختارها میتوانند به هزاران شکل مختلف وجود داشته باشند، اما متداولترین ساختار ساده ی شبکه ی عصبی شامل یک لایه ی ورودی، یک لایه ی پنهان و یک لایه ی خروجی است. یک نمونه از چنین ساختاری را میتوان در شکل زیر مشاهده کرد: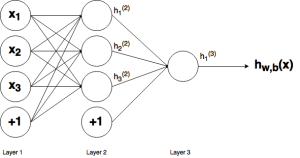
شکل 4) شبکه ی عصبی سه لایه
سه لایه ی شبکه در شکل بالا قابل مشاهده است. لایه ی یک نشان دهنده ی لایه ی ورودی است، جایی که دادههای ورودی خارجی وارد شبکه میشوند. به لایه ی 2، لایه ی پنهان گفته میشود زیرا این لایه بخشی از ورودی یا خروجی نیست.
توجه: شبکههای عصبی میتوانند لایههای پنهان زیادی داشته باشند، اما در این مورد برای سادگی فقط یک لایه ی پنهان در نظر گرفته ایم. در نهایت، لایه ی 3 لایه ی خروجی است. میتوانید ارتباطات زیادی بین لایه ها، به ویژه بین لایه ی 1 (L1) و لایه ی 2 (L2) مشاهده کنید. همانطور که دیده میشود، هر گره در L1 با تمام گرههای L2 ارتباط دارد، به همین ترتیب گرههای موجود در L2 با گره منفرد L3 ارتباط دارند. هر یک از این اتصالات دارای وزن مرتبط با خود خواهند بود.
علامت گذاری
ریاضیات زیر نیاز به یک علامت گذاری کاملاً دقیق دارد تا بدانیم درباره ی چه چیزی صحبت میکنیم. علامت گذاری استفاده شده در اینجا، مشابه آنچه که در مقاله ی آموزش یادگیری عمیق استنفورد استفاده شده، میباشد. در معادلات پیش رو، هر یک از این وزنها با علامت گذاری زیر مشخص میشوند:
(wij(l که در آن i به شماره ی گره اتصال در لایه ی l+1 و j به شماره ی گره اتصال در لایه ی l اشاره دارد.
توجه ویژه ای به این مورد داشته باشید. بنابراین، برای بیان اتصال بین گره 1 در لایه 1 و گره 2 در لایه 2، علامت گذاری وزن به صورت W21 خواهد بود. این علامت گذاری شاید کمی عجیب به نظر بیاید، اما همانطور که انتظار دارید، شمارهها در لایه ی l و l+1 به ترتیب هستند (با ترتیب شماره ی ورودی و خروجی) و نه برعکس. با این حال، هنگامی که بایاس را اضافه میکنید، این علامت گذاری معنی بیشتری پیدا میکند. همانطور که در شکل بالا مشاهده میکنید بایاس (1+) به هر یک از گرههای لایه ی بعدی متصل است. بنابراین بایاس موجود در لایه ی 1 به تمام گرههای موجود در لایه ی 2 متصل است. از آنجا که بایاس یک گره واقعی با عملکرد فعال سازی نیست، ورودی ندارد (همیشه مقدار 1+ را در خروجی ایجاد میکند).
علامت وزن بایاس(bi(l است که در آن i نشان دهنده ی شماره ی گره در لایه ی l+1 است، همانند آنچه که برای علامت گذاری نرمال وزن (w21(1 استفاده شد. بنابراین، وزن مربوط به اتصال بین بایاس در لایه ی 1 و گره دوم در لایه ی 2 با (b2(1 نشان داده میشود. به یاد داشته باشید، مقادیر(wji(1 و (bi(l باید در مرحله ی آموزش ANN محاسبه شوند. علامت خروجی گره نیز به صورت (hj(l میباشد، که در آن j تعداد گره را در لایه ی شبکه نشان میدهد. همانطور که در شبکه ی سه لایه ی فوق مشاهده میشود، خروجی گره 2 در لایه ی 2 با علامت (h2(2 مشخص شده است. اکنون که علامت گذاریها مرتب شده اند، وقت آن است که نحوه ی محاسبه ی خروجی شبکه را در زمان مشخص بودن ورودی و وزنها بررسی کنیم. فرآیند محاسبه ی خروجی شبکه ی عصبی با توجه به این مقادیر، روش یا فرآیند feed-forward نامیده می شود.
روش feed-forward
برای نشان دادن نحوه ی محاسبه ی خروجی از روی ورودی در شبکههای عصبی، بیایید با مورد خاص شبکه ی عصبی سه لایه ای که در بالا ارائه شد، شروع کنیم. در این قسمت، همان شبکه ی عصبی سه لایه به صورت معادله ارائه شده است. در ادامه با یک مثال و کدهای پایتون آن را به شما نشان میدهیم.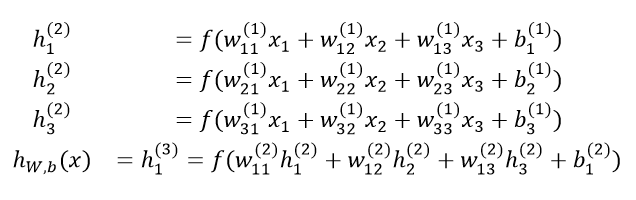
در معادلات فوق، ( )f به تابع فعال سازی گره اشاره دارد، که در این مورد، تابع سیگموئید است. در سطر اول،(h1(2 نشان دهنده ی خروجی گره 1 در لایه ی 2 میباشد که ورودی هایش به شکل زیر هستند: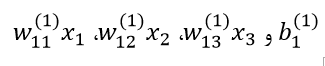
این ورودیها را میتوان در نمودار اتصال سه لایه ی فوق ردیابی کرد. آنها به سادگی جمع میشوند و سپس برای محاسبه ی خروجی گره اول از تابع فعال سازی عبور میکنند. برای دو گره دیگر در لایه ی دوم نیز به همین ترتیب عمل میکنیم. خط نهایی خروجی، تنها گره موجود در لایه ی سوم که لایه ی آخر است، میباشد و خروجی نهایی شبکه ی عصبی است. همانطور که مشاهده میشود، به جای استفاده از متغیرهای ورودی وزنی (x1, x2, x3)، گره نهایی، خروجی وزنی گرههای لایه ی دوم (h3(2), h2(2), h1(2)) به علاوه ی بایاس وزنی را به عنوان ورودی در نظر میگیرد. بنابراین، در فرم معادله میتوانید ماهیت سلسله مراتبی شبکههای عصبی مصنوعی را ببینید.
مثالی برای feed-forward
حال، بیایید یک مثال ساده از خروجی این شبکه ی عصبی در پایتون را بررسی کنیم. قبل از هر کاری بررسی کنید که آیا وزنهای بین لایه ی 1 و 2، (w11(1), w12(1),…) به طور ایده آل برای نمایش ماتریس مناسب هستند؟
ماتریس زیر را ملاحظه کنید:
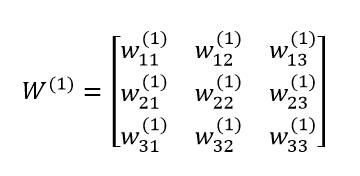 این ماتریس را میتوان با استفاده از آرایههای numpy به راحتی نمایش داد:
این ماتریس را میتوان با استفاده از آرایههای numpy به راحتی نمایش داد:
import numpy as np
w1 = np.array([[0.2, 0.2, 0.2], [0.4, 0.4, 0.4], [0.6, 0.6, 0.6]])در اینجا آرایه ی وزن لایه ی 1 را با برخی از وزنهای نمونه پر کرده ایم. میتوانیم همین کار را برای آرایههای وزنی لایه ی 2 نیز انجام دهیم: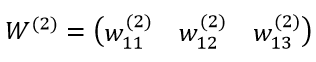 کد پایتون زیر نحوه ی تعریف آرایه ی وزنی لایه ی 2 را نشان میدهد:
کد پایتون زیر نحوه ی تعریف آرایه ی وزنی لایه ی 2 را نشان میدهد:
w2 = np.zeros((1, 3))
w2[0,:] = np.array([0.5, 0.5, 0.5])ما همچنین میتوانیم برخی مقادیر ساختگی را در آرایه/ بردار، وزن بایاس لایه ی 1 و وزن بایاس لایه ی 2 (که فقط یک مقدار واحد در این ساختار شبکه ی عصبی است، یعنی یک اسکالر) تنظیم کنیم:
b1 = np.array([0.8, 0.8, 0.8])
b2 = np.array([0.2])در نهایت، قبل از نوشتن برنامه ی اصلی برای محاسبه ی خروجی از شبکه ی عصبی، خوب است که یک تابع پایتون جداگانه برای عملکرد فعال سازی تنظیم کنید:
def f(x):
return 1 / (1 + np.exp(-x))ارائه ی تابع feed-forward
در زیر یک روش ساده برای محاسبه ی خروجی شبکه ی عصبی، با استفاده از حلقههای تودرتو در پایتون آمده است. به زودی روشهای کارآمدتر محاسبه ی خروجی را بررسی خواهیم کرد.
def simple_looped_nn_calc(n_layers, x, w, b):
for l in range(n_layers-1):
#Setup the input array which the weights will be multiplied by for each layer
#If it's the first layer, the input array will be the x input vector
#If it's not the first layer, the input to the next layer will be the
#output of the previous layer
if l == 0:
node_in = x
else:
node_in = h
#Setup the output array for the nodes in layer l + 1
h = np.zeros((w[l].shape[0],))
#loop through the rows of the weight array
for i in range(w[l].shape[0]):
#setup the sum inside the activation function
f_sum = 0
#loop through the columns of the weight array
for j in range(w[l].shape[1]):
f_sum += w[l][i][j] * node_in[j]
#add the bias
f_sum += b[l][i]
#finally use the activation function to calculate the
#i-th output i.e. h1, h2, h3
h[i] = f(f_sum)
return hاین تابع تعداد لایههای شبکه ی عصبی را به عنوان ورودی دریافت میکند که آن را به عنوان آرایه/ بردار ورودی x در نظر میگیریم، سپس تاپل یا لیستی از وزنها و وزنهای بایاس شبکه را دریافت میکند که هر عنصر در این لیست، نشان دهنده ی یک لایه ی l در شبکه است. به عبارت دیگر، ورودیها به صورت زیر تنظیم میشوند:
w = [w1, w2]
b = [b1, b2]
#a dummy x input vector
x = [1.5, 2.0, 3.0]این تابع ابتدا بررسی میکند که ورودی به لایه ی گره (وزن ورودی به گره) چیست. اگر به لایه ی اول نگاه کنیم، ورودی گرههای لایه ی دوم حاصل ضرب بردار ورودی x در وزنهای مربوطه میباشد. بعد از لایه ی اول، ورودی لایههای بعدی، خروجی لایههای قبلی است. در پایان، یک حلقه ی تودرتو از طریق مقادیر مربوط به i و j بردارهای وزن و بایاس داریم. این تابع از ابعاد وزنهای هر لایه برای تشخیص تعداد گرهها و همچنین ساختار شبکه استفاده میکند. فراخوانی تابع به صورت زیر است:
simple_looped_nn_calc(3, x, w, b)این تابع، خروجی 0.8354 را ایجاد خواهد کرد. ما میتوانیم این نتایج را با انجام دستی محاسبات در معادلات اصلی تأیید کنیم:
پیاده سازی کارآمدتر شبکه ی عصبی با feed-forward
همانطور که قبلاً بیان شد استفاده از حلقهها کارآمدترین روش برای محاسبه ی feed-forward در پایتون نیست؛ چرا که حلقهها در پایتون به طرز مشهودی کند هستند. در ادامه یک مکانیزم جایگزین و کارآمدتر برای اجرای محاسبات feed-forward در پایتون و numpy مورد بحث قرار خواهد گرفت. میتوانیم با استفاده از تابع timeit% کارایی الگوریتم ارائه شده را محاسبه کنیم. این تابع چندین بار الگوریتم را اجرا کرده و میانگین زمانهای اجرا را، به عنوان خروجی برمی گرداند:
%timeit simple_looped_nn_calc(3, x, w, b)اجرای این کد به ما میگوید که اجرای محاسبات feed-forward به اندازه ی 40 میکروثانیه طول میکشد. رسیدن به نتیجه در مدت چند ده ثانیه، بسیار سریع به نظر میرسد، اما زمانی که این روش برای شبکههای عصبی بسیار بزرگ با چندصد گره در هر لایه استفاده شود، به خصوص هنگام آموزش شبکه، این سرعت قابل قبول نخواهد بود. اگر یک شبکه ی عصبی چهارلایه را با استفاده از همان کد امتحان کنیم، عملکرد به مراتب بدتری داریم ( 70 میکروثانیه).
بردارسازی در شبکههای عصبی
در روش feed forward میتوان معادلات را به صورت فشردهتر نوشت و محاسبات را با کارایی بیشتری پیاده کرد. در ابتدا، یک متغیر جدید با عنوان (zi(l تعریف میکنیم که نشان دهنده ی مجموع ورودیها به گره i در لایه ی l میباشد و شامل قسمت بایاس هم میباشد. بنابراین در گره اول از لایه ی 2 مقدار z برابر است با:
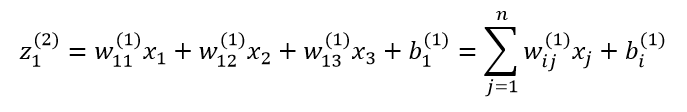
که در آن n نشان دهنده ی تعداد گرهها در لایه ی 1 میباشد. با استفاده از این علامت گذاری، مجموعه معادلات نامناسب قبلی به عنوان مثال برای شبکه ی سه لایه میتواند به صورت زیر کاهش یابد: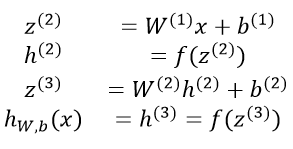
به استفاده از حرف بزرگ W برای اشاره به ماتریس وزنها توجه کنید. دقت کنید تمام المان هایی در که معادله ی فوق وجود دارند، همگی ماتریس یا بردار هستند. اگر با این مفاهیم آشنایی ندارید، در بخش بعدی به طور کامل توضیح داده میشوند.
آیا میتوان معادله ی فوق را کمی سادهتر کرد؟ پاسخ مثبت است. ما میتوانیم محاسبات را از طریق هر تعداد لایه در شبکه ی عصبی با کلی سازی (generalizing) گسترش دهیم.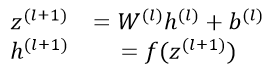
در اینجا میتوانیم روند کلی feed forward را مشاهده کنیم، جایی که خروجی لایه ی l به ورودی لایه ی l + 1 تبدیل میشود. توجه کنید که (h (1 ورودی لایه ی x است و (h (nl ( تعداد لایههای شبکه nl است) خروجی لایه ی خروجی است.
توجه کنید که در معادلات بالا ارجاع به شماره ی گره i و j را حذف کرده ایم. اما چگونه میتوانیم این کار را انجام دهیم؟ آیا مجبور نیستیم که در کد حلقه بزنیم و همه ی ورودیها و خروجیهای مختلف گره را محاسبه کنیم؟ پاسخ این است که برای انجام سادهتر این کار میتوانیم از ضربهای ماتریسی استفاده کنیم. این فرآیند، "بردارسازی" (vectorization) نامیده میشود و دو مزیت دارد:
اولین مزیتش این است که پیچیدگی کد را کاهش میدهد.
دومین مزیت این است که ما میتوانیم به جای استفاده از حلقه ها، از برنامههای جبر خطی سریع در پایتون (و زبانهای دیگر) استفاده کنیم که باعث تسریع برنامههای ما میشود.
Numpy به راحتی میتواند از پس این محاسبات برآید. برای کسانی که با عملیات ماتریس آشنا نیستند، در بخش بعدی توضیح مختصری از عملیات ماتریسها آمده است.
ضرب ماتریس ها
بیایید معادله ی زیر را به صورت ماتریسی / برداری برای لایه ی ورودی گسترش دهیم: 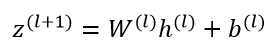 توجه کنید که در این معادله h(l)=x است. گسترش معادله ی بالا برای لایه ی ورودی به شکل زیر است:
توجه کنید که در این معادله h(l)=x است. گسترش معادله ی بالا برای لایه ی ورودی به شکل زیر است: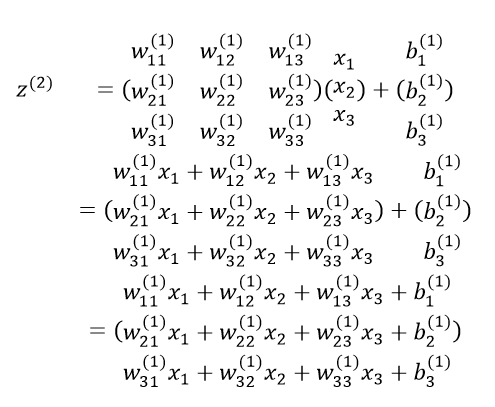
کسانی که از نحوه ی عملکرد ضرب ماتریس آگاهی ندارند، بهتر است که عملیات ماتریس را بررسی کنند. سایتهای زیادی وجود دارند که این موضوع را به خوبی پوشش میدهند. با این حال، خیلی سریع ضرب ماتریسها را بررسی میکنیم: وقتی ماتریس وزن در بردار لایه ی ورودی ضرب میشود، هر عنصر در سطر ماتریس وزن در هر عنصر در تنها ستون بردار ورودی ضرب میشود (بردارها فقط یک ستون دارند)، سپس نتیجه ی این ضربها با هم جمع میشود تا اینکه یک بردار 3*1 جدید ایجاد شود. سپس میتوانید بردارهای بایاس وزن را اضافه کنید تا به نتیجه ی نهایی برسید. اگر دقت کنید میتوانید مشاهده کنید که هر سطر از نتیجه ی نهایی بالا با تابع فعال سازی در مجموعه معادلات اصلی غیرماتریسی فوق مطابقت دارد. اگر تابع فعال سازی بتواند به عناصر اعمال شود (یعنی به هر سطر به طور جداگانه در بردار اعمال شود)، ما میتوانیم تمام محاسبات خود را به جای حلقههای هسته ی پایتون، با استفاده از ماتریس و بردار انجام دهیم.
بیایید نگاهی به نسخه ی سادهتر (و سریع تر) simple_looped_nn_calc بیندازیم:
def matrix_feed_forward_calc(n_layers, x, w, b):
for l in range(n_layers-1):
if l == 0:
node_in = x
else:
node_in = h
z = w[l].dot(node_in) + b[l]
h = f(z)
return hبه سطر هفتم دقت کنید. برای ضرب وزنها در بردار ورودی گره در numpy به جای استفاده از علامت * از علامت (a.dot(b استفاده میکنیم.
اگر با استفاده از این عملکرد جدید و یک شبکه ی ساده ی 4 لایه، timeit% را دوباره اجرا کنیم، فقط 24 میکروثانیه پیشرفت میکنیم (کاهش از 70 میکروثانیه به 46 میکروثانیه). با این حال، اگر اندازه ی شبکه ی 4 لایه را به لایههای 100-100-50-10-10 گره افزایش دهیم، نتایج بسیار چشم گیرتری به دست میآید.
روش مبتنی بر حلقه ی پایتون 41 میلی ثانیه طول میکشد. توجه داشته باشید که واحد در اینجا میلی ثانیه است و پیاده سازی برداری فقط 84 میکروثانیه طول میکشد تا از طریق شبکه ی عصبی به جلو منتقل شود. با استفاده از محاسبات برداری شده به جای حلقههای پایتون، کارایی محاسبه را 500 برابر افزایش داده ایم! این پیشرفت خیلی خوبی است. حتی امکان اجرای سریعتر عملیات ماتریس با استفاده از پکیج های یادگیری عمیق مانند TensorFlow و Theano که از GPU رایانه ی شما (و نه CPU) استفاده میکنند، وجود دارد که معماری آن برای محاسبات سریع ماتریس مناسبتر است.
جمع بندی
در این مقاله به معرفی شبکه ی عصبی و راهکار feed-forward برای آن پرداختیم. شبکههای عصبی جزء الگوریتم های مهم در یادگیری ماشین به شمار میروند. علاوه بر این، برای یادگیری الگوریتمهای جدید همچون یادگیری عمیق، آشنایی با شبکههای عصبی الزامی است. در این مقاله سعی شد تا علاوه بر تشریح فرمولهای ریاضی، پیاده سازی کدهای مربوطه در پایتون نیز بیان شود تا درک بهتری برای خواننده فراهم شود. امیدوار هستیم که این مقاله برای شما مفید بوده باشد. خوشحال میشویم نظرات و تجربیات خود را با ما در میان بگذارید.
اگر به یادگیری بیشتر در زمینه ی برنامه نویسی پایتون علاقه داری، یادگیری زبان پایتون بسیار ساده است. و با شرکت در دوره ی آموزش پایتون توسعه وب در آینده میتوانی اپلیکیشن موبایل و دسکتاپ بسازی و وارد حوزه ی هوش مصنوعی هم شوی.



۷ دیدگاه
۲۳ مرداد ۱۴۰۲، ۰۸:۲۱
نازنین کریمی مقدم
۱۹ شهریور ۱۴۰۲، ۱۰:۱۴
۱۳ تیر ۱۴۰۱، ۰۸:۱۸
۲۴ بهمن ۱۴۰۰، ۰۸:۴۸
۲۸ دی ۱۴۰۰، ۱۹:۰۷
مهتاب
۲۷ دی ۱۳۹۹، ۲۰:۵۶
لیلا افشار
۱۸ آذر ۱۳۹۹، ۰۰:۲۴

دوره الفبای برنامه نویسی با هدف انتخاب زبان برنامه نویسی مناسب برای شما و پاسخگویی به سوالات متداول در شروع یادگیری موقتا رایگان شد: