۰
دیدگاه
نظر

ACID در دیتابیس چیست؟ (توضیح کامل با مثالهای کاربردی)
سرفصلهای مقاله
- ACID چیه؟
- تفاوت "سازگاری" در ACID و "سازگاری" در CAP
- چرا تراکنشهای ACID مهمن؟
- مزایای دیتابیسهای ACID
- آیا دیتابیسهای NoSQL با ACID سازگار هستن؟
- آیا دیتابیسهای SQL توزیعشده با ACID سازگار هستن؟
- مثال تراکنش ACID در سیستم مدیریت پایگاه داده (DBMS)
- تراکنشهای ACID توی MongoDB چطور کار میکنن؟
- کی باید از تراکنشهای چند سندی MongoDB استفاده کنیم؟
- بهترین روشها برای کار با تراکنشها در MongoDB
- سوالات متداول
- جمعبندی
حفظ سازگاری و یکپارچگی دادهها توی تراکنشهای دیتابیس یه چیز خیلی مهم توی مهندسی نرمافزاره. مدل ACID دقیقاً همون اصول پایهای رو به ما میده که مطمئن بشیم دادههامون توی دیتابیس همیشه درست و قابل اعتماده. ACID مخفف چهار تا واژهٔ اتمیک بودن (Atomicity)، سازگاری (Consistency)، جداسازی (Isolation) و پایداری (Durability) هست. این اصول خیلی حیاتیان، مخصوصاً وقتی که سیستم کرش کنه یا مشکلات شبکهای پیش بیاد. همین اصول کمک میکنن که دادهها حتی توی سختترین شرایط هم سالم و بدون نقص باقی بمونن.
ACID چیه؟
همونطور که گفتیم ACID در واقع یه مخفف از چهار تا ویژگیه: اتمیک بودن (Atomicity)، سازگاری (Consistency)، جداسازی تراکنش (Isolation) و پایداری (Durability). اینا خیلی مهمن چون باعث میشن که دیتابیسها همیشه درست و مطمئن کار کنن، مخصوصاً وقتی چند تا تراکنش همزمان انجام میشن یا یه مشکلی مثل کرش کردن سیستم پیش میاد.
حالا بیا هر کدوم از این ویژگیها رو دونهدونه بررسی کنیم تا بفهمیم چرا اینقدر مهمن و چه نقشی دارن.
اتمیک بودن (Atomicity)
اتمیک بودن یعنی تراکنش مثل یه بستهٔ کامل و یکپارچه پردازش بشه. به این معنی که یا تمام عملیات توی اون تراکنش با موفقیت انجام بشن، یا هیچکدومشون. یه چیزی مثل این اصل همهچی یا هیچچی! این خیلی مهمه که دادهها دچار اشتباه نشن و باگها توی سیستم به وجود نیان.
مثلاً تصور کن میخوای از یه حساب بانکی پول انتقال بدی. تراکنش شامل اینه که از حساب خودت پول کم کنی و به حساب یه نفر دیگه اضافه کنی. اتمیک بودن تضمین میکنه که یا هر دو اتفاق همزمان میافتن (کم شدن و اضافه شدن) یا هیچکدوم! یعنی اگه سیستم درست وسط انتقال پول از حسابت خراب بشه، اتمیک بودن باعث میشه پول از حسابت کم نشه و همهچیز برگرده سرجاش.
سازگاری (Consistency)
سازگاری یعنی این که بعد از انجام یه تراکنش، دیتابیس باید همیشه توی یه وضعیت درست و معتبر بمونه. یعنی اگه قبل از تراکنش، دادهها توی دیتابیس درست بودن، بعد از تراکنش هم باید همینطور بمونن. این اصل جلوی ورود دادههای نادرست یا ناقص رو میگیره و مطمئن میشه که همهچیز طبق قوانین تعریفشده دیتابیس پیش میره.
یه مثال ساده بزنم. فرض کن توی دیتابیس یه قانون داریم که هیچکس نمیتونه بیشتر از ۱۰ میلیون توی حسابش داشته باشه. حالا اگه بخوای یه تراکنشی انجام بدی که باعث میشه موجودی یکی از حسابها به ۱۵ میلیون برسه، سازگاری جلوی این کار رو میگیره و تراکنش رد میشه، چون این قانون نقض شده. خلاصش اینه که دیتابیس همیشه طبق قوانین و قواعد خودش عمل میکنه و هیچوقت اطلاعات نادرست رو قبول نمیکنه.
جداسازی (Isolation)
جداسازی تراکنش یعنی هر تراکنشی که توی دیتابیس انجام میدی، بهصورت مستقل از تراکنشهای دیگه اجرا میشه. به زبون سادهتر، وقتی چند تا تراکنش همزمان توی دیتابیس در حال انجام شدن هستن، انگار که هر کدوم توی یه دنیای جداگانه در حال پردازش هستن و هیچکدوم نمیتونن کار همدیگه رو مختل کنن یا به اطلاعات هم دست بزنن.
مثلاً فرض کن دو نفر همزمان توی یه فروشگاه اینترنتی خرید میکنن. تراکنش اول باید موجودی انبار رو چک کنه و یه محصول رو کم کنه، و تراکنش دوم هم دقیقاً همزمان همون محصول رو میخواد بخره. Isolation تضمین میکنه که این دو تا تراکنش مستقل از همدیگه اجرا بشن و هیچکدوم باعث خراب شدن یا تداخل توی تراکنش دیگه نشه. یعنی تراکنشها با هم قاطی نمیشن و اطلاعاتشون هم با هم تداخل نداره.
پایداری (Durability)
پایداری یعنی وقتی یه تراکنش با موفقیت انجام شد، اطلاعات اون تراکنش برای همیشه توی دیتابیس ثبت و ذخیره میشن، حتی اگه سیستم بعدش خاموش بشه یا قطع برق اتفاق بیفته. به عبارت دیگه، اگه دیتابیس بهت بگه تراکنش انجام شده، دیگه خیالت راحت باشه که حتی با وجود مشکلات فنی، اطلاعات از دست نمیره.
یه مثال خوب از پایداری همون تراکنش بانکیه. فرض کن پولی رو به حساب دوستت انتقال دادی و پیام «تراکنش با موفقیت انجام شد» رو دریافت کردی. حالا اگه درست بعد از این پیام، برق کل شهر قطع بشه، نگران نباش. پایداری تضمین میکنه که اون تراکنش قبلاً توی دیتابیس ذخیره شده و وقتی سیستم دوباره روشن بشه، اطلاعاتت هم سرجاشه. پس هر چی تراکنش موفقیتآمیزه، دائمی و موندگاره!
تفاوت "سازگاری" در ACID و "سازگاری" در CAP

نظریه CAP میگه وقتی یه مشکلی توی شبکه رخ بده (مثل قطع شدن قسمتی از شبکه یا دیر رسیدن اطلاعات)، باید بین سازگاری (Consistency) و دسترسپذیری کامل (Availability) یکی رو انتخاب کنی. اینجا "سازگاری" یعنی همهٔ کسایی که به یه سیستم توزیعشده دسترسی دارن (مثل یه سری سرور یا کاربر)، باید همیشه یه نسخه دقیق و یکسان از دادهها رو ببینن. به بیان سادهتر، همه باید روی یه داده، یه نظر مشترک داشته باشن؛ مثلاً وقتی از چند نقطه مختلف به یه دیتابیس متصل میشن و یه داده رو میخونن، همگی همون مقدار داده رو ببینن. این مدل سازگاری رو بعضی وقتها بهش "سازگاری قوی" یا "خطیسازی" هم میگن.
اینجا سازگاری توی CAP بیشتر شبیه همون تفکیک تراکنشها (Isolation) توی ACID هست، چون هر دو دارن میگن که وقتی چند نفر دارن به اطلاعات نگاه میکنن، باید همون نسخه دقیق رو ببینن و تداخلی پیش نیاد.
اما توی ACID، سازگاری به چیز دیگهای اشاره داره. اینجا منظور اینه که هر وقت یه تراکنش تموم میشه، دیتابیس باید از یه وضعیت درست به یه وضعیت درست دیگه منتقل بشه. یعنی چی؟ یعنی اطلاعات باید همواره دقیق و مطابق با قواعد باشه. مثلاً اگه قراره عددی وارد بشه که باید مثبت باشه، دیتابیس نباید اجازه بده یه عدد منفی ثبت بشه. این سازگاری توی ACID درباره اینه که همهٔ قوانین دیتابیس رعایت بشن و دادهها همیشه معتبر بمونن.
تفاوت اصلی چیه؟
تفاوت اصلی اینه که "سازگاری" توی CAP بیشتر به این اشاره داره که همه همزمان یه داده درست رو ببینن (همه با هم تو یه لحظه، همون مقدار رو میخونن). اما "سازگاری" توی ACID به این معنیه که بعد از یه تراکنش، اطلاعات دیتابیس همچنان معتبر و درست باقی بمونه و هیچ قانونی شکسته نشه.
برای همین، وقتی درباره "سازگاری" صحبت میکنیم، باید بدونیم که توی ACID و CAP به دو موضوع متفاوت اشاره داریم:
- توی CAP، "سازگاری" یعنی همه یه نسخه همزمان از داده رو ببینن.
- توی ACID، "سازگاری" یعنی قوانین دیتابیس همیشه درست رعایت بشن و اطلاعات صحیح باشه.
چرا تراکنشهای ACID مهمن؟
تراکنشهای ACID باعث میشن که دادهها همیشه دقیق و درست باشن. این یعنی هر چی توی دیتابیس ثبت میکنی، بدون خطا و کاملاً قابل اطمینانه. حالا فکر کن این چقدر مهمه وقتی که داریم درباره دادههای حساس مثل حسابهای بانکی یا پورتفوی سهام حرف میزنیم. این اطلاعات باید با قوانین دولتی یا صنعتی مطابقت داشته باشن و کوچکترین اشتباه توشون میتونه فاجعهبار باشه. از طرف دیگه، رعایت اصول ACID برای پیادهسازی ویژگیهایی مثل تکرار داده و دستیابی به دسترسپذیری بالا توی سیستمهای توزیعشده (مثلاً دیتابیسهای توی فضای ابری) هم خیلی مهمه.
مزایای دیتابیسهای ACID
رعایت اصول ACID باعث میشه که دادهها همیشه درست، منظم و بدون خطا باشن. این موضوع نه تنها برای کسبوکارها مفیده، بلکه برای مشتریها و شریکهای کاریت هم خیلی ارزشمنده. دیتابیسهایی که اصول ACID رو رعایت میکنن، این مزایا رو دارن:
- از دست ندادن اطلاعات مشتریها حتی در صورت بروز مشکل توی سیستم یا فضای ابری
- جلوگیری از ایجاد دادههای نادرست یا تکراری بهصورت تصادفی
- اطمینان کامل به اینکه تمام عملیاتها دقیق، پیشبینیشده و قابلاعتمادن
رعایت ACID کمک میکنه که کسبوکارت بتونه تصمیمهای بهتری بگیره، مشکلات مشتریها رو که بهخاطر خطاهای داده به وجود میاد کاهش بده و کارها خیلی روانتر پیش برن.
آیا دیتابیسهای NoSQL با ACID سازگار هستن؟
دیتابیسهای NoSQL که اواخر دهه ۲۰۰۰ به وجود اومدن، در اصل برای حل مشکلات مربوط به بیگ دیتا و مدیریت دادههای غیرساختاریافته طراحی شدن. این دیتابیسها سرعت بالایی دارن و با رویکرد سادهتری به سراغ سازماندهی دادهها میرن. از طرفی، میتونن با انواع مختلف دادهها کار کنن و انعطافپذیری بیشتری داشته باشن.
اما یه چالش اصلی اینجا وجود داشت: طراحان NoSQL باید بین دو ویژگی مهم یکی رو انتخاب میکردن: دسترسپذیری (Availability) یا سازگاری (Consistency). در نهایت، دسترسپذیری برنده شد، یعنی اولویت دادن به اینکه سیستم همیشه در دسترس باشه، حتی اگه سازگاری دادهها بهصورت لحظهای کامل نباشه.
این تصمیم باعث شد که توی بعضی موارد، سازگاری فوری دادهها قربانی بشه و بهجاش از سازگاری نهایی استفاده بشه؛ یعنی دادهها بعد از یه مدت به حالت درست و هماهنگ میرسن، ولی ممکنه این اتفاق بلافاصله نیفته.
این انتخاب همچنین باعث شد که ویژگیهای مهمی مثل اتمیک بودن (Atomicity) و تفکیک تراکنشها (Isolation) توی NoSQL کمتر رعایت بشه. ولی چون اون موقع حجم دادهها خیلی زیاد نبود، راهحلهایی مثل مقیاسدهی عمودی (افزایش قدرت سرورهای موجود) جوابگو بود. با این حال، وقتی دیتابیسها بزرگتر شدن و تعداد دادهها زیادتر شد، این روش دیگه کافی نبود و نیاز به تغییرات جدیدی به وجود اومد.
آیا دیتابیسهای SQL توزیعشده با ACID سازگار هستن؟
بله! دیتابیسهای SQL توزیعشده مثل YugabyteDB میتونن ترکیبی از ویژگیهای یه دیتابیس رابطهای (یعنی SQL) که کاملاً با ACID سازگاره رو با مزایای یه دیتابیس توزیعشده مقیاسپذیر (مثل NoSQL) ارائه بدن. یعنی هم از دقت و یکپارچگی دادهها مطمئن میشی و هم از سرعت و مقیاسپذیری بالا بهرهمند میشی!
مثال تراکنش ACID در سیستم مدیریت پایگاه داده (DBMS)
فرض کن داری از دیتابیس NoSQL مثل MongoDB Atlas استفاده میکنی و میخوای بدونی چطور تراکنشهای ACID با چندین سند (multi-document) توی این سیستم کار میکنن. بذار با یه مثال خیلی ساده توضیح بدم که این تراکنشها چطور باعث میشن که همه چیز درست و طبق اصول ACID پیش بره.
تراکنش ACID با چند سند
تصور کن میخوای یه تابع بنویسی که پول رو از یه حساب بانکی به حساب دیگه منتقل کنه. هر حساب توی دیتابیس خودش یه رکورد جدا داره. حالا اگه پول از حساب اول کم بشه، اما به حساب دوم واریز نشه، یه مشکل بزرگ مالی به وجود میاد. یا برعکس، اگه به حساب دوم پول اضافه بشه ولی از حساب اول کم نشه، باز هم یه اشکال جدی توی حسابها پیش میاد.
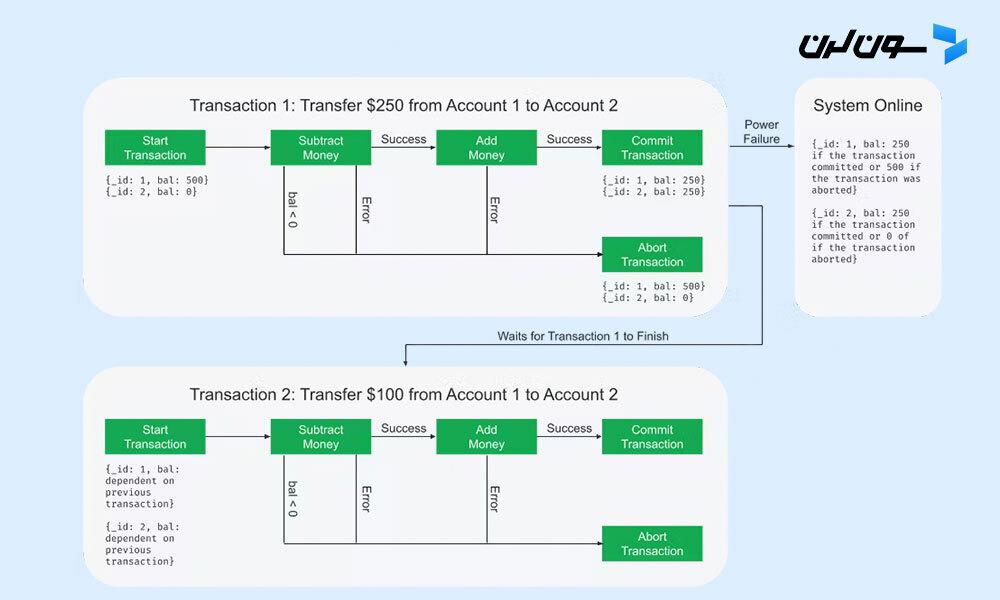
اینجاست که اصول ACID وارد میشن. این اصول تضمین میکنن که یا هر دو عملیات (کم کردن از حساب اول و اضافه کردن به حساب دوم) با هم انجام بشن، یا اگه مشکلی پیش اومد، هیچکدومشون اتفاق نیفته. این یعنی، دیتابیس باید هر تغییری که طی تراکنش ایجاد شده رو برگردونه (یا به اصطلاح رولبک کنه) اگه یکی از دستورها با شکست مواجه شد.
نکات مهمی که باید به خاطر بسپاری
وقتی داری با تراکنشهایی که چند سند رو در بر میگیرن کار میکنی (مخصوصاً توی سیستمهای توزیعشده)، باید حواست باشه که این کارها ممکنه به عملکرد سیستم فشار بیاره. چون دیتابیس برای اینکه جلوی تداخلهای همزمان رو بگیره (یعنی دو نفر همزمان نتونن روی همون دادهها تغییری ایجاد کنن)، منابع رو قفل میکنه. این میتونه باعث بشه که کاربرهای دیگهای که میخوان همزمان دادهها رو تغییر بدن، منتظر بمونن تا تراکنش فعلی تموم بشه. این موضوع ممکنه روی سرعت برنامه و تجربه کاربر تأثیر بذاره.
تراکنشهای ACID توی MongoDB چطور کار میکنن؟
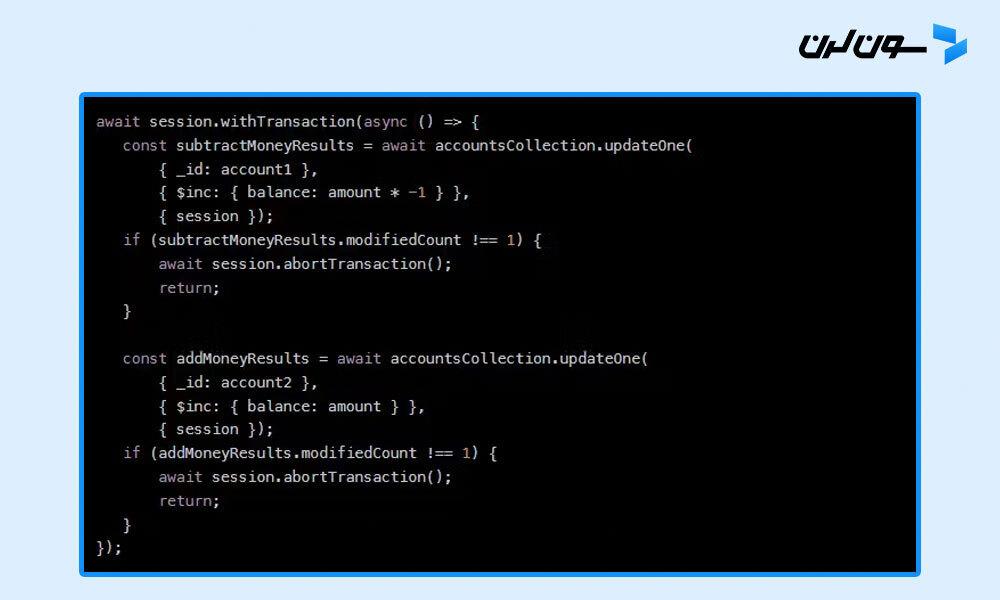
توی MongoDB، مدل سندی بهت اجازه میده که دادههای مرتبط رو توی یه سند ذخیره کنی. این مدل، همراه با قابلیت بهروزرسانی اتمیک سند، توی بیشتر مواقع باعث میشه نیازی به تراکنش نداشته باشی. اما خب، بعضی وقتها پیش میاد که واقعاً به تراکنشهای چند سندی و چند کالکشنی نیاز داری.
تراکنشهای MongoDB هم تقریباً شبیه تراکنشهای دیتابیسهای دیگه کار میکنن. برای شروع یه تراکنش، اول باید یه سشن (session) توی MongoDB باز کنی (از طریق یه درایور). بعدش، از اون سشن استفاده میکنی تا عملیاتهای دیتابیسی مورد نظر رو اجرا کنی. میتونی هرکدوم از عملیات CRUD (ساخت، خوندن، آپدیت و حذف) رو روی چندین سند، کالکشن یا حتی شارد (shard) مختلف انجام بدی.
کی باید از تراکنشهای چند سندی MongoDB استفاده کنیم؟
برنامههایی که به تراکنش نیاز دارن، معمولاً اونایی هستن که توشون ارزشهایی بین طرفهای مختلف رد و بدل میشه. این برنامهها معمولاً سیستمهای اصلی (System of Record) یا برنامههای تجاری (Line of Business) هستن.
چند تا مثال از کاربردهایی که ممکنه از تراکنشهای چند سندی بهره ببرن:
- سیستمهایی که پول رو از یه حساب به حساب دیگه منتقل میکنن (مثل اپلیکیشنهای بانکی، سیستمهای پردازش پرداخت، یا پلتفرمهای معاملهگری).
- سیستمهای زنجیره تأمین و رزرو که مالکیت کالاها و خدمات بین طرفین مختلف جابجا میشه.
- سیستمهای صورتحساب که اطلاعات رو هم توی رکوردهای دقیق و هم توی رکوردهای خلاصه ذخیره میکنن.
این نوع تراکنشها بهت کمک میکنن که مطمئن بشی همه چی بهصورت یکپارچه و بدون هیچ ایرادی پیش میره.
بهترین روشها برای کار با تراکنشها در MongoDB
در کل، یه توصیه خیلی مهم اینه که دادههایی که معمولاً با هم استفاده میشن رو کنار هم توی یکجا ذخیره کنی. با این کار، هم سرعت و عملکرد سیستم بهتر میشه و هم در بیشتر موارد اصلاً نیازی به استفاده از تراکنش نداری!
ولی اگه برنامت به تراکنش نیاز داره، این چندتا نکته رو حتماً رعایت کن:
- تراکنشهای طولانی رو به بخشهای کوچیکتر تقسیم کن. اینطوری مطمئن میشی که از تایماوت پیشفرض ۶۰ ثانیهای رد نمیشن (البته میتونی این تایماوت رو بیشتر هم کنی). همچنین، مطمئن شو که همه عملیاتهای تراکنشت از ایندکسها استفاده میکنن تا سریعتر اجرا بشن.
- هر تراکنش رو به ۱۰۰۰ تغییر سند محدود کن. این کار باعث میشه کارایی سیستم حفظ بشه و به مشکل نخوری.
- تنظیمات مربوط به خواندن و نوشتن رو درست تنظیم کن. از نسخه ۵.۰ به بعد، MongoDB بهطور پیشفرض از نوشتن با اکثر کاربران (majority write concern) استفاده میکنه که یعنی عملیاتها برای اکثر گرهها ثبت میشن تا مطمئن باشی همه چیز درسته.
- مدیریت خطاها رو فراموش نکن! اگه تراکنشی به خاطر خطاهای موقتی شکست خورد، حتماً مکانیزمهایی برای تکرار مجدد (retry) تراکنشها داشته باش.
- به هزینه عملکردی تراکنشهایی که چندین شارد رو درگیر میکنن توجه کن. این نوع تراکنشها معمولاً سنگینترن و ممکنه عملکرد سیستم رو تحت تأثیر قرار بدن.
سوالات متداول

1. تراکنشهای چند سندی (multi-document transactions) چی هستن؟
تراکنشهای چند سندی به تراکنشهایی گفته میشه که شامل چندین عملیات وابسته به هم هستن و این عملیاتها ممکنه در دیتابیسها و سیستمهای مختلف پخش بشن. به این نوع تراکنشها گاهی "تراکنشهای توزیعشده" هم میگن.
2. تراکنشهای ACID چی هستن؟
تراکنش ACID مجموعهای از عملیات توی یه سیستم دیتابیسیه که طبق اصول ACID انجام میشه.
3. اصول ACID توی تراکنشها چی هستن؟
چهار تا ویژگی کلیدی ACID شامل: اتمیک بودن (Atomicity)، سازگاری (Consistency)، تفکیک (Isolation) و پایداری (Durability) هستن. این ویژگیها تضمین میکنن که تراکنشهای دیتابیس حتی در صورت بروز خطا یا مشکلات سیستمی به درستی انجام بشن.
4. چرا به اصول ACID نیاز داریم؟
این چهار اصل کمک میکنن که دقت و یکپارچگی دادهها همیشه حفظ بشه. با رعایت ACID، همه تغییرات توی دادهها بهصورت یکپارچه و درست انجام میشن، به شکلی که عملیاتها جدا از هم و با نتیجههای ثابت و پایدار انجام بشن.
5. تفاوت "سازگاری" در ACID و "سازگاری" توی نظریه CAP چیه؟
تو نظریه CAP، سازگاری یعنی همه اعضای یه سیستم توزیعشده باید در مورد یه مقدار داده توافق داشته باشن. اما تو ACID، سازگاری مربوط به حفظ یکپارچگی دادهها هنگام انتقال از یه حالت به حالت دیگه هست، و این تضمین قویتری نسبت به سازگاری تو CAP ارائه میده.
6. Linearizability چیه؟
Linearizability یا "سازگاری قوی" قویترین مدل سازگاری تو سیستمهای توزیع شدهست. این مفهوم یعنی همه کاربران یه سیستم توزیع شده باید یه مقدار داده رو بهصورت یکسان و همزمان ببینن.
7. چه دیتابیسهایی از ACID استفاده میکنن؟
دیتابیسهای رابطهای مثل MySQL، PostgreSQL، Oracle و دیتابیسهای SQL توزیع شده مثل YugabyteDB همگی از تراکنشهای ACID استفاده میکنن و تضمین میکنن که تراکنشها بهدرستی انجام بشن.
8. آیا دیتابیسهای SQL با ACID سازگار هستن؟
بله، دیتابیسهای SQL سنتی تراکنشهای ACID رو با دقت و سازگاری بالا ارائه میدن که برای سیستمهای مالی و تجاری خیلی مهمه. البته مقیاسپذیری افقی توی دیتابیسهای SQL سنتی پیچیده و گرونه، اما دیتابیسهای SQL توزیعشده این مشکل رو با ترکیب مقیاسپذیری و تضمینهای ACID حل میکنن.
9. آیا دیتابیسهای NoSQL با ACID سازگار هستن؟
نه بهطور پیشفرض. دیتابیسهای NoSQL بیشتر روی مقیاسپذیری افقی تمرکز دارن و ACID اولویت اولشون نبوده. تو NoSQL، دادهها به مرور زمان بین سرورها هماهنگ میشن، ولی این اتفاق فوراً نمیوفته، که باعث میشه گاهی دادهها ناهماهنگ باشن. این روش باعث میشه دسترسپذیری و سرعت خوندن دادهها بهتر بشه، ولی از طرف دیگه، سازگاری رو قربانی میکنه.
10. آیا دیتابیس YugabyteDB با ACID سازگاره؟
بله، YugabyteDB از تراکنشهای ACID پشتیبانی میکنه و در عین حال از مقیاسپذیری و پایداری سیستم هم کم نمیذاره. این دیتابیس ترکیبی از ویژگیهای عالی مثل سرعت بالا، مقیاسپذیری، پخش جغرافیایی، و سازگاری با ACID رو بهت میده.
جمعبندی
در نهایت، اصول ACID یکی از پایهایترین و مهمترین مفاهیم در مدیریت دیتابیسها هستن. این چهار ویژگی، یعنی اتمیک بودن، سازگاری، تفکیک، و پایداری، به ما اطمینان میدن که دادهها بهشکل درست و مطمئن مدیریت میشن، حتی در شرایطی که سیستم دچار خطا، قطع برق، یا مشکلات شبکهای میشه. استفاده از دیتابیسهای سازگار با ACID مثل MySQL، PostgreSQL، و MongoDB، به کسبوکارها کمک میکنه که با اعتماد کامل دادههای حساس خودشون رو ذخیره و مدیریت کنن.
همچنین، فهم تفاوت بین "سازگاری" توی ACID و CAP و انتخاب سیستم مناسب برای کاربرد خاص خودت، بهت کمک میکنه تا در شرایط مختلف بهترین عملکرد رو از دیتابیس بگیری. دیتابیسهای NoSQL به خاطر سرعت و مقیاسپذیری بهتر تو شرایط خاصی مناسبن، اما اگه به یکپارچگی و دقت بالا نیاز داری، دیتابیسهای ACID بهترین گزینن.
در نهایت، انتخاب دیتابیس و استفاده درست از اصول ACID میتونه تاثیر مستقیمی روی کارایی، دقت، و عملکرد سیستمهای نرمافزاری داشته باشه.



۰ دیدگاه


دوره الفبای برنامه نویسی با هدف انتخاب زبان برنامه نویسی مناسب برای شما و پاسخگویی به سوالات متداول در شروع یادگیری موقتا رایگان شد: