۶
دیدگاه
نظر

Elasticsearch چیست؟
سرفصلهای مقاله
- Elasticsearch چیست؟
- Elasticsearch در کجا استفاده میشود؟
- مفاهیم مورد استفاده ی Elasticsearch
- سازوکار Elasticsearch چیست؟
- مزایای استفاده از Elasticsearch چیست؟
- معایب Elasticsearch چیست؟
- نصب Elasticsearch و شروع کار با آن
- ابزارهای مرتبط با Elasticsearch چیست؟
در دنیای فناوری کنونی، هر روز حجم زیادی از داده به میزان تقریبی ۲.۵ کوینتیلیون (Quintillion) بایت (چیزی حدود 2.5 میلیارد میلیارد بایت) تولید میشود. این اطلاعات به طور عمده از منابع مختلف، به عنوان مثال، سایتهای ارتباط جمعی، سایتهای اشتراک ویدیو و رسانه برای سازمانهای بزرگ در مقیاس بزرگ به دست میآید. این دادهها به عنوان اقیانوس داده یا به طور کلیتر به عنوان دادههای بزرگ (Big Data) نامیده میشوند. بخش قابل توجهی از این دادهها غیرساختاریافته (unstructured) و پراکنده هستند و فرد برای درک آن به ابزار تحلیلی نیاز دارد. ابزارهای تحلیلی زیادی در بازار وجود دارد که با استفاده از آن میتوان به بررسی، ثبت، تحلیل و پردازش این دادهها اشاره کرد. یکی از پرکاربردترین این ابزارها، Elasticsearch است. لذا میخواهیم در این مقاله در مورد اینکه Elasticsearch چیست؟ صحبت کنیم.
Elasticsearch چیست؟
Elasticsearch محصول شرکتی به نام الاستیک (Elastic) است که در سال ۲۰۱۲ بنیان گذاشته شد. Elasticsearch یک موتور جستجوی متن باز با تجزیه و تحلیل کامل است که به زبان جاوا توسعه یافته است. دادههای غیرساختاریافته را از منابع مختلف میگیرد و آن را در یک فرمت پیچیده ذخیره میکند که برای جستجوی متنی بسیار بهینه است. Elasticsearch از Lucene Apache در هسته ی خود برای نمایه سازی و جستجو استفاده میکند. Lucene کتابخانه ای است که کار کردن با آن واقعا پیچیده است؛ اما لازم نیست نگران آن بود چرا که Elasticsearch تمام پیچیدگیها را با فراهم کردن قابلیت استفاده از API از بین میبرد. API به شکل API RESTful HTTP است که از JSON به عنوان فرمت تبادل داده استفاده میکند؛ در نتیجه با استفاده از Elasticsearch میتوان حجم زیادی از دادهها را به روش سریع و کارآمد ذخیره و تحلیل کرد. این امر به خصوص در هنگام برخورد با دادههای نیمه ساختاریافته ی زبان طبیعی بسیار مفید است.
Elasticsearch در کجا استفاده میشود؟
مقیاس پذیری (scalability) و سرعت Elasticsearch بالاست و میتوان از آن برای موارد زیر استفاده کرد:
جستجوی برنامه
جستجوی وب سایت
جستجوی سازمانی
تحلیل و تجزیه ی اطلاعات ورودی
بررسی عملکرد برنامه
آنالیز و تجسم داده ها
تجزیه و تحلیل امنیتی
تجزیه و تحلیل تجاری
مفاهیم مورد استفاده ی Elasticsearch
برای آشنایی و درک بهتر اینکه Elasticsearch چیست؟ مفاهیمی وجود دارند که باید با آنها آشنا شویم:
تقریبا بلادرنگ (Near Real-Time)
Elasticsearch یک سکوی جستجوی بلادرنگ است؛ به این معنی است که میتواند به طور پیوسته یک وضعیت جدید از اسناد قابل جستجو را برنامه ریزی کند. نرخ پیش فرض، هر وضعیت در ثانیه است. بنابراین میزان زمان از لحظه ی جستجوی سند توسط کاربر تا لحظه ی اعلام نتایج کم و ناچیز میباشد.
شاخص (Index)
Elasticsearch مجموعه ای از اسناد است که دارای ویژگیهای مشابهی هستند. این دادهها با استفاده از دستورات SQL در یک یا چند شاخص ذخیره میشوند و از شاخصها برای نگهداری و خواندن اسناد از آن استفاده میشود. در Elasticsearch، یک شاخص با نامی منحصر به فرد شناسایی میشود و باید تمام حروفش کوچک باشد. سپس از این نام برای اشاره به یک شاخص خاص در هنگام انجام فعالیتهای مختلف بر روی اسناد موجود استفاده میشود.
سند (Document)
در Elasticsearch، یک سند، واحد اصلی اطلاعاتی است که میتوان شاخص کرد. این اسناد شامل فیلدهای مختلفی هستند و هر یک از این فیلدها با نام خود شناسایی شده اند و میتوانند حاوی یک یا چند مقدار باشند. همچنین اسناد کاملا رایگان هستند و میتوان چند سند در یک شاخص ذخیره کرد.
نوع (Type)
در Elasticsearch، یک نوع برای اسناد متشکل از مجموعه ا ی از فیلدها تعریف میشود. نوع سند توسط کاربر تعریف شده و همچنین میتوان بیش از یک نوع را در یک شاخص مشخص کرد.
گره (Node)
گره به یک نمونه از سرور Elasticsearch گفته میشود که دادهها را ذخیره میکند. یک گره دارای نام است و با آن شناسایی میشود. به طور پیش فرض در زمان شروع، یک شناسه ی منحصر به فرد تصادفی به گره تخصیص داده میشود. این نام برای اهداف اجرایی مورد استفاده قرار میگیرد.
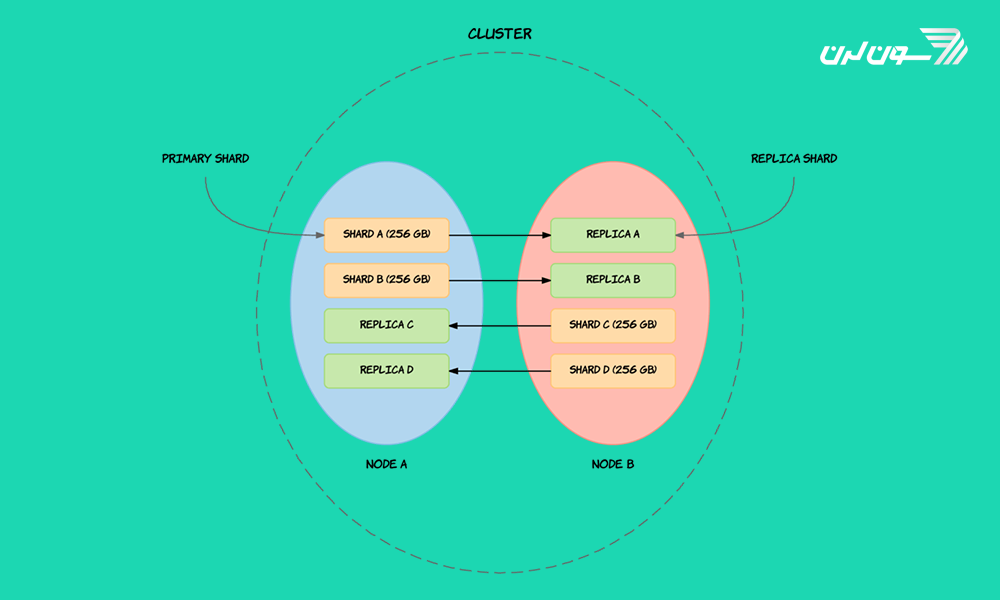
خوشه (Cluster)
یک خوشه مجموعه ای از یک یا چند گره یا همان سرور است که با هم کار میکنند. خوشه تمامی دادهها را نگه میدارد و امکان جستجوی آسان را در تمام گرهها فراهم میکند و موجب کنترل آسان اطلاعات برای هر گره میشود. همانند یک گره، یک خوشه نیز با نام منحصر به فرد مشخص میشود و به طور پیش فرض، نامش "elasticsearch" است. برای اتصال چند گره به یک خوشه از نام خوشه استفاده میشود و به همین دلیل است که نام خوشه بسیار مهم است.
Shards
ذخیره ی حجم زیادی از اطلاعات میتواند فراتر از تواناییهای یک سرور واحد باشد. برای حل این مشکل، Elasticsearch اجازه میدهد تا شاخص را به چند بخش تقسیم کرد که shards نامیده میشوند. تعداد بخشهای مورد نیاز میتواند در حین ایجاد یک شاخص مشخص شود. هر shard برای هر شاخص کاملا مستقل است و میتواند میزبان هر گره درون خوشه باشد.
Replicas
برای جلوگیری از هر نوع خطای تصادفی، مانند اشتراک گذاری یک گره ی آفلاین، Elasticsearch مفهومی شبیه به کپی را ارائه میدهد. Replicas در اصل فقط یک کپی دیگر از یک تکه است و میتواند برای پرس وجوها به عنوان تکه ی اصلی مورد استفاده قرار گیرد.

سازوکار Elasticsearch چیست؟
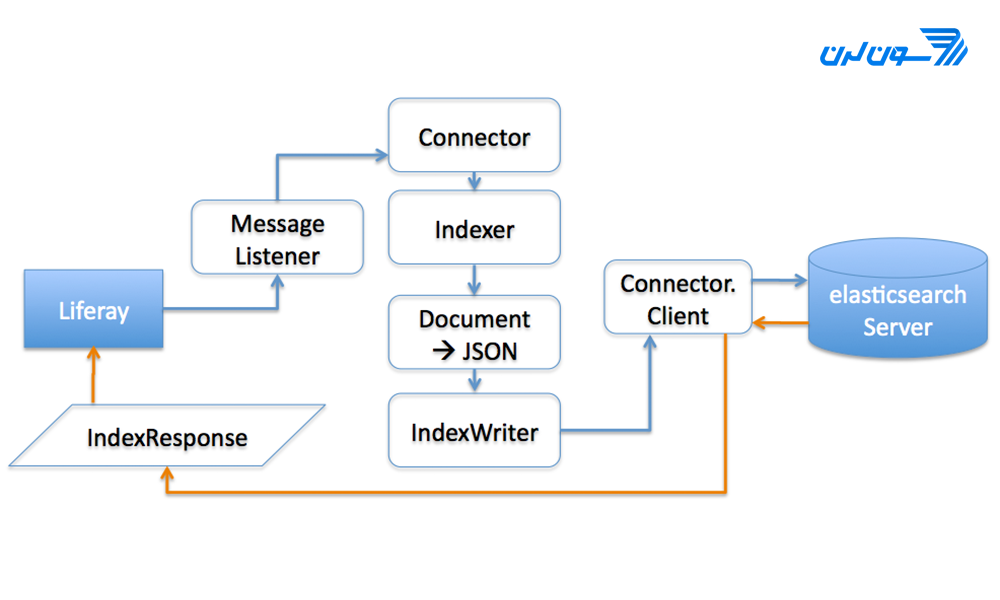
Elasticsearch مجموعه ای از اسناد است که با هم مرتبط هستند و دادهها را به عنوان اسناد JSON ذخیره میکند. هر سند مجموعه ای از کلیدها را با مقادیر متناظر خود مانند رشته ها، اعداد، Booleans، تاریخ ها، آرایههای حاوی مقادیر یا انواع دیگر دادهها مرتبط میکند.
Elasticsearch همچنین از یک ساختار داده با نام شاخص معکوس استفاده میکند که برای جستجوهای کامل متن (full text) طراحی شده است. یک شاخص معکوس، هر کلمه ی منحصر به فرد که در هر سند نمایان میشود را لیست میکند و تمام اسنادی را که آن کلمه در آن رخ میدهد را مشخص میکند.
در طول فرآیند شاخص گذاری، Elasticsearch اسناد را ذخیره کرده و یک شاخص معکوس ایجاد میکند تا دادهها در زمان واقعی قابل جستجو باشند. نمایه سازی با API آغاز میشود که از طریق آن میتوان یک سند JSON را در یک شاخص مشخص بروزرسانی یا اضافه کرد. APIهای مطرح عبارتند از:
Index API: برای ثبت شاخص استفاده میشود.
Get API: برای بازیابی سند استفاده میشود.
API Searh: برای ارسال درخواست و دریافت نتیجه استفاده میشود.
Put API: برای انتخاب گزینههای پیش فرض و تعریف نقشه استفاده میشود.
همچنین میتوان APIهای دیگری را براساس نیاز بررسی و ایجاد کرد؛ چراکه پروژههای دنیای واقعی نیازمند پرس وجوهای متفاوت در زمینههای گوناگون با اعمال شرایط مخصوص به خود هستند.
تمام این پیچیدگی را میتوان از طریق پرس وجوها آسان کرد. DSL پرس وجویی قدرتمند است و برای رسیدگی به پیچیدگی از طریق یک پرس وجو طراحی شده است. APIهای Elasticsearch به طور مستقیم با lucene ارتباط دارند و از همین نام برای کار با lucene استفاده میکنند. DSL نیز از Lucene TermQuery برای اجرا استفاده میکند.
مزایای استفاده از Elasticsearch چیست؟
استفاده از Elasticsearch دارای مزایای زیادی است؛ از این مزایا میتوان به موارد زیر اشاره کرد:
مقیاس پذیری: یعنی با افزایش حجم داده ها، عملکرد همچنان بسیار ساده مانده و نتایج قابل اطمینان است. این یک ویژگی بسیار مهم است که به ساده سازی معماریهای پیچیده و صرفه جویی در زمان در طول اجرای پروژهها کمک میکند.
سرعت: Elasticsearch از شاخص گذاری معکوس استفاده میکند. همان طور که در بخش قبل آموختیم، شاخص گذاری معکوس یک روش مبتني بر کلمه است که براي جستجوی سريع اسناد شامل يک کلمه ی خاص به کار میرود. در نتیجه حتی زمانی هم که در مجموعه دادههای بسیار بزرگ جستجو میکند، بسیار سریع است.
استفاده از API: Elasticsearch APIهای ساده RESTful را ارائه میدهد و از اسناد JSON، بدون الگو استفاده میکند که نمایه سازی، جستجو و پرس و جوی دادهها را بسیار آسان میسازد.
چندزبانه: یکی از ویژگیهای Elasticsearch این است که چندزبانه است. این موتور از نوشتارهای گسترده ای در زبانهای مختلف مانند عربی، برزیلی، چینی، انگلیسی، فرانسوی، کره ای و ... پشتیبانی میکند.
بهینه بودن در کار با اسناد: Elasticsearch ماهیت پیچیده ی دنیای واقعی را به عنوان اسناد JSON ساختاربندی کرده و تمام مفاهیم را به طور پیش فرض در یک شاخص (index) جمع آوری میکند تا بتوان دادهها را جستجو کرد. از آنجا که هیچ ردیف و ستون داده ای وجود ندارد، میتوان به راحتی جستجوی متن کامل را انجام داد.
تکمیل خودکار: Elasticsearch با پیش بینی کلمه (حتی اگر شامل تعداد بسیار کمی از کاراکترها باشد) ، تعامل انسان و رایانه را سرعت میبخشد.
شِمای رایگان: Elasticsearch با وجود اینکه اسناد JSON را میپذیرد، عاری از شِما است. در واقع Elasticsearch سعی میکند ساختار دادهها را شناسایی کند، دادهها را شاخص بندی کند و در نهایت بتواند دادهها را جستجو کند.
معایب Elasticsearch چیست؟
باید توجه داشت که هنگامی از Elasticsearch باید استفاده کرد که دادههای مورد بررسی دارای ویژگی هایی باشند که بتوان از نقاط قوت Elasticsearch استفاده کرد. چرا که اگر این گونه نباشد، نتیجه معکوس خواهد شد و آن جنبههای بیان شده به عنوان مزایا، تبدیل به معایب کار میشوند. با این حال Elasticsearch نیز خالی از عیب نیست. برخی از این معایب عبارتند از:
Elasticsearch از لحاظ مدیریت درخواست و پاسخ هنگام کار با سرویس ها، برخلاف برخی سیستمها که در فرمتهای CSV، XML و JSON هم کار میکنند، پشتیبانی چند زبانی ندارد.
Elasticsearch همچنین دارای مشکل split brain میباشد. این مشکل هنگامی به وجود میآید که برقراری ارتباط بین سرورها قطع میشود و نگهداری دو مجموعه ی داده ی مجزا که در یک موضوع همپوشانی دارند، دچار مشکل میشود.
اگر فرد به آن مسلط نباشد، استفاده از ابزارهایی مانند Algolia آسان نیست. البته همان طور که گفتیم، Elasticsearch روشی قدرتمندتر و انعطاف پذیرتر از حالت عادی است، اما باز هم یادگیری آن زمانبر است.
نصب Elasticsearch و شروع کار با آن
پیشتر گفتیم که Elasticsearch در جاوا توسعه یافته است؛ لذا در مرحله ی اول باید جدیدترین نسخه ی جاوا را نصب کنید و یا اگر جاوا نصب شده باشد نسخه ی آن را با استفاده از دستور زبان جاوا در cmd چک کنید. البته توجه داشته باشید که کتابخانههای زیادی برای استفاده از Elasticsearch با سایر زبانهای برنامه نویسی مانند .NET(C#)، پایتون، جاوا اسکریپت، PHP، روبی، پرل و ... گسترش یافته است.
در مرحله ی دوم باید به سایت Elasticsearch رفته و آن را دانلود کنید. فایل زیپ را از حالت فشرده خارج کرده، در سرور قرار دهید و با دابل کلیک در فایل .bat در مسیر elasticsearch-x.y.z/bin آن را اجرا کنید.
در مرحله ی سوم منتظر بمانید تا شروع به کار کند. در مرورگر بنویسید: localhost:9200 یا 127.0.0.1:9200، چون به طور پیش فرض elasticsearch روی آی پی (IP) لوکال و پورت 9200 اجرا شده و قابل استفاده است.
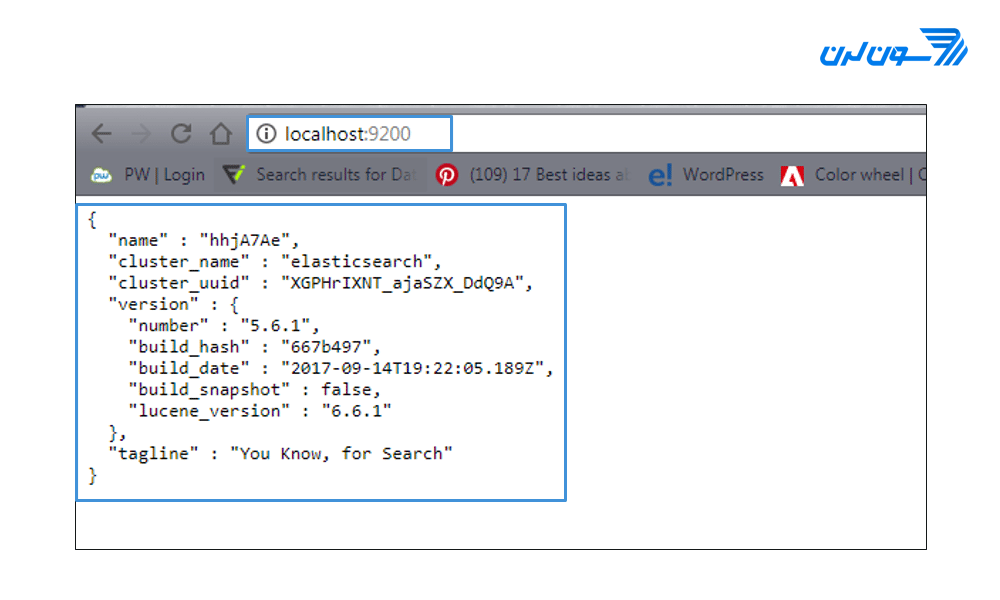
اگر بتوانید پیغام مشخص شده در مرورگر را ببینید، به این معنی است که همه چیز صحیح است. اگر در نصب سوال دارید یا خطایی گرفتید میتوانید در بخش نظرات آن را درمیان بگذارید.
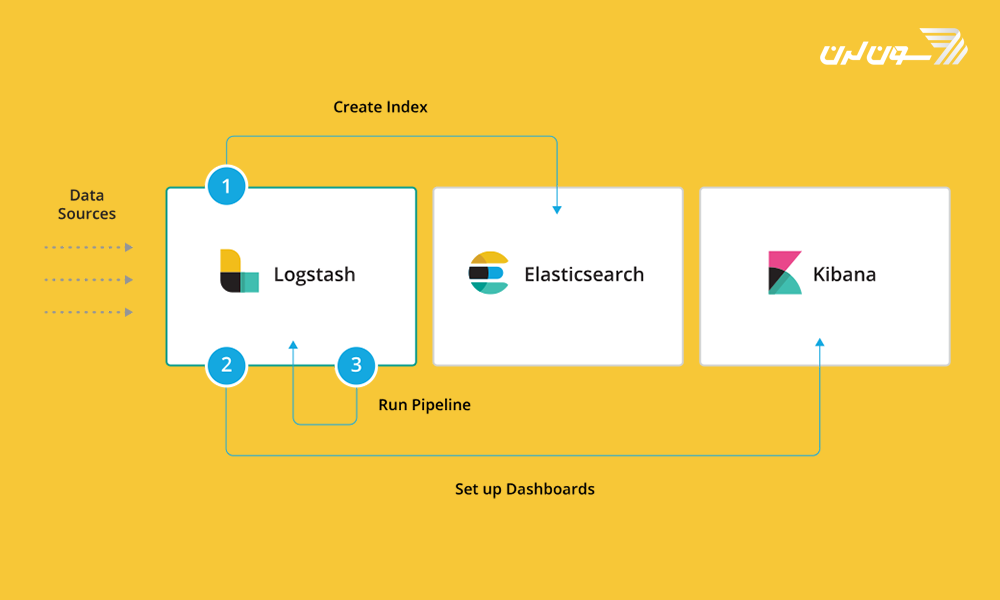
ابزارهای مرتبط با Elasticsearch چیست؟
شرکت الاستیک چند ابزار برای راحتتر کار کردن با Elasticsearch توصیه کرده است که عبارتند از:
Logstash: یکی از محصولات اصلی الاستیک است که برای جمع آوری و پردازش داده و ارسال آن به Elasticsearch استفاده میشود. Logstash یک خط لوله ی پردازش داده ی مبتنی بر سرور است که این امکان را میدهد که دادهها را از منابع چندگانه به طور همزمان جذب کرده و آنها را قبل از شاخص گذاری در Elasticsearch تبدیل نمود.
Kibana: یک ابزار تجسم و مدیریت برای Elasticsearch است که نمودار هیستوگرام، نمودار خط، نمودار دایره ای، و نقشهها را فراهم میکند. Kibana همچنین شامل برنامههای پیشرفته ای میباشد که به کاربران اجازه میدهد تا به منظور تجسم بهتر دادههای مکانی، اینفوگرافیکهای پویا را به صورت سفارشی و براساس دادهها ایجاد کنند.
جمع بندی:
Elasticsearch یک موتور قوی و با امکانات بالا برای جستجو و تحلیل داده است. در مقاله ی Elasticsearch چیست؟ ابتدا مروری بر اصطلاحات مرتبط داشتیم و سپس در مورد سازوکار Elasticsearch، مزایا و معایب آن و طریقه ی نصب صحبت کردیم. در پایان هم دو ابزار کاربردی که با Elasticsearch در تعامل هستند را معرفی کردیم. کتابخانههای زیادی برای کار با Elasticsearch توسعه یافته اند که بسته به نیاز و زبان برنامه نویسی میتوانید از آنها استفاده کنید. برای تمرین بیشتر و کار با Elasticsearch میتوانید.
اگر به مباحث فریم ورک لاراول علاقه مند هستید پیشنهاد میکنیم در دوره آموزش لاراول سون لرن شرکت کنید.



۶ دیدگاه
۲۳ مرداد ۱۴۰۱، ۰۴:۱۳
۰۷ اردیبهشت ۱۴۰۱، ۰۵:۳۸
iliya
۰۴ اردیبهشت ۱۴۰۰، ۰۹:۴۹
معین
۲۴ آبان ۱۳۹۹، ۱۲:۱۹
پوریا
۱۶ اردیبهشت ۱۳۹۹، ۰۹:۳۰
نازنین کریمی مقدم
۱۷ اردیبهشت ۱۳۹۹، ۱۰:۲۲

دوره الفبای برنامه نویسی با هدف انتخاب زبان برنامه نویسی مناسب برای شما و پاسخگویی به سوالات متداول در شروع یادگیری موقتا رایگان شد: