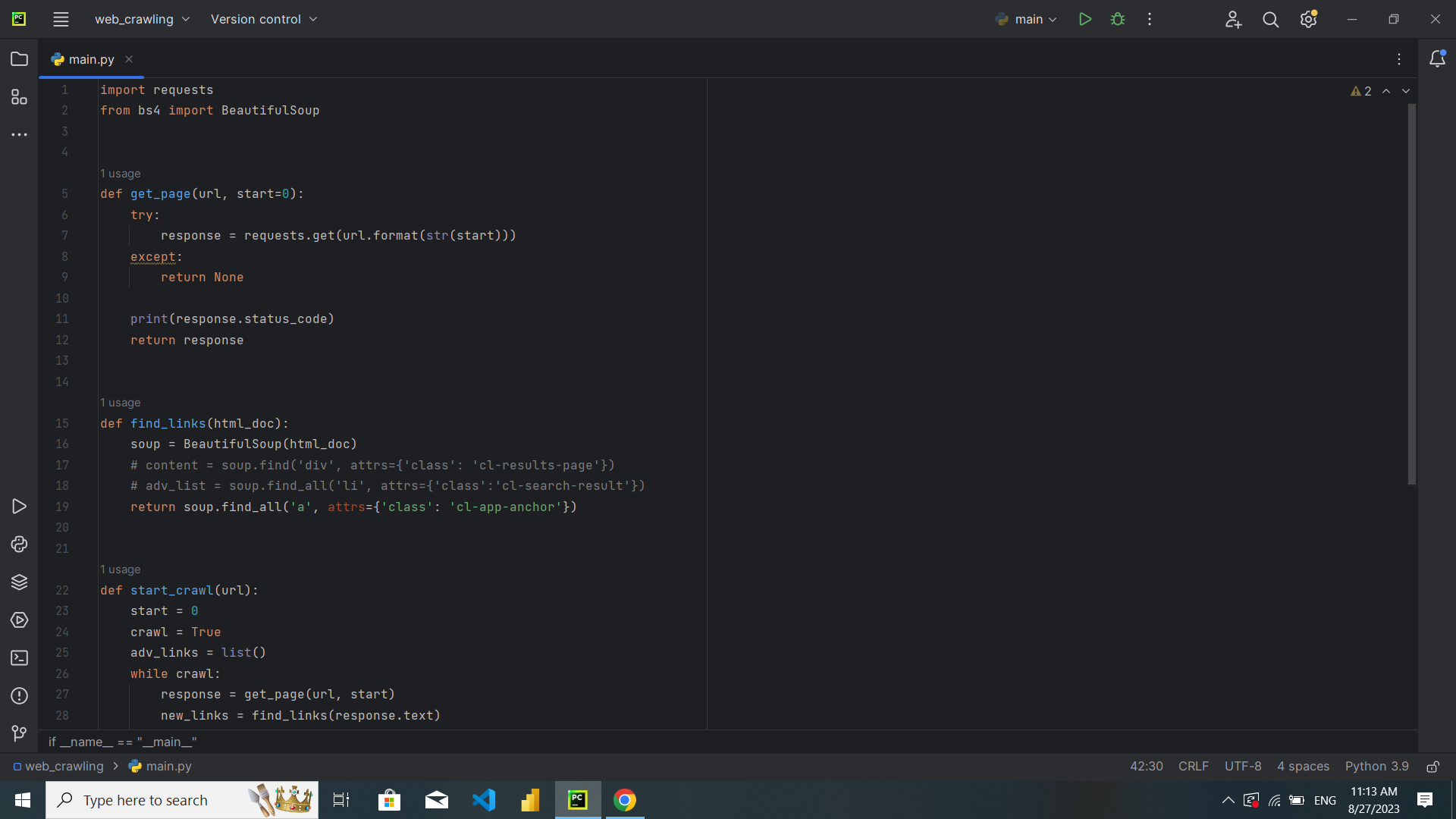
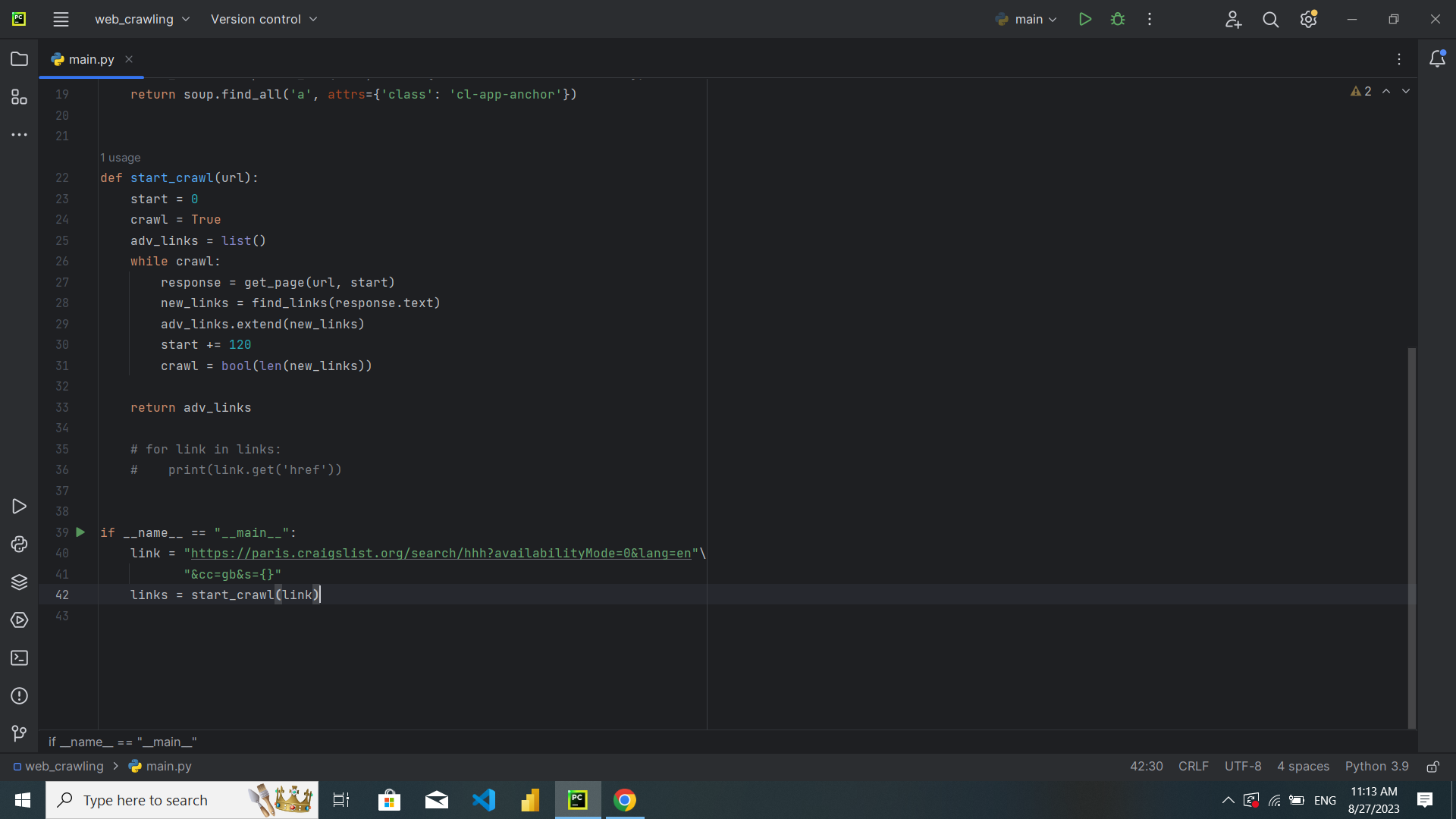
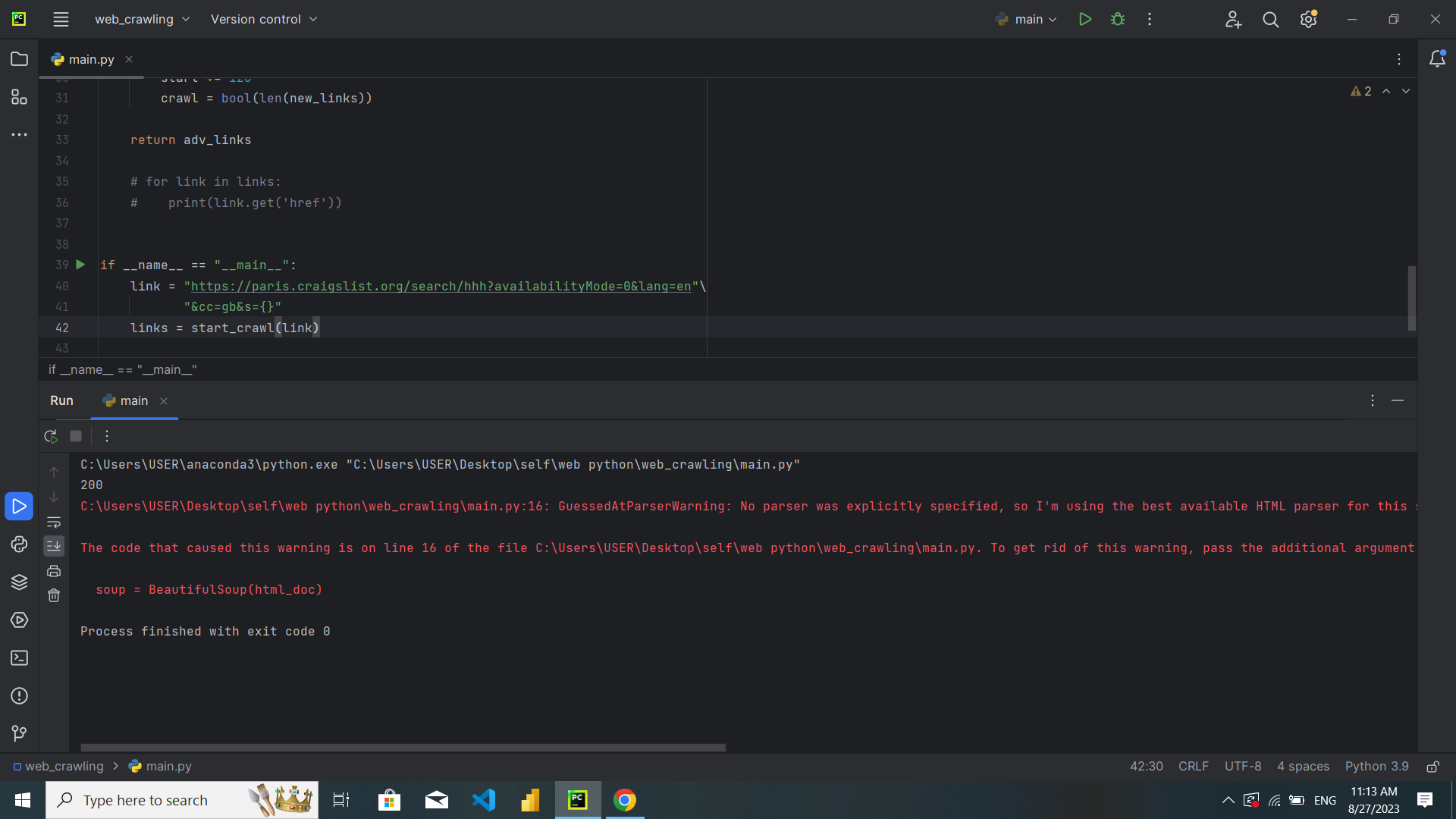
سلام کد من خروجیای بهم نمیده. سرچ و اینا زدم ولی نفهیمدم مشکلش چیه.
قبل از اینکه تو خط 19، اسم کلاس رو بدم لینک برمیگردوند. ولی از اونحا به بعد لینکی چاپ نمیکنه. تابع start_crwal هم خروجی نمیده.

 ایجاد شده در ۰۵ شهریور ۱۴۰۲
ایجاد شده در ۰۵ شهریور ۱۴۰۲
سلام کد من خروجیای بهم نمیده. سرچ و اینا زدم ولی نفهیمدم مشکلش چیه.
قبل از اینکه تو خط 19، اسم کلاس رو بدم لینک برمیگردوند. ولی از اونحا به بعد لینکی چاپ نمیکنه. تابع start_crwal هم خروجی نمیده.
