ایجاد شده در ۲۶ مرداد ۱۴۰۲
ایجاد شده در ۲۶ مرداد ۱۴۰۲
سلام وقت بخیر
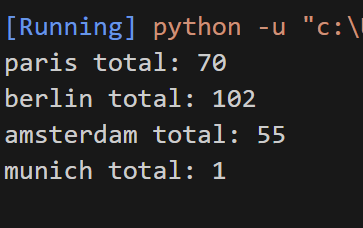
موقعی که این اسکریپت رو ران میکنم total رو به من صفر میده.
وقتی کدهای html شهرهای دیگه رو چک کردم دیدم class : hdrlnk که استاد تو قسمت find_link اسکریپتشون استفاده کردن رو فقط شهر پاریس داره و شهرهای دیگه ای که برای کرول استفاده کردن این کلاس رو نداشتن.
سعی کرد هر شهر رو جداگانه کرول کنم با استفاده کلاسهای های خودشون ولی باز هم total رو صفر میداد بجز پاریس که خروجیش درست بود