ما توی زبانهای مثل Cpp برامون اعداد اسکی خیلی مهم بود میتونستیم باهاشون خیلی کارها بکنیم . مثلا توی cast کردن دادهها حتی میتونست خودش رو نشون بده . خواستم ببینم ما اینجا نوع داده تک کارکتری نداریم ؟ یا اساس نمیتونیم با تابعی غیر از خود ascii و صرفا با تبدیل نوع داده مقدار عددی '2' یا 'a' یا ... هر چیز یا عمل دیگه رو به دست بیاریم ؟
ایا برعکس این عمل میتونه باشه ...؟
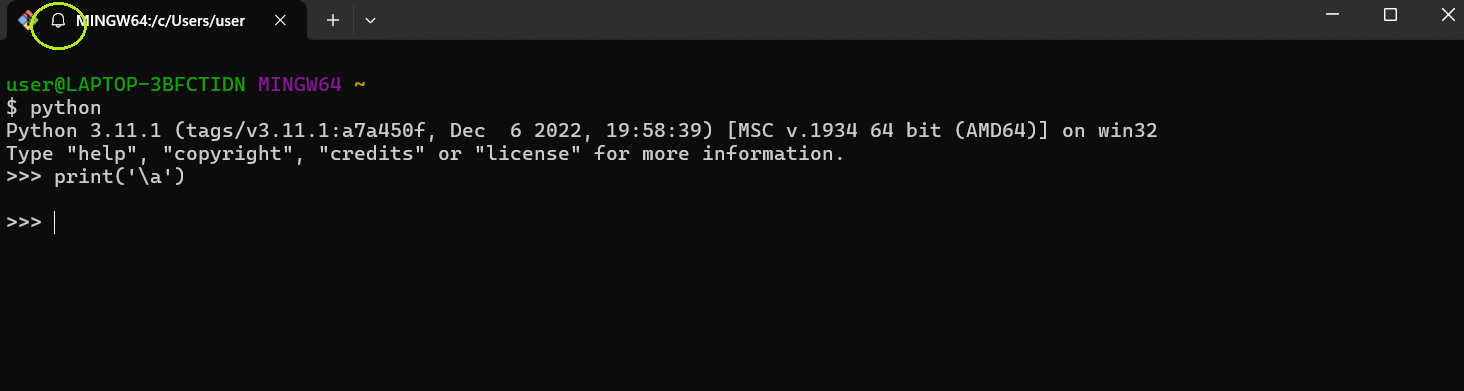
مثلا یکی از اعداد اسکی نقش بیپ داشت برای برنامه ! یعنی وقتی اون رو توی رشته میاوردیم یا اون رو پیرینت میکردیم آلارم ویندوز فعال میشد و صدا میداد . الان نمیتونیم مثلا فلان عدد اسکی رو دیگه توی پایتون پیرینت کنیم یا چیزی از این جنس ؟