۲
دیدگاه
نظر

آشنایی با دیتابیسهای Document-based در NoSQL ها
سرفصلهای مقاله
- دیتابیس مبتنی بر سند چیست
- نتیجه گیری
اگر قبلا با دیتابیسهای NoSQL آشنا شده باشید، حتما نام دیتابیسهای مبتنی بر سند یا Document Based Database را شنیده اید. دیتابیسهای مبتنی بر سند نوعی از دیتابیسهای NoSQL هستند. اگر علاقه مندید در مورد دیتابیسهای NoSQL بیشتر بدانید ما این مقاله را برای شما نوشته ایم تا به شما بگویم دیتابیس Document-based چیست؟
دیتابیس مبتنی بر سند چیست
در یک سیستم دیتابیس رابطه ای یا RDBMS، قبل از اضافه کردن هرگونه داده ای به دیتابیس، باید ابتدا اسکیما (Schema) دیتابیس را تعریف کنید. اسکیما ساختاری است که در قالب یک زبان رسمی که توسط دیتابیس پشتیبانی میشود تعریف شده است. این ساختار طرح جداول دیتابیس و روابط یا Relationهای بین جداول حاوی اطلاعات را مشخص میکند. برای ایجاد طرح یک جدول نیاز دارید قرارداد هایی را در قالب ستونهای نام گذاری شده که مشخصات هر موجودیت یا Entity هستند و همینطور نوع داده ای که میتواند در هرکدام از این ستونها ذخیره شود را به طور کامل تعریف کنید.
در مقابل، یک دیتابیس Document-based حاوی مجموعه ای از اسناد یا داکیومنتها است. این داکیومنتها رکورد هایی هستند که علاوه بر معرفی نوع اطلاعاتی که سند محتوی آن هاست، شامل اطلاعات اصلی رکورد یا سند نیز هست. پیچیدگی این داکیومنتها بستگی به انتخاب شما دارد. میتوانید اطلاعات را به صورت Nest شده یا تودرتو در آن قرار دهید تا بتوانید زیر دسته هایی از اطلاعات اضافی در مورد آبجکت رکورد در آن داشته باشید. درست همانطور که در زبان JSON و XML میتوانید (دیتابیسهای مبتنی بر سند بر اساس این زبانها تولید میشوند). شما همچنین میتوانید از تعداد داکیومنتهای بیشتری برای نمایش آبجکت اطلاعات خود استفاده کنید. در شکل زیر یک جدول سنتی رابطه ای با نمونه مشابه مبتنی بر سند خود مقایسه شده است:
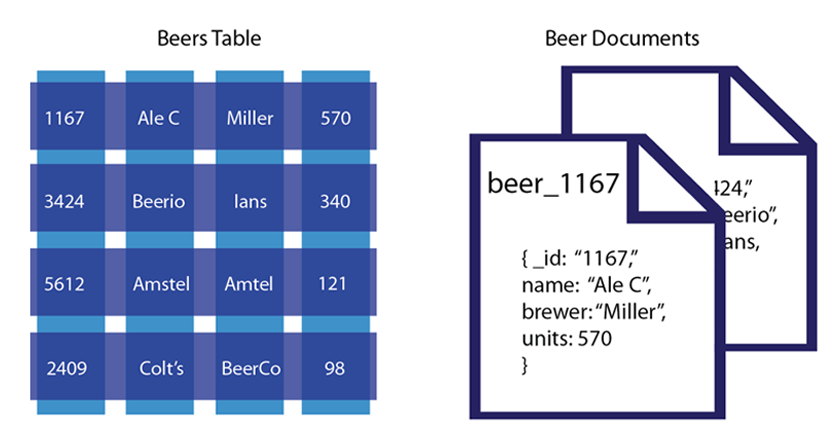
در این مثال جدولی شامل کالاها و مشخصات آنها داریم. این مشخصات شامل: id، نام کالا، تولیدکننده، تعداد موجودی و غیره است. همانطور که در این شکل مشاهده میکنیم مدل رابطه ای جدولی از یک اسکیمای از پیش تعیین شده با تعداد فیلدهای مشخص که از انواع داده ای مشخصی هستند پیروی میکند. اما همتای آن که از مدل دیتابیس مبتنی بر سند پیروی میکند، به ازای هر کالا یک داکیومنت دارد. هر داکیومنت شامل یک سری اطلاعات مشخص و هم نوع به ازای هر کالا است.
بیشتر بخوانید: پایگاه داده چیست؟در یک مدل مبتنی بر سند، آبجکتهای اطلاعات در داخل داکیومنت هایی ذخیره میشوند. هر داکیومنت حاوی یک آبجکت اطلاعات است (مثلا در اینجا به ازای هر کالا یک داکیومنت داریم) و شما را قادر میسازد بتوانید از طریق ویرایش این داکیومنتها به ویرایش، یا حذف اطلاعات دیتابیس خود بپردازید. در این مدل به جای استفاده از ستونهای نام گذاری شده با انواع مشخص، نام اطلاعات را در داکیومنت مشخص کرده و مقدارشان را رو به روی نام آنها مینویسیم.
اگر قصد داشتیم در یک مدل دیتابیس رابطه ای صفات یا attributeهای جدیدی را به هر کالا اختصاص دهیم مجبور بودیم اسکیما یا طرح کلی دیتابیس را برای اضافه کردن ستونهای جدید و نوع داده ای آنها تغییر دهیم. اما در مورد مدل مبتنی بر سند، کافی بود جفتهای کلید-مقدار (Key-Value) اضافی را به اسناد اضافه کنیم تا نمایانگر فیلدها یا attributeهای جدید باشند.
مشخصه دیگر دیتابیسهای مبتنی بر سند در نرمال سازی دادههای جدولی است. این به آن معنی است که شما اطلاعات را به جداول کوچکتری که با هم Relation دارند بشکنید. شکل زیر این کار را در مدل دیتابیس رابطه ای نمایش میدهد:
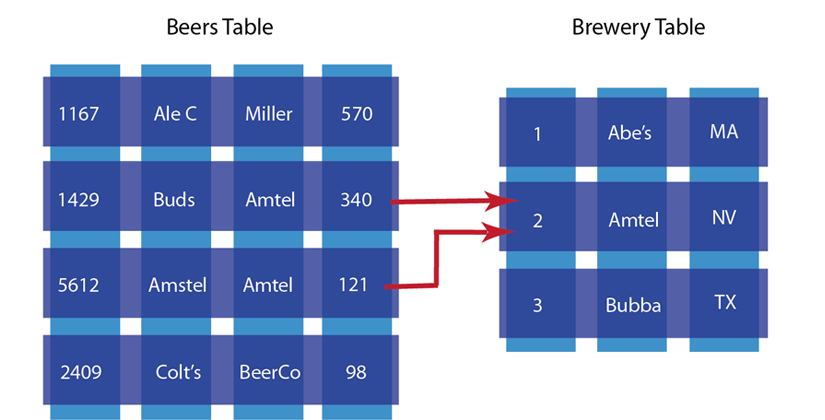
در مدل دیتابیس رابطه ای اطلاعات در جداول کوچکتر متعدد شکسته و نگهداری میشوند. مزیت این روش پرهیز از تکرار دادهها در جداول است. اگر ما اطلاعات تولیدکنندگان و کالاها را در دو جدول نشکسته و به جای آن همه اطلاعات را در جدول کالاها ذخیره میکردیم مجبور بودیم اطلاعات حجیم تکراری در مورد تولیدکننده هر کالا را در رکورد مربوط به آن کالا تکرار کنیم.
مشکل این روش آن است که زمانی که اطلاعات جداول متصل به هم را تغییر میدهید نیاز دارید که آن جداول را به طور همزمان قفل کنید تا مطمئن شوید اطلاعات آن جداول به طور درست و غیر متناقض تغییر پیدا میکنند. با این روش تغییر در ساختار دیتابیس در مرحله Production نرم افزار بسیار مشکلتر است چرا که شما در حال انتشار اطلاعات در یک ساختار محکم و سفت و سخت هستید. همینطور در صورت Scale شدن سیستم به صورت افقی، تقسیم کردن اطلاعات در سرورهای متعدد نیز کار مشکلی است. برای آشنایی با Scale کردن افقی میتوانید از مقاله Horizontal Scaling چیست استفاده کنید.
اما در دیتابیسهای مبتنی بر سند میتوانیم انتخاب کنیم که دو نوع داکیومنت داشته باشیم: یک نوع برای کالاها و یک نوع برای تولیدکنندگان. با این کار به جای تقسیم آبجکتها به سطرها و ستونها آنها را به داکیومنتها یا اسناد تبدیل کرده ایم. با ایجاد یک اشاره گر به داکیومنت تولیدکننده، در داکیومنت کالا به راحتی یک رابطه یا Relation را بین دو موجودیت برقرار کرده ایم:
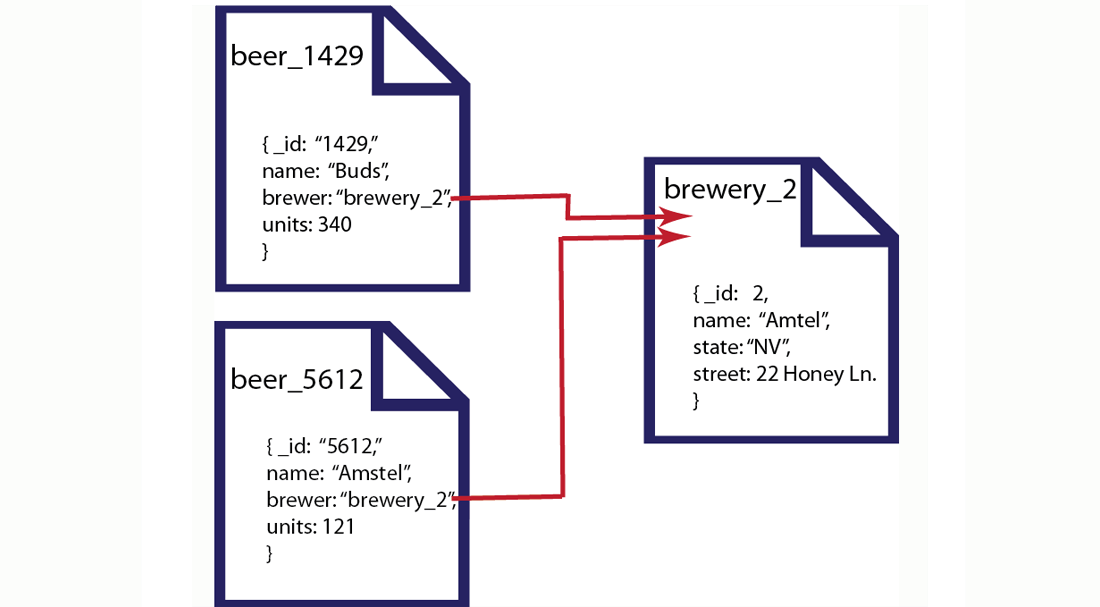
نتیجه گیری
در این مثال، همانطور که مشاهده کردید مزایای متعدد روش مبتنی بر سند را نسبت به روش سنتی دیتابیسهای رابطه ای یا RDBMSها برشمردیم. در اولین مورد گفتیم به این دلیل که اطلاعات در داکیومنتها ذخیره میشوند، برای تغییر ساختار یا اسکیما، کافی است داکیومنتهای مربوط به آبجکت مورد نظرمان را ویرایش کنیم. این کار احتیاجی به Down کردن سیستم ندارد و میتواند به راحتی در زمان فعالیت اپلیکیشن انجام پذیرد. دوم اینکه، با این روش به راحتی میتوانیم اطلاعات را در چندین سرور توزیع کنیم. در واقع مقیاس پذیری افقی از صفات ذاتی دیتابیسهای NoSQL است که دیتابیسهای مبتنی بر سند از انواع آن هاست. ضمنا به دلیل اینکه هر رکورد اطلاعات در کل یک داکیومنت ذخیره شده است، جا به جایی و تکثیر یکجای هر آبجکت اطلاعات به سرورهای دیگر راحتتر است.
مقالات مرتبط
۲ دیدگاه
محمد نقلانی
۰۲ مرداد ۱۳۹۸، ۰۵:۲۷
مهدی علامه
۰۲ مرداد ۱۳۹۸، ۰۵:۳۹

دوره الفبای برنامه نویسی با هدف انتخاب زبان برنامه نویسی مناسب برای شما و پاسخگویی به سوالات متداول در شروع یادگیری موقتا رایگان شد: